PointPillars解读
论文: PointPillars: Fast Encoders for Object Detection from Point Clouds
代码: https://github.com/nutonomy/second.pytorch
0 简介
介绍PointPillars之前, 先简要介绍一下voxel-based检测方法的发展历程。VoxelNet是第一个将点云转换为体素(voxel)进行3D目标检测的, 但是由于3D卷积的使用, 性能非常低。 SECOND主要把3D卷积换成了更高效的稀疏卷积, 并且增加了一些数据增强, 在性能上有比较大的提升。 虽然使用了稀疏卷积, 但3D的卷积依然比较耗费资源, PointPillar则是把点云转换为2D的伪图像, 在2D图像上进行检测, 大大提升了检测的性能。
1 PointPillar网络
整体思路就是3D转2D, 在2D伪图像上进行目标检测。 网络主要包含3个部分: 1) Pillar Feature Network; 2) Backbone(2D CNN) 3) detection head(SSD)

1.1 Pillar Feature Network
该部分网络的主要作用是把3D点云转换为2D的伪图像。 具体做法是: 在原始点云上进行pillar的划分。 跟voxelNet的voxel划分不同, voxel是在3维上进行划分, 而pillar的划分只在2维度上, 相当于高度这个维度上只划分了1个voxel。 因此voxel的数量也大大降低, 且维度上也减少了1维,可以转换为2D的伪图像。
举个具体的例子更容易理解, 假设使用一个深度、高度、宽度分别为D,H,W的立方体去表示点云,每个体素的深度、高度、宽度分别为 v D v_D vD, v H v_H vH, v W v_W vW, 那么按voxel的划分方式, 会划分出 D v D ∗ H v H ∗ W v w \frac{D}{v_D}*\frac{H}{v_H}*\frac{W}{v_w} vDD∗vHH∗vwW 个voxel, 而PointPillar会划分出 D v D ∗ W v w \frac{D}{v_D}*\frac{W}{v_w} vDD∗vwW 个pillar.
划分完之后有P个非空的pillar, 每个pillar中包含N个点云数据(有采样操作, 对多于N个的进行采样到N个,对不足N个的进行0填充),对每个点提取D维的特征, 在PointPillar中, D=9, 提取的特征包括 (x,y,z,r, x c x_c xc, y c y_c yc, z c z_c zc, x p x_p xp, y p y_p yp), 其中x,y,z是这个点的3维坐标, r是反射强度, x c x_c xc, y c y_c yc, z c z_c zc 是距离pillar内点云中心的距离, x p x_p xp, y p y_p yp 表示这个点与pillar的几何中心的偏移。
经过pillar划分, 以及初步的特征提取之后, 就获得了DxPxN 的特征向量,然后经过PointNet进行特征提取,得到CxP的特征向量, 最后把CxP的转换成CxHxW的伪图像。
转换为2D伪图像这个思想是PointPillar的最大亮点。 通过这一转换直接在2D上进行检测, 不仅大大提升了检测速度, 还能很方便复用2D检测的一些技术。
1.2 Backbone(2D CNN)
Backbone部分采用常规的卷积网络, 包含一个自上而下的特征的提取模块和一些自下而上的特征融合模块, 这在2D图像特征提取中是常规操作。
1.3 detection head(SSD)
在提取好的特征上, 用SSD的检测头进行分类和边框回归。 注意计算box与groud truth的IOU使用的是2D信息, 即只有深度和宽度, box的高度和海拔作为需要回归的量。
2 实验结果
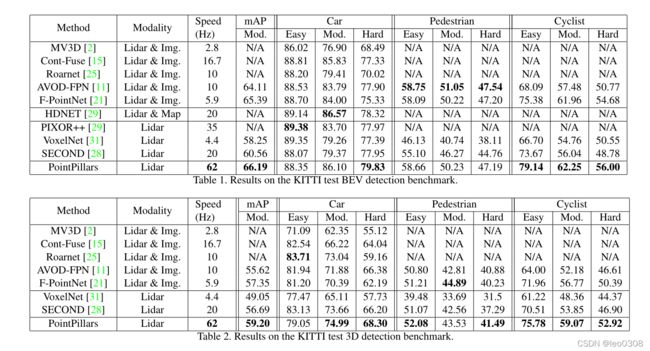
可以看到, 相比VoxelNet和SECOND, 不仅速度上大大提升, 精度上也有提升。
附: 这篇博客对代码进行了详细的解析, 对理解很有帮助, 值得看看。
PointPillars论文解析和OpenPCDet代码解析