AlexNet 理论以及使用pytorch代码实现
AlenNet 理论及代码实现
理论部分

关键字: 1.2million 张图片,1000个类别,有60百万个参数,65000个神经元,5个卷积层,三个全连接层,双GPU进行计算.


这一部分主要大概说明了一下行业发展,以及文章的概况。

主要说明了作者把数据集统一成了256x256的RGB 图像

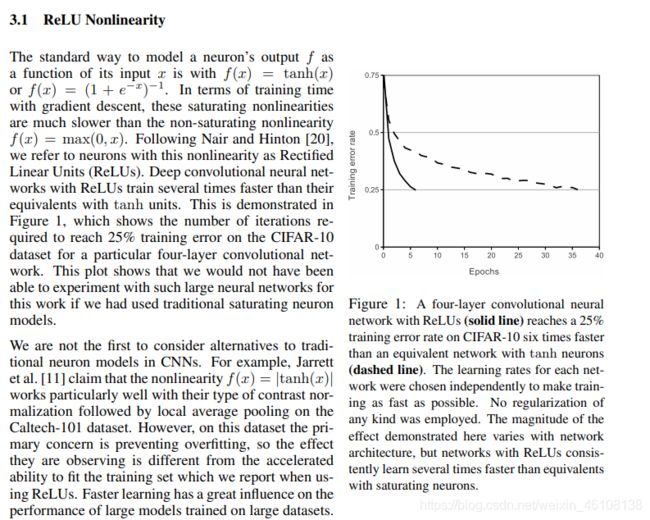
3.1主要讲到将ReLU 激活函数运用到网络当中去,以及ReLU激活函数的一些优点。关于ReLU的更多描述可以参考这篇文章

3.2主要讲了双GPU运算。

局部响应归一化

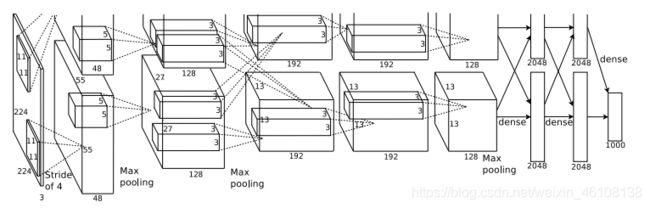


代码实现部分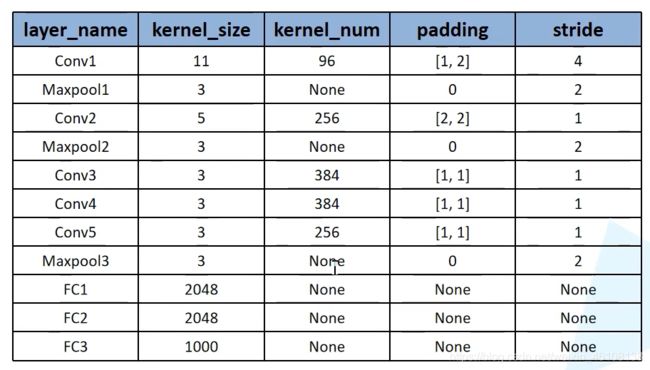
代码实现
- model.py
import torch.nn as nn
import torch
class AlexNet(nn.Module):#定义一个继承自nn.Module 的子类
# nn.Module Base class for all neural network modules.
def __init__(self, num_classes=2, init_weights=False):
#通过初始化函数定义网络在正向传播过程中需要用到的层结构
super(AlexNet, self).__init__()
#与前两不同的是 使用nn.Sequential() 打包代码 将一系类层结构进行打包
#定义features 结构 专门用来提取图像的特征
self.features = nn.Sequential(
#第一次 卷积核大小为11 步长为4 深度为3 卷积核个数为48 (为了提高速度,与原论文相比减少一半
#padding=2 左右,上下补上两行0
#通过计算得到的 特征图为一个小数 pytorch 会自动修改padding
#卷积后得到的不为整数pytorch 将自动修改padding
# input(2,224,224) output(48, 55, 55]
nn.Conv2d(3, 48, kernel_size=11, stride=4, padding=2), # input[3, 224, 224] output[48, 55, 55]
#卷积后经过 ReLu 激活 inplace =True 可增加计算量,减少内存占用
nn.ReLU(inplace=True),
#卷积核 3 步长2
nn.MaxPool2d(kernel_size=3, stride=2), # output[48, 27, 27]
nn.Conv2d(48, 128, kernel_size=5, padding=2), # output[128, 27, 27]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 13, 13]
nn.Conv2d(128, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 192, kernel_size=3, padding=1), # output[192, 13, 13]
nn.ReLU(inplace=True),
nn.Conv2d(192, 128, kernel_size=3, padding=1), # output[128, 13, 13]
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # output[128, 6, 6]
)
#定义classifier结构 作全连接层
self.classifier = nn.Sequential(
#通过Dropout 方法 使节点按照一定的比例失活 防止过拟合 一般放在全连接与全连接层之间
nn.Dropout(p=0.5),#50%失活神经元 默认为0.5
nn.Linear(128 * 6 * 6, 2048),#输入为上一层的输出 (输入,输出)
nn.ReLU(inplace=True),#ReLu 激活
nn.Dropout(p=0.5),#全连接1 和全连接2 之间 随机失活
nn.Linear(2048, 2048),
nn.ReLU(inplace=True),
nn.Linear(2048, num_classes),#输出为 数据集的类别的个数
)
#初始化权重函数
if init_weights:
self._initialize_weights()
#正向传播函数
def forward(self, x):
x = self.features(x)
#得到特征图后进行展平处理
#从chanal 高度,宽度 展品
#pytorch 通道排列顺序 banch chanal 高 宽
#第一维度banch 一般无需处理
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
#初始化权重
#pytorch 会自动采用下列方法初始化,实际使用过程中无需使用下列初始化
def _initialize_weights(self):
for m in self.modules():#遍历modules 中的每一个结构
if isinstance(m, nn.Conv2d): #如果层结构为 nn.Conv2d
#对卷积权重w进行初始化
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
#如果偏置不为空,使用0 对其初始化
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
#如果是全连接层,通过正态分布初始化权重 平均值为 0 方差为0.01
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
- train.py
import os
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm
from model import AlexNet
def main():
#指定使用设备
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("using {} device.".format(device))
#数据预处理函数
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),#随机裁剪
transforms.RandomHorizontalFlip(),#随机翻转
transforms.ToTensor(),#转化为tensor
#标准化处理
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}
# .. 表示返回上一层目录
#data_root = os.path.abspath(os.path.join(os.getcwd(), "../..")) # get data root path
# data_root 当前项目位置的前一个目录
data_root = os.path.abspath(os.path.join(os.getcwd(), ".."))
#image_path = os.path.join(data_root, "data_set", "flower_data") # flower data set path
#图片的位置
image_path = os.path.join(data_root, "dog_cat")
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
#断言函数是对表达式布尔值的判断,要求表达式计算值必须为真。可用于自动调试。
#如果表达式为假,触发异常;如果表达式为真,不执行任何操作。
#训练集所在的位置,并且将训练集的图片进行处理
#ImageFolder假设所有的文件按文件夹保存好,
# 每个文件夹下面存贮同一类别的图片,文件夹的名字为分类的名字。
#train 文件夹下的 图片进行处理
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"),
transform=data_transform["train"])
train_num = len(train_dataset)
# {'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}
#{'cat':0,'dog':1}
flower_list = train_dataset.class_to_idx
#将键值和index 反过来
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=2)
#通过json 将索引与类别对应起
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
#batch_size 每次获取32张图片进行训练
batch_size = 32
#number workers 加载训练数据所使用的线程数,在win 中不能设置为非0
#0表示使用主线程训练
nw = min([os.cpu_count(), batch_size if batch_size > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
train_loader = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size, shuffle=True,
num_workers=nw)
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "test"),
transform=data_transform["val"])
val_num = len(validate_dataset)
validate_loader = torch.utils.data.DataLoader(validate_dataset,
batch_size=4, shuffle=False,
num_workers=nw)
print("using {} images for training, {} images fot validation.".format(train_num,
val_num))
# test_data_iter = iter(validate_loader)
# test_image, test_label = test_data_iter.next()
#
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))
# plt.show()
#
# print(' '.join('%5s' % cla_dict[test_label[j].item()] for j in range(4)))
# imshow(utils.make_grid(test_image))
net = AlexNet(num_classes=2, init_weights=True)
net.to(device)
loss_function = nn.CrossEntropyLoss()
# pata = list(net.parameters())
#定义一个优化器
optimizer = optim.Adam(net.parameters(), lr=0.0002)
epochs = 10
save_path = './AlexNet.pth'
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
# train
#使用net.train()就会启用dropout 方法
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader)
#遍历数据集
for step, data in enumerate(train_bar):
images, labels = data
#清空之前的梯度信息
optimizer.zero_grad()
#正向传播
outputs = net(images.to(device))
loss = loss_function(outputs, labels.to(device))
#反向传播到每一个节点当中
loss.backward()
#更新节点参数
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1,
epochs,
loss)
# validate
#关闭drop_oup 方法
#利用测试集 对训练的结果的准确率计算
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, colour='green')
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net.state_dict(), save_path)
print('Finished Training')
if __name__ == '__main__':
main()
- predict.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import AlexNet
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# load image
img_path = "D:\python\CV_practice\\122.jpg"
assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = 'D:\python\CV_practice\AlxNet_torch\class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model
model = AlexNet(num_classes=2).to(device)
# load model weights
weights_path = "D:\python\CV_practice\AlxNet_torch\AlexNet.pth"
assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)
model.load_state_dict(torch.load(weights_path))
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],
predict[predict_cla].numpy())
plt.title(print_res)
print(print_res)
plt.show()
if __name__ == '__main__':
main()
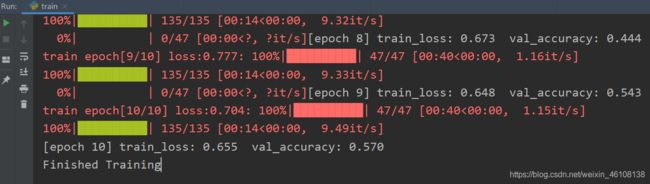
最终训练的准确率为 0.57
经过多次调参准确率达到72%
更详细的可以参考文章