【论文笔记】GeDi:Generative Discriminator Guided Sequence Generation
GeDi: Generative Discriminator Guided Sequence Generation

文章目录
- GeDi: Generative Discriminator Guided Sequence Generation
-
- Abstract
- Motivation
- Main idea and Framework
-
- Class-Conditional Language modeling
- GeDi
- Muti-topic GeDi
- Experiment results and Enalysis
-
- Controlling sentiment of generations from book prompts
- Detoxifying GPT-2 and GPT-3
- Extending GeDi to the multi-class setting
- Conclusion
任务:可控文本生成
会议:EMNLP 2021 Findings
原文:链接
源码:链接
Abstract
本文提出了一个高效的GeDi模型,在每个时间步,该模型通过在两个条件类分布(控制码和反控制码)上通过贝叶斯规则进行正则化来计算所有下一个可能单词的分类概率,进而引导文本生成。
- GeDi提供了比先前的可控文本生成方法更好的可控性和更快的生成速度;
- 除此之外,本文还展示了GeDi可以使GPT-2和GPT-3在不明显牺牲生成速度,保持语义流畅度的同时,显著地减少生成的毒性;
- 最后,本文展示了仅在三个话题上训练的GeDi可以在一个新的话题实现zero-shot,通过关键词上生成该新话题上的可控文本。
Motivation
大规模预训练语言模型通过学习训练数据集的分布以生成逼真的文本,然而,在训练过程中简单地模拟数据地分布有许多缺点,因为从网络上爬取地大规模文本训练集,其中充斥着毒性、偏见和错误信息。控制生成的方法相对于在这类数据上训练的LM更安全、更有利于下游应用。
现有的控制语言模型生成自然语言的方法存在许多限制。
- 类条件语言模型(CC-LMs),例如CTRL,尝试通过以控制码为条件来控制文本生成。控制码是一个表征了数据源的属性变量。但是,使用特定的控制代码减少了提示之间的样本多样性,因为样本通常与控制代码的数据源相似。(这里应该意指跨域的属性可控)
- 另一种方法是使用判别器来引导解码以控制语言模型,现存的使用该方法的模型,如Weighted decoding和PPLM都十分耗费算力。
- GeDi的动机是使用生成式判别器对所有候选单词进行两次并行的前向传播以高效地计算 P θ ( c ∣ x t , x < t ) P_θ(c| x_t,x_{
Main idea and Framework
Class-Conditional Language modeling
-
使用类条件语言模型(class-conditional LMs)来作为生成式判别器(GeDis),引导生成具有期望属性的语言。在生成过程中,通过贝叶斯法则,使用GeDis计算所有候选的下一个单词的分类似然,在相同规模大小的场景下比使用标准的判别器节省了千倍算力。GeDi具有345M参数。
-
除了类条件生成,CC-LMs可以通过贝叶斯法则被用来作为生成式分类器 P θ ( c ∣ x 1 : T ) ∝ P ( c ) P θ ( x 1 : T ∣ c ) P_θ(c|x_{1:T})∝P(c)P_θ(x_{1:T}|c) Pθ(c∣x1:T)∝P(c)Pθ(x1:T∣c),CTRL使用这一方法来寻找序列的源属性。
GeDi
- 传统的判别器引导的可控文本生成
一个属性判别器可以用引导语言模型的解码。例如,给定上下文 x < t x_{
P w ( x t ∣ x < t , c ) ∝ P L M ( x t ∣ x < t ) P θ ( c ∣ x t , x < t ) ω ( 4 ) Pw(x_t|x_{
其中, ω > 1 ω>1 ω>1用来放大判别器偏差,使生成更倾向于期望地属性。将这一方式用于指导解码,如下图所示,对于标准的判别器来说是非常低效的;使用带有判别器头的语言模型,例如BERT、GPT来计算 P θ ( c ∣ x t , x < t ) P_θ(c|x_t,x_{
- GeDi(生成式判别器)引导的文本生成
GeDi假设有一个CC-LM、期望属性控制码 c c c,反控制码 c ‾ \overline c c,使用由CC-LM得到的差异 P θ ( x 1 : t ∣ c ) 、 P θ ( x 1 : t ∣ c ‾ ) P_θ(x_{1:t}|c)、P_θ(x_{1:t}|{\overline c}) Pθ(x1:t∣c)、Pθ(x1:t∣c),来引导从一个语言模型 P L M ( x 1 : t ) P_{LM}(x_{1:t}) PLM(x1:t)中采样。
-
具体来说,GeDi使用这个差异来计算每个候选的下一个单词属于期望属性的概率分布 P θ ( c ∣ x t , x < t ) P_θ(c|x_t,x_{

-
这种内在的基于 c c c和 c ‾ \overline c c的差异预测,导致它们之间共有的属性被取消,更有效地允许由 c c c描述的属性跨域迁移。
例如,如果 P θ ( x 1 : t ∣ c ) P_θ (x_{1:t}|c) Pθ(x1:t∣c)捕捉到正面影评的分布,而 P θ ( x 1 : t ∣ c ‾ ) P_θ (x_{1:t}|\overline c) Pθ(x1:t∣c)捕捉到负面影评的分布,对比这两个分布将抵消针对影评的预测,可以更好地推广正面和负面的概念。如果在电影评论上训练一个类条件语言模型进行情感控制,其直接的类条件预测将偏向于预测电影评论词(如图所示,以"cinematic"的下一个词预测为例进行说明)。然而,通过贝叶斯法则对比一对反控制代码的预测,可以消除对电影评论的偏见。

-
在实际应用中,将公式( 5 )应用于长序列生成通常会导致在给所有候选下一个单词分配分类概率为1或0的序列中出现差的校准分布,从而无法提供有用的信号。解决此问题的方法是利用当前的序列长度 t t t对概率进行正则化。如公式6所示,其中,类先验概率 P ( c ) P(c) P(c)可以约去,因为使用平衡类进行训练。
(校准分布差是指给一个token分配了1概率,其余全为0?根据函数图像,幂函数,开t根号次方约束,t越大越趋向于1,使函数变得平缓?)

-
除此之外,本文还应用了启发式过滤算法,该算法将一部分具有较低 P θ ( c ∣ x 1 : t ) P_θ (c|x_{1:t}) Pθ(c∣x1:t)的下一个单词分布置零。如公式7所示,该算法类似于top-p采样, ( 1 − ρ ) (1-ρ) (1−ρ)是一个阈值,该算法即选取 P θ ( c ∣ x t , x < t ) P_θ(c|x_t, x_{


Muti-topic GeDi
为了拓展GeDi到多类别设置,本文提出将每个分类任务重新设置为二分类任务,对每个类使用控制码和反控制码。对于四个主题使用
训练时,模型能看到等价的正样本对和随机选取的负样本对。
训练后,应用GeDi引导的使用 c = < t r u e > 、 c ‾ = < f a l s e > c=
(这里用公式6,怎么实现的?是个分类任务吗?CC-LM是个语言模型,我的理解是把前t-1个词输入,最后一个词作为预测,根据公式6,最后一个词的概率即为样本符合主题,即c的概率。)

Experiment results and Enalysis
本文使用GeDi引导的解码器在情感、去毒、话题控制上进行实验。其中,CC-LM:针对每个任务设置控制码,然后使用GPT2-medium微调,作为CC-LMs。使用这些CC-LMs作为GeDis来引导GPT-XL和GPT-3的生成。解码策略使用带有重复惩罚机制的贪婪解码(CTRL论文中提出的)和top-p采样。
Controlling sentiment of generations from book prompts
CC-LM:GPT2-medium在IMDB movie review上微调。生成器:GPT-2。实验结果发现,虽然CC-LMs可以直接生成有效控制电影评论情感的文本,但是难以泛化到域外提示,通常会将提示转化到电影评论。反之,使用相同的CC-LMs引导GPT-2生成可以在广泛多样的话题上实现高效的情感控制。
为验证GeDi引导的解码可以在训练域之上较好地泛化出“正向“和“负面”情感的概念,本文对一个模型从Bookcorpus的图书章节开始有条件生成文本的任务进行评估。
实验结果如下图所示。CTRL在这个场景中很难控制语气/情感,因为它的情感训练域是亚马逊评论。直接从作为GeDi的CC-LMs中生成的文本不是”类书本“风格的因为他们的训练域是电影评论。人工评估表明,27 %的CTRL样本与亚马逊评论相似,61 %的CC-LM样本与电影评论相似。这是CTRL风格生成的一个关键缺陷-模型只能在控制代码对应的训练域内可靠地生成文本和控制属性。判别器引导的生成模型PPLM和GeDi都实现了较好的情感控制和”类书“风格跨域控制能力,但是Gedi-guided却更加高效、速度更快。

Detoxifying GPT-2 and GPT-3
在Jigsaw评论数据集上训练一个CC-LM,控制码使用“dirty”和”clean“。评估以RealToxicityPrompts为条件。GeDi引导的GPT-2、GPT-3相比PPLM具有显著更强的解毒能力。
Extending GeDi to the multi-class setting
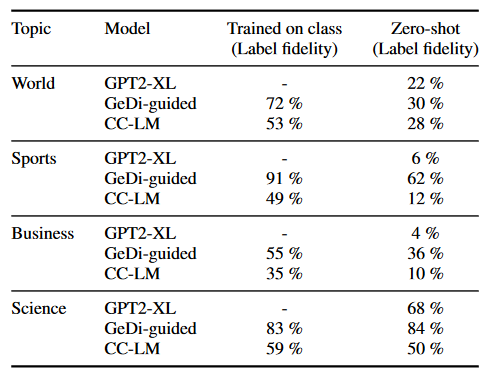
为了验证GeDi-guide的话题零样本生成能力,本文在四个话题(World, Sports, Business, and Science/Tech)上训练了四个CC-LMs,每个CC-LM由三个话题进行训练,另一个话题进行零样本预测。使用RoBERTa评估话题相关性。实验结果表明,显然,GeDi引导的文本生成具有较强的零样本泛化能力,这种能力很可能是由于生成式分类器可以从学习到的词向量中对看不见的主题进行零样本分类。虽然GPT-3也可以通过诸如"写一篇关于体育的文章"这样的条件性提示零样本生成主题可控的文本,而使用GeDi的零样本生成不一定需要是一篇文章或者有任何来自提示的其他约束。
Conclusion
这篇文章的idea是使用生成式判别器来引导文本生成,生成式判别器(GeDis)和过去的使用判别器引导生成的方法的区别是,其使用一个类条件语言模型(CC-LMs),通过贝叶斯定理(全概率公式),计算期望属性控制码和反控制码的条件概率,来得到候选的下一个单词属于期望属性的概率分布。这一过程是并行的,所以推理速度快,也就是文中不断强调的高效。此外,作者做了大量的实验,验证了GeDi具有下列能力:
- 期望属性和反期望属性概率分布之间的差异,能够抵消领域差异,更显著强调属性,实现跨域的属性可控(这也是文中不断强调的),更强的情感控制能力;
- 多话题上的零样本生成能力,其实也是跨域迁移能力;
- 解毒GPT-2、GPT-3的能力;