三大聚类算法
在人工智能领域,主要有有监督学习,非监督学习,半监督学习,强化学习四大学习算法,这些算法之间的区别,本博客不进行阐述,感兴趣的可以百度一下相关的概念。目前,业界主要趋向于研究监督学习和非监督学习算法的开发。今天,我想主要介绍一下非监督的三大机器学习算法KMeans,层次聚类,DBSCAN,并配上相应实现代码。
聚类算法中最用的概念为簇,什么是簇。
什么是簇?
Clustering(簇):是将数据划分组的任务,这些组叫做簇。其目标是划分数据。最终达到的目的是:同一簇内的数据非常相似,不同簇内的数据非常不同。
1. K均值聚类

图1 KMeans聚类的过程
算法描述:
- .首先根据要划分类别数目,初始化聚类的中心(随机初始化);
- .然后计算每个数据点到各个聚类中心点的距离,选择距离最小的,并将该类别标记分配给该数据点,重复(2),知道所有点都分配完毕;
- .按照分配好的点重新计算数据点的中心,并重新所有点到新中心点距离;
- .重复(3),直达中心值不再变化。
K均值的问题
不能很好的处理非球的数据,看下图:
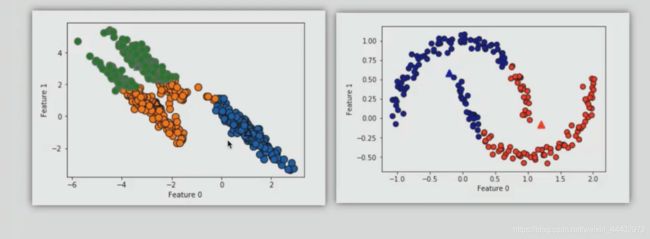
图3 利用KMeans算法对非球状数据聚类结果图
使用KMean算法进行聚类注意的细节
(1).要指定本次聚类中簇的个数;
(2).对球状数据聚类效果好;
(3).算法只考虑到到最近簇中心的距离;
(4).算法中心初始值具有随机性。
使用KMeans算法对sklearn里的make_blobs进行聚类
# -*- coding:utf-8 -*-
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# 导入数据
X,y = make_blobs(random_state=1)
print(X.shape)
print(y.shape)
plt.scatter(X[:,0],X[:,1])
kmeans = KMeans(n_clusters=3)
kmeans.fit(X)
# 输出分类标签
# print(kmeans.labels_)
y_pred = kmeans.predict(X)
print(y_pred)
# c:颜色序列
plt.scatter(X[:,0],X[:,1],c=y_pred)
# 绘制簇中心
# cmap = plt.cm.get_cmap("RdYlBu") 设置颜色
cluster_center = kmeans.cluster_centers_
plt.scatter(cluster_center[:,0],
cluster_center[:,1],
marker = '^',
linewidths = 4,
cmap = plt.cm.get_cmap("RdYlBu"))
plt.show()效果:

图4 Kmeans对make_blobs数据聚类结果
使用KMeans算法对sklearn里的make_moons数据进行聚类
# -*- coding:utf-8 -*-
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
# 导入月亮型数据(证明kmean不能很好对其进行聚类)
X,y = make_moons(n_samples=200,random_state=0,noise=0.05)
print(X.shape)
print(y.shape)
plt.scatter(X[:,0],X[:,1])
kmeans = KMeans(n_clusters=2)
kmeans.fit(X)
y_pred = kmeans.predict(X)
cluster_center = kmeans.cluster_centers_
plt.scatter(X[:,0],X[:,1],c=y_pred)
plt.scatter(cluster_center[:,0],cluster_center[:,1],marker='^',linewidth=4)
plt.show()效果:

图5 Kmeans对make_moons数据聚类结果
2. 凝聚聚类(层次聚类)
思想:将相同于原则的点聚在一起,利用方差之和最小来进行聚类,具体过程如下图6。

图6 层次聚类的过程
具体算法描述:
(1).首先默认每个点都是自己的簇,然后合并两个相似的簇,直到满足某种停止准则为止,比如停止准则是已经满足手动设定簇的个数,因此相似的簇合并,知道剩下指定个数的簇;
(2).用迭代的方式合并两个最近的簇,“最佳”的意思是簇的方差之和最小。
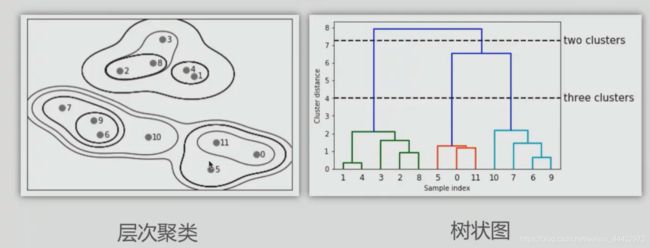
图7 凝聚聚类过程图
凝聚聚类也叫做层次聚类,对应于树状图,在树状图中,横轴标识簇的编号,纵轴表示簇合并的时间。两个簇中间连线表示两簇相似度,距离越小越相似。
使用凝聚聚类对make_blobs数据聚类
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
X,y = make_moons(n_samples=200,random_state=1)
agg = AgglomerativeClustering(n_clusters=3)
ass = agg.fit_predict(X)
plt.scatter(X[:,0],X[:,1],c=ass)
plt.show()效果

图9 使用层次聚类对make_moons数据聚类
使用凝聚聚类对make_moons数据聚类
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
X,y = make_blobs(random_state=1)
agg = AgglomerativeClustering(n_clusters=3)
ass = agg.fit_predict(X)
plt.scatter(X[:,0],X[:,1],c=ass)
plt.show()效果

图10 使用层次聚类对make_blobs数据聚类
3. DBSCAN聚类算法(具有噪声的基于密度的空间聚类应用)
Tip:不需要人为设置cluster的个数
三种类型的点:核心样本,边界点,噪声
两个重要参数:eps,min_sample,eps:表示半径,min_sample:表示半径之内包含其他点的最小数目。

图11 dbscan的具体过程
图11中以每个点为中心,eps为半径,如果之间点的数目小于min_samle,则记红色点位噪声,否则标记该点为核心样本。上图大红色点位核心样本,白色点位噪声,小红色点位边界点。不同标记表示不同的簇。
eps过大大,更多的点被包含在一个簇中,eps过小,所有点可能都被标记位噪声。可以通过适当调节eps,来改变cluster的个数。
在使用DBSCAN时候,可以对数据进行预处理(数据缩放),DBSCAN对数据预处理比较依赖。
使用DBSCAN对make_blobs数据进行聚类
# coding:utf-8
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
X,y = make_moons(n_samples=200,random_state=1,noise=0.05)
# eps:默认为0.5
dbsan = DBSCAN(eps=0.3)
y_pred = dbsan.fit_predict(X)
plt.scatter(X[:,0],X[:,1],c=y_pred)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.show()
图12 使用DBSCAN对make_moons数据进行聚类
本博客有些图文借用了网上一些博文的图片,谢谢!如果本博客存在问题,请在留言区留言!!