Pandas.DataFrame 的使用方法
去除使用pandas的loc或iloc等赋值操作时出现的提示:可引入如下包
import warnings from pandas.core.common import SettingWithCopyWarning warnings.simplefilter(action="ignore", category=SettingWithCopyWarning)
过滤DataFrame:
pandas的DateFrame中使用isin()获取列中相对应的值,也可使用~取反获取相反的对应值
df = df[~df["col_name"].isin(target_list)]
根据相同的列名合并两个dataframe,
如使用id值合并df1和df2,可使用pd.merge(df1, df2, on="id")
合并,删除列值为空的行数据等
df1 = pd.DataFrame(np.array([['a', 5, 9], ['b', 4, 61], ['c', 24, 9]]),
columns=['name', 'attr11', 'attr12'])
df2 = pd.DataFrame(np.array([['a', 5, 19], ['b', 14, 16], ['c', 4, 9]]),
columns=['name', 'attr21', 'attr22'])
df3 = pd.DataFrame(np.array([['a', 15, None], ['b', 4, 36], ['c', 14, 9]]),
columns=['name', 'attr31', 'attr32'])
m = pd.merge(pd.merge(df1, df2, on='name'), df3, on='name')
print(m)
# 删除列值为空的行
m = m.dropna(subset=["attr32"])
print(m)
m["attr32"] = m["attr32"].apply(lambda x: 1000 if x is None else x)
print(m)
DataFrame.drop()
labels: 指定行(或列) 的标签名
axis: '0'删除行,'1'删除列
inplace:是否替换原来的dataframe,默认'False'。
'False':返回一个副本;'True':原dataframe直接被替换(内存值修改)。
删除整行都为0的数据:no_zero_df = template_df[~(template_df == 0).all(axis=1)]
线箱图的异常值计算
用箱形图寻找异常值_wo的博客-CSDN博客_箱线图异常值
图中箱中线是中位数(50%),上边为75%值Q3,下边为25%值Q1
QR代表四分位距,等于Q3 - Q1,上边界异常值为Q3 +1.5 * QR,下边界异常值Q1 - 1.5 * QR
Pandas的DataFrame按照某列值排序,
sort_values(by="col_name", inplace=False, ascending=True,ignore_index=True)

Pandas-排序函数sort_values()_ckSpark的博客-CSDN博客_sort_values()的用法
使用 drop() 删除列或行,参数如下:
labels:要删除的行或列,用列表给出
axis:默认为0,指要删除的是行,删除列时需指定axis为1
index :直接指定要删除的行,删除多行可以使用列表作为参数
columns:直接指定要删除的列,删除多列可以使用列表作为参数
inplace: 默认为False,该删除操作不改变原数据;inplace = True时,改变原数据
如果使用index删除行,则相同的index只能删除一次,后加的数据是累加的;
如 pd.DataFrame().drop(index=0, inplace=True, axis=0),则index为0的元素就删除了,再使用pd.DataFrame().append(df),其index会顺序往下,不会再为0了。
按条件删除pandas.DataFrame某列
1.删除df.ts_code大于等于"500000"且小于"600000"的所有行
df = df.drop(df[(df.ts_code >= "500000") & (df.ts_code < "600000")].index)
2.删除exchange_id列 df = df.drop('exchange_id', axis=1)
Sample抽样的使用方法:
数据不均衡时,需要对样本做抽样,可使用 panda DataFrame 中的 sample() 函数。
pd.DataFrame().sample(self: FrameOrSeries,
n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
n:要抽取的行数
frac:当我们需要抽取数据的百分比时,我们需要用到这个参数;注:与 n 参数不可同时使用。
replace: 是否允许重复抽样,默认情况下为False
weights:代表的是每个样本的权重。
random_state: 随机种子,给定一个具体的数字,保证每次抽样的数据都是相同的。
axis: 选择抽取数据的是行还是列,axis=0时抽取的是行,axis=1的时候抽取的是列。
默认情况下axis=0,即抽取的是行。
Dataframe 中的 apply 传参数方法:df.apply(test, args=(10, 100))
按照DataFrame中的列值排序pd,DataFrame().sort_values(by="time", inplace=True)
DataFrame复制扩展:
sample_df = pd.DataFrame({"a": [1, 2, 3], "b": [4, 5, 6]})
increase_sample_df = pd.DataFrame()
increase_sample_df = increase_sample_df.append([sample_df] * 3) # 扩展 3 倍
DataFrame的read_csv()的参数parse_dates:
parse_dates参数:
将csv中的时间字符串转换成日期格式
TestTime.csv文件:
"name","time","date"
'Bob',21:33:30,2019-10-10
'Jerry',21:30:15,2019-10-10
'Tom',21:25:30,2019-10-10
'Vince',21:20:10,2019-10-10
'Hank',21:40:15,2019-10-10
import pandas as pd
(1)、
df=pd.read_csv('./TestTime.csv',parse_dates=[['time','date']])
print(df)
"""
指定parse_dates = [ ['time', 'date'] ],即将[ ['time', 'date'] ]两列的字符串先合并后解析方可。合并后的新列会以下划线'_'连接原列名命名
本例中解析后的命名为:time_date,解析得到的日期格式列会作为DataFrame的第一列。
在index_col指定表格中的第几列作为Index时需要小心。如本例中,指定参数index_col=0,
则此时会以新生成的time_date列而不是name作为Index。因此保险的方法是指定列名,如index_col = 'name'
结果:
time_date name
0 2019-10-10 21:33:30 'Bob'
1 2019-10-10 21:30:15 'Jerry'
2 2019-10-10 21:25:30 'Tom'
3 2019-10-10 21:20:10 'Vince'
4 2019-10-10 21:40:15 'Hank'
"""
(2)、
df=pd.read_csv('./TestTime.csv',parse_dates=['time','date'])
print(df)
"""
如果写成了parse_dates=['time', 'date'] ,pd.read_csv()会分别对'time', 'date'进行字符串转日期,此外还会造成一个小小的麻烦。
由于本例中的Time时间列格式为'HH:MM:SS',
parse_dates默认调用dateutil.parser.parse解析为Datetime格式,在解析time这一列时,会自作主张在前面加上一个当前日期。
结果:
name time date
0 'Bob' 2019-10-17 21:33:30 2019-10-10
1 'Jerry' 2019-10-17 21:30:15 2019-10-10
2 'Tom' 2019-10-17 21:25:30 2019-10-10
3 'Vince' 2019-10-17 21:20:10 2019-10-10
4 'Hank' 2019-10-17 21:40:15 2019-10-10
"""
【注】:read_csv()方法指定parse_dates会使得读取csv文件的时间大大增加
(3)、
df=pd.read_csv('./TestTime.csv',parse_dates=[['time','date']],infer_datetime_format=True)
print(df)
"""
infer_datetime_format=True可显著减少read_csv命令日期解析时间
"""
(4)、
df=pd.read_csv('./TestTime.csv',parse_dates=[['time','date']],infer_datetime_format=True,keep_date_col=True)
print(df)
"""
keep_date_col=True/False参数则是用来指定解析为日期格式的列是否保留下来,True保留,False不保留
本例中=True即原解析的列time和date被保留下来
结果:
time_date name time date
0 2019-10-10 21:33:30 'Bob' 21:33:30 2019-10-10
1 2019-10-10 21:30:15 'Jerry' 21:30:15 2019-10-10
2 2019-10-10 21:25:30 'Tom' 21:25:30 2019-10-10
3 2019-10-10 21:20:10 'Vince' 21:20:10 2019-10-10
4 2019-10-10 21:40:15 'Hank' 21:40:15 2019-10-10
"""调整DataFrame中列的位置:
data.insert(0,'ID',data.pop('ID')) # 将 ID 列调整到第一个位置
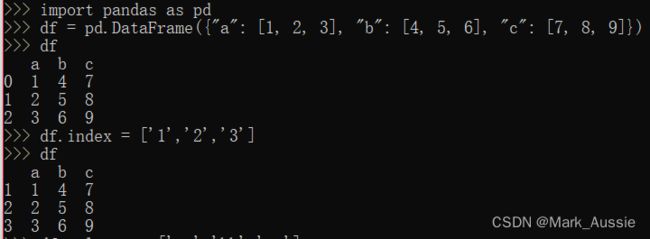
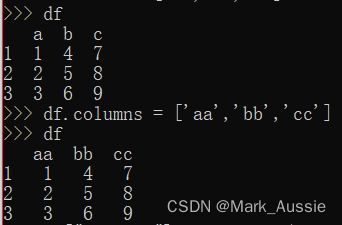
修改DataFrame行列名:
方法1:
修改行标签:df.index = ['1','2','3']
修改列标签:df.columns = ['aa','bb','cc']
方法2:pandas.DataFrame.rename()函数,rename 是专门修改DataFrame坐标轴标签函数。
优点:可以选择性修改某行某列的标签。注:函数/字典中的值必须是唯一的(1对1)。 未包含在字典/Series中的标签将保留原样。 列出的额外标签不会引发错误。
DataFrame.rename(self, mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False, level=None, errors='ignore')
mapper:映射结构,修改columns或index要传入一个映射体,可以是字典、函数。修改列标签跟columns参数一起;修改行标签跟index参数一起。
index:行标签参数,mapper, axis=0 等价于 index=mapper
columns:列标签参数,mapper, axis=1 等价于 columns=mapper
axis:轴标签格式,0代表index,1代表columns,默认index
copy:默认为True,赋值轴标签后面的数据
inplace:默认为False,不在原处修改数据,返回一个新的DataFrame
level:默认为None,处理单个轴标签(有的数据会有2个或多个index或columns)
errors:默认ignore,如果映射体里面包含DataFrame没有的轴标签,忽略不报错
>>> df = pd.DataFrame({"A": [1, 2, 3], "B": [4, 5, 6]})
>>> df.rename(columns={"A": "a", "B": "c"}) # 更改列名称
a c
0 1 4
1 2 5
2 3 6
>>> df.rename(index={0: "x", 1: "y", 2: "z"}) # 更改行名称
A B
x 1 4
y 2 5
z 3 6
>>> df.rename(str.lower, axis='columns') # 列名小写
a b
0 1 4
1 2 5
2 3 6
>>> df.rename({1: 2, 2: 4}, axis='index') # 更改行名称
A B
0 1 4
2 2 5
4 3 6
将字典值写入DataFrame :报错ValueError: If using all scalar values, you must pass an index
传入标称属性需要写入index,需要在创建DataFrame对象时设定index。
四种解决方法:
方法一:直接在创建DataFrame时设置index即可
dict = {'a':1,'b':2,'c':3}
data = pd.DataFrame(dict,index=[0])
方法二:通过from_dict函数将value为标称变量的字典转换为DataFrame对象
dict = {'a':1,'b':2,'c':3}
pd.DataFrame.from_dict(dict,orient='index').T
方法三:输入字典时不要让Value为标称属性,把Value转换为list对象再传入即可
dict = {'a':[1],'b':[2],'c':[3]}
data = pd.DataFrame(dict)
方法四:直接将key和value取出来,都转换成list对象
dict = {'a':1,'b':2,'c':3}
pd.DataFrame(list(dict.items()))
将Series转为Dataframe的方法
使用 to_frame() 函数:
>>> s1 = pd.Series({"a": [1], "b": [2]})
>>> t = s1.to_frame()
>>> type(t)
将 Series 添加到 DataFrame
s1 = s.to_frame()
s2 = pd.DataFrame(s1.values.T,columns=s1.index)
data = pd.concat([df,s2], ignore_index=True)
使用 to_dict() 函数:
>>> s1.to_dict()
{'a': [1], 'b': [2]}
>>> s_l = [s1.to_dict()]
>>> s_l
[{'a': [1], 'b': [2]}]
>>> df = pd.DataFrame(s_l)
>>> df
a b
0 [1] [2]
DataFrame中的to_dict()使用:
>>> data ={ 'name':['Tom','Jarry','Marry','Ali'], 'age':[18,20,21,21], 'major':['Math','English','Physics','Math']}
>>> df1 = pd.DataFrame(data)
name age major
0 Tom 18 Math
1 Jarry 20 English
2 Marry 21 Physics
3 Ali 21 Math
将每条记录转化为字典格式:
>>> data_dict = df1.to_dict(orient='records')
特定两列以字典形式输出,设置name为行标识,获取对应的major数据,
再使用to_dict()形成一个嵌套字典,通过键major,取出需要的信息:
data_dict =df1[["name", "major"]].set_index("name")
df2 = df1.groupby('major')
df2 =df2['name'].apply(lambda x:x.tolist())
df2.to_dict()
DataFrame中列表字符串转为列表:可使用 eval() 函数
>>> strs = "[1, 2, 3]"
>>> eval(strs)
[1, 2, 3]
DataFrame 判断元素是否为 nan:
DataFrame 中为空值的元素类型为 float,可使用 np.nan == np.nan --》False 作为条件判断,为False 时则为 nan 值。
DataFrame 按条件筛选:
精确筛选:df_mots[(df_mots['time'] < 25320)&(df_mots['time'] >= 25270)]
模糊条件,包含指定字符串(包含变量):
df = df[df['director'].notnull()] # 筛选非空数据df = df_mots[(df_mots["HOUR_ID"] == hour_list[b]) & (df_mots['BSC_TS'].str.contains(Moid))]
DataFrame保存csv,中文乱码:
在保存DataFrame为csv文件时,encoding制定为 utf-8 依旧会有中文乱码,可使用 utf_8_sig 替换
DataFrame按行计算和并保存在新列中
>>> df["col_sum"] = df.apply(lambda x: x.sum(), axis=1)
>>> df
aa bb cc col_sum
1 1 4 7 12.0
2 2 5 8 15.0
3 3 6 9 18.0
DataFrame按列计算和并保存在新行中
>>> df.loc["row_sum"] = df.apply(lambda x: x.sum(), axis=0)
>>> df
aa bb cc col_sum
1 1.0 4.0 7.0 12.0
2 2.0 5.0 8.0 15.0
3 3.0 6.0 9.0 18.0
row_sum 6.0 15.0 24.0 45.0
行名称重复ValueError: cannot reindex from a duplicate axis
在使用 pd.DataFrame.loc["index_name", "col_name"] = value 赋值时,如果index名称重复,则会报上述错误;如使用 pd.concat() 时,没有使用 ignore_index =True,则行序号都为0,在使用loc 给行赋值时会产生上述报错。
抽取列值中N个最大最小值:
pd.DataFrame().nlargest(N, '列名'),列中前N个最大值
pd.DataFrame().nsmallest(N, '列名'),列中前N个最小值
用链式操作,nsmallest选出值最小N_1个,nsmallest再选出N_2个最小的:
pd.DataFrame().nlargest(N_1, 'col_name1').nsmallest(N_2, 'col_name2')
diff 方法:计算一列中某元素与该列中另一个元素的差值(默认前一个元素)
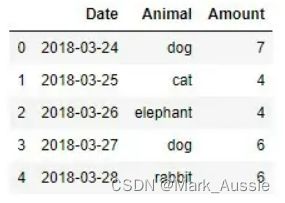
 计算上下两列差值
计算上下两列差值
若 diff(-1),则是上方数值减下方数值
偏度skew:
统计数据分布偏斜方向和程度的度量,是统计数据分布非对称程度的数字特征。偏度(Skewness)亦称偏态、偏态系数。表征概率分布密度曲线相对于平均值不对称程度的特征数。直观看来就是密度函数曲线尾部的相对长度。
定义上偏度是样本的三阶标准化矩: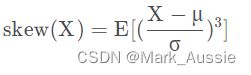
pd.DataFrame().skew()
axis : {index (0), columns (1)},定义计算的轴
skipna : boolean, default True,计算时是否忽略空缺值,默认忽略
level : int or level name, default None
numeric_only : boolean, default None