Spark 3.0 - 4.Pipeline 管道的工作流程
目录
一.引言
二.基本组件
三.Pipeline 基本流程
1.训练 Pipeline - Estimator
2.预测 Pipeline - Transformer
四.Pipeline 分解与构造
1.DataFrame
2.Transformer1 - Tokenizer
3.Transformer2 - HashingTF
4.Estimator - LR
5.Pipeline With ParamMap - Estimator
5.1.配置 Pipeline
5.2.配置 ParamMap
5.3 Pipeline.fit
6.Pipeline With ParamMap - Transformer
6.1 模型存储与加载
6.2 Model transformer
7.完整代码
五.总结
一.引言
Spark ML 使用管道 Pipeline 就像 Python Sklearn 一样,可以把多个步骤例如 特征处理 -> 特征提取 -> 模型训练 等联结起来,让数据在 Pipeline 中流动。有了 Pipeline 之后,ML 更适合创建包含从数据清洗到特征工程再到模型训练等一系列流程中,无论什么模型都提供了统一的算法操作接口即 fit(),下面让我们看下管道的基本组件与流程示例。
二.基本组件
- DataFrame
数据源,也是 Spark Sql 中的概念,可以容纳多种数据类型用来保存数据。例如,一个 DataFrame 可以存储文本、标签、特征向量等不同列。可以说 ML 的所有基本 API 最终都需要以源头的 DataFrame 数据为主。
- Transformer
转换器,和 Spark、Flink 里的 Transformer 类似,例如 RDD -> RDD、DataStream -> DataStream,这里 Transformer 负责将 DataFrame 转换为 DataFrame。每个 Tansformer 都有一个 transform 方法,负责在原有 DataFrame 的基础上添加一个或者多个列得到新的 DataFrame。例如将原始数据转换,并增加一列新的特征向量。
- Estimator
Estimator 负责根据样本 fit 训练得到一个模型,模型的本质也是 Transformer,因为给定一个 DataFrame 数据集,模型可以转化得到一个新的预测标签列,所以 Estimator 就是调用 fit 方法并最终得到一个 Transformer。LR、SVM、PCA 等都可以看做是 Estimator。
- Pipeline
管道,Pipeline 将多个 Transformer 与 Estimator 连接起来并按顺序确定一个机器学习的工作流程。届时管道里的每一步都可以看做是一个 Stage,Stage 可以是 Transformer 也可以是 Estimator,就像 Spark 的 Stage 一样,一个任务流程图 Graph 梳理好后,每一步的组件都是固定的。
- Parameter
通用 API,由于 Pipeline 中可能存在多个 Transformer 与 Estimator,使用 Builder 的形式不易统一维护,所以可以使用 Parameter 一次性定义好所以参数,就像 SparkConf 一样。
三.Pipeline 基本流程
Pipeline 是一个管道,包含一个或多个 Transformer 与 Estimator,但是一个完整的 Pipeline 本质上也是 Transformer 或者 Estimator,区分 Pipeline 属于哪个类型,看其对应方法即可,如果调用 fit() 方法,那它就是 Estimator,如果调用 transform 方法,那它就是 Transformer。一般来说训练模型的 Pipeline 是 Estimator,通过模型预测结果的是 Transfomer。
1.训练 Pipeline - Estimator
下面通过基础的文本处理 LR 算法介绍了 Pipeline - Estimator 流程:
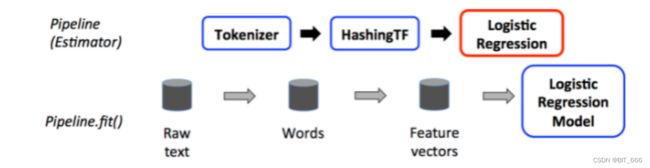
其中 Tokenizer 与 HashingTF 为 Transformer,负责数据的预处理与特征转化,最后的 Logistic Regression 是 Estimator,其负责 fit 上一个 Stage 送来的特征数据并得到模型。由于 Pipeline 的最后一个 Stage 是 Estimator,所以该 Pipeline 调用 fit() 方法,其类型也对应 Pipeline - Estimator。
Tips:
每个 Transformer 与 Estimator 都有一个唯一的 uid,可以视为当前 stage 的标识,用于保存对应的参数,即使是相同的类型也能有相同的 ID。
2.预测 Pipeline - Transformer
对于同一套流程的 Estimator 和 Transfomer 的 Pipeline 流程整体区别很小:
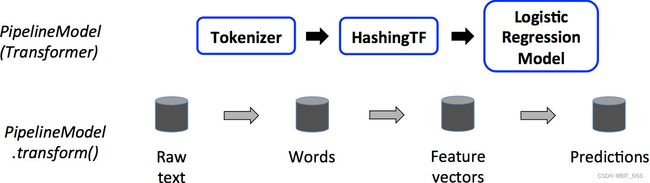
可以看到主要差别在 Pipeline 的最后一个 Stage,虽然依然是 Logistic Regression,但是 model 不再调用 fit() 方法训练模型,而是调用 transform() 预测最终结果,所以 Pipeline 的类型也随着最后一个 Stage 而转换为 Pepeline - Transformer,其余处理流程相同。下面通过实例实现展示如何实现一个 Pipeline 训练与预测。
四.Pipeline 分解与构造
上面介绍了 Pipeline 五大组件与一个 LR 的文本处理流程,下面示例将基于图中的组件一一介绍,并最终合并为完整的 Pipeline。
1.DataFrame
// 准备数据(id, text, label).
val training = spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)
)).toDF("id", "text", "label")本地模拟样本数据,其中 text 未未分词的文档内容,id 代表序号,Label 代表正负样本,由于是模拟样本,实际场景下,text 可以是评论或者留言,而 Label 可以标识该 text 是积极评论还是消极评论,或者留言是正向还是负向。
2.Transformer1 - Tokenizer
Tokenizer 为文档单词提取器,其利用分词将每个文档的文本拆分为单词。
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
val info = hashingTF.transform(training)
- setInputCol
设置输入文本列,本例下即为 text,例如 hadoop mapreduce。
- setOutputCol
设置分词后的输出列,为原始 DataFrame 新增一列分词列,其包含 text 后分词的结果,类型为 WrappedArray,单独调用 transform 后得到新的一列,其中文本已分词完毕。
[0,a b c d e spark,1.0,WrappedArray(a, b, c, d, e, spark)]
[1,b d,0.0,WrappedArray(b, d)]
[2,spark f g h,1.0,WrappedArray(spark, f, g, h)]
[3,hadoop mapreduce,0.0,WrappedArray(hadoop, mapreduce)]3.Transformer2 - HashingTF
HashingTF 负责特征的向量化,负责将每个文档对应的单词转换为数值型的特征向量 Vector。
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val info = hashingTF.transform(tokenizer.transform(training))
- setNumFeatures
标识词库维度,例如你的评论词库规定为 10000 维,这使用 HashingTF hash 得到的特征列维度为 10000 维。
- setInpuCol
设置输入列,这里输入列即为上面 Tokenizer 生成的 WrappedArray()。
- setOutputCol
设置输出列,本例中输出列名为 features,后续与 label 组合可供 Estimator fit 使用。

HashingTF 共返回三维数据 (featurNum, IndexArray, IndexCount),分别为特征数,特征映射后的 HashId 数组以及对应 HashId 的出现次数。
Tips1:
将 hadoop mapreduce 修改为 hadoop mapreduce hadoop spark spark 后,可以看到对应单词 HashId 的次数由 1 变为 2。

Tips2:
numFeatures 特征数,NLP 场景也可以理解为词库大小,默认值为 262144,如果 numFeatures 严重小于真实词库大小,会出现 hash 到同一分桶的情况,影响模型区分度。修改 numFeatures = 2 可以看到虽然有多个 word,但是 hashId 只有2维:

4.Estimator - LR
Logistic Regression 这里不再赘述,上文我们做了详细的参数介绍,大家可以参考。
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.001)
lr.fit(hashingTF.transform(tokenizer.transform(training)))
启动后即可显示 LR 运行日志:

5.Pipeline With ParamMap - Estimator
lr.fit(hashingTF.transform(tokenizer.transform(training)))5.1.配置 Pipeline
回看上面的代码,transform + transform + fit 其实就是一个完整的 pipeline 管道流程,下面我们使用 Spark ML API 配置该管道,后续只需调用 pipeline.fit 即可实现与上面代码相同的效果,条理清晰了很多且易于管理。
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))5.2.配置 ParamMap
随着 Transformer 和 Estimator 数量的增加,每次使用 Builder 分别设置每个 Satage 维护起来非常麻烦,我们希望每个 Pipeline 的多个 Stage 只需一个 properties 维护,这就是 ParamMap 的由来,将 Tokenizer 、HashingTF 与 LR 的参数统一至 ParamMap 中。
val paramMap = ParamMap(lr.maxIter -> 20, lr.regParam -> 0.01)
.put(tokenizer.inputCol -> "text", tokenizer.outputCol -> "words")
.put(hashingTF.numFeatures -> 1000, hashingTF.inputCol -> "words", hashingTF.outputCol -> "features")5.3 Pipeline.fit
// 调用fit()函数,训练数据
val model = pipeline.fit(training, paramMap)通过上面一通操作,我们的 pipeline 终于构建好了,现在调用 fit 方法即可训练模型。
6.Pipeline With ParamMap - Transformer
6.1 模型存储与加载
fit 得到的模型可以存储并根据响应地址加载
可以将训练好的pipeline输出到磁盘
model.write.overwrite().save("/tmp/spark-logistic-regression-model")
也可以直接将为进行训练的pipeline写到文件
pipeline.write.overwrite().save("/tmp/unfit-lr-model")
然后加载到出来
val pipelineModel = PipelineModel.load("/tmp/spark-logistic-regression-model")6.2 Model transformer
// 准备(id, text) 这个格式未打标签的数据进行测试
val test = spark.createDataFrame(Seq(
(4L, "spark i j k"),
(5L, "l m n"),
(6L, "spark hadoop spark"),
(7L, "apache hadoop")
)).toDF("id", "text")
// 在测试集上进行预测
pipelineModel.transform(test)
.select("id", "text", "probability", "prediction")
.collect()
.foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
println(s"($id, $text) --> prob=$prob, prediction=$prediction")
}再次调用 pipelineModel transform 方法即可完成预测流程。
7.完整代码
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
// $example off$
import org.apache.spark.sql.SparkSession
object PipelineExample {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder //创建spark会话
.master("local") //设置本地模式
.appName("PipelineExample") //设置名称
.getOrCreate() //创建会话变量
// $example on$
// 准备数据(id, text, label).
val training = spark.createDataFrame(Seq(
(0L, "a b c d e spark", 1.0),
(1L, "b d", 0.0),
(2L, "spark f g h", 1.0),
(3L, "hadoop mapreduce", 0.0)
)).toDF("id", "text", "label")
// 配置一个包含三个stage的ML pipeline: tokenizer, hashingTF, and lr.
val tokenizer = new Tokenizer()
.setInputCol("text")
.setOutputCol("words")
val hashingTF = new HashingTF()
.setNumFeatures(1000)
.setInputCol(tokenizer.getOutputCol)
.setOutputCol("features")
val lr = new LogisticRegression()
.setMaxIter(10)
.setRegParam(0.001)
val pipeline = new Pipeline()
.setStages(Array(tokenizer, hashingTF, lr))
// 调用fit()函数,训练数据
val model = pipeline.fit(training)
// 可以将训练好的pipeline输出到磁盘
model.write.overwrite().save("/tmp/spark-logistic-regression-model")
// 也可以直接将为进行训练的pipeline写到文件
pipeline.write.overwrite().save("/tmp/unfit-lr-model")
// 然后加载到出来
val sameModel = PipelineModel.load("/tmp/spark-logistic-regression-model")
// 准备(id, text) 这个格式未打标签的数据进行测试
val test = spark.createDataFrame(Seq(
(4L, "spark i j k"),
(5L, "l m n"),
(6L, "spark hadoop spark"),
(7L, "apache hadoop")
)).toDF("id", "text")
// 在测试集上进行预测
model.transform(test)
.select("id", "text", "probability", "prediction")
.collect()
.foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>
println(s"($id, $text) --> prob=$prob, prediction=$prediction")
}
// $example off$
spark.stop()
}
}五.总结
Pipeline Transformer 与 Pipeline Estimator 的构建大致就这些,本文采用简易数据测试不具代表性,后续将基于豆瓣电影评论实战,介绍如何自定义 Transformer 与 豆瓣影评情感分析实战。可以看到 Pipeline 的好处是将内部流程全部封装,用户对中间流程不感知,只需将数据处理为合适的格式即可直接调用并获得相应结果,而单独的 Transformer 与 Estimator 则更适合一步一步调试或获取中间结果,二者各有利弊,大家可以根据情况选择。
