Spark大数据分布式处理实战笔记(五):Spark MLlib

前言
Spark是一种大规模、快速计算的集群平台,本公众号试图通过学习Spark官网的实战演练笔记提升笔者实操能力以及展现Spark的精彩之处。有关框架介绍和环境配置可以参考以下内容:
1.大数据处理框架Hadoop、Spark介绍
2.linux下Hadoop安装与环境配置
3.linux下Spark安装与环境配置
本文的参考配置为:Deepin 15.11、Java 1.8.0_241、Hadoop 2.10.0、Spark 2.4.4、scala 2.11.12
本文的目录为:
一、基本统计
1.相关性
2.假设检验
3.Summarizer
二、ML管道
1.管道组件
2.参数
3.ML持久性
4.管道示例
三、提取、转换和特征选择
1.特征提取
2.特征转换
3.特征选择
4.局部敏感哈希
四、分类与回归
1.分类
2.回归
五、聚类
1.K-means
2.LDA
3.GMM
六、协同过滤
1.显式反馈与隐式反馈
2.正则化参数的缩放
3.冷启动策略
七、频繁模式挖掘
1.FP增长
2.前缀跨度
八、模型选择和交叉验证
1.模型选择
2.交叉验证
一、基本统计
1.相关性
计算两列数据之间的相关性是“统计”中的常见操作。在spark.ml 中提供了很多方法计算两两相关性。目前支持的相关方法是Pearson和Spearman的相关。
import org.apache.spark.ml.linalg.{Matrix, Vectors}
import org.apache.spark.ml.stat.Correlation
import org.apache.spark.sql.Row
// # 定义数据
scala> val data = Seq(
| Vectors.sparse(4, Seq((0, 1.0), (3, -2.0))),
| Vectors.dense(4.0, 5.0, 0.0, 3.0),
| Vectors.dense(6.0, 7.0, 0.0, 8.0),
| Vectors.sparse(4, Seq((0, 9.0), (3, 1.0)))
| )
data: Seq[org.apache.spark.ml.linalg.Vector] = List((4,[0,3],[1.0,-2.0]), [4.0,5.0,0.0,3.0], [6.0,7.0,0.0,8.0], (4,[0,3],[9.0,1.0]))
// # Tuple1为scala中元组表达方式
scala> val df = data.map(Tuple1.apply).toDF("features")
df: org.apache.spark.sql.DataFrame = [features: vector]
// # 皮尔逊相关系数
scala> val Row(coeff1: Matrix) = Correlation.corr(df, "features").head
scala> println(s"Pearson correlation matrix:\n $coeff1")
Pearson correlation matrix:
1.0 0.055641488407465814 NaN 0.4004714203168137
0.055641488407465814 1.0 NaN 0.9135958615342522
NaN NaN 1.0 NaN
0.4004714203168137 0.9135958615342522 NaN 1.0
// # 斯皮尔曼相关系数
scala> val Row(coeff2: Matrix) = Correlation.corr(df, "features", "spearman").head
scala> println(s"Spearman correlation matrix:\n $coeff2")
Spearman correlation matrix:
1.0 0.10540925533894532 NaN 0.40000000000000174
0.10540925533894532 1.0 NaN 0.9486832980505141
NaN NaN 1.0 NaN
0.40000000000000174 0.9486832980505141 NaN 1.0
2.假设检验
假设检验是一种强大的统计工具,可用来确定结果是否具有统计意义,以及该结果是否偶然发生。spark.ml目前支持Pearson的卡方检验(独立性检验)。
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.ml.stat.ChiSquareTest
// 定义数据
scala> val data = Seq(
| (0.0, Vectors.dense(0.5, 10.0)),
| (0.0, Vectors.dense(1.5, 20.0)),
| (1.0, Vectors.dense(1.5, 30.0)),
| (0.0, Vectors.dense(3.5, 30.0)),
| (0.0, Vectors.dense(3.5, 40.0)),
| (1.0, Vectors.dense(3.5, 40.0))
| )
data: Seq[(Double, org.apache.spark.ml.linalg.Vector)] = List((0.0,[0.5,10.0]), (0.0,[1.5,20.0]), (1.0,[1.5,30.0]), (0.0,[3.5,30.0]), (0.0,[3.5,40.0]), (1.0,[3.5,40.0]))
scala> val df = data.toDF("label", "features")
df: org.apache.spark.sql.DataFrame = [label: double, features: vector]
scala> val chi = ChiSquareTest.test(df, "features", "label").head
chi: org.apache.spark.sql.Row = [[0.6872892787909721,0.6822703303362126],WrappedArray(2, 3),[0.75,1.5]]
scala> println(s"pValues = ${chi.getAs[Vector](0)}")
pValues = [0.6872892787909721,0.6822703303362126]
scala> println(s"degreesOfFreedom ${chi.getSeq[Int](1).mkString("[", ",", "]")}")
degreesOfFreedom [2,3]
scala> println(s"statistics ${chi.getAs[Vector](2)}")
statistics [0.75,1.5]
3.Summarizer
我们通过Summarizer提供Dataframe矢量列汇总统计 。可用的度量是按列的最大值,最小值,平均值,方差和非零数以及总数。
import org.apache.spark.ml.linalg.{Vector, Vectors}
import org.apache.spark.ml.stat.Summarizer
scala> val data = Seq(
| (Vectors.dense(2.0, 3.0, 5.0), 1.0),
| (Vectors.dense(4.0, 6.0, 7.0), 2.0)
| )
data: Seq[(org.apache.spark.ml.linalg.Vector, Double)] = List(([2.0,3.0,5.0],1.0), ([4.0,6.0,7.0],2.0))
scala> val df = data.toDF("features", "weight")
df: org.apache.spark.sql.DataFrame = [features: vector, weight: double]
// Summarizer应用
scala> val (meanVal,varianceVal) = df.select(Summarizer.metrics("mean","variance").summary($"features",$"weight").as("summary")).select("summary.mean","summary.variance").as[(Vector,Vector)].first()
meanVal: org.apache.spark.ml.linalg.Vector = [3.333333333333333,5.0,6.333333333333333]
varianceVal: org.apache.spark.ml.linalg.Vector = [2.0,4.5,2.0]
二、ML管道
1.管道组件
MLlib对用于机器学习算法的API进行了标准化,从而使将多种算法组合到单个管道或工作流中变得更加容易。Spark中的管道概念主要受scikit-learn项目的启发,包含以下几块:
DataFrame:此ML API使用DataFrameSpark SQL作为ML数据集,可以保存各种数据类型。例如,DataFrame可能有不同的列,用于存储文本,特征向量,真实标签和预测值。
Transformer:是一种算法,其可以将一个DataFrame到另一个DataFrame。例如,Transformer可以将具有特征的DataFrame转换为具有预测的DataFrame。
Estimator:是一种算法,可以适合DataFrame来产生Transformer。例如,学习算法是在上Estimator进行训练DataFrame并生成模型的算法。
Parameter:所有Transformer和Estimator现在共享一个用于指定参数的通用API。
Pipeline被指定为一个阶段序列,每个阶段是一个Transformer或一个Estimator。这些阶段按顺序运行,并且输入DataFrame在通过每个阶段时都会进行转换。对于Transformer阶段,该transform()方法在上调用DataFrame。对于Estimator阶段,将fit()调用方法来生成Transformer(成为PipelineModel或一部分Pipeline)Transformer的transform()方法,并且在上调用的方法DataFrame(如下图)。
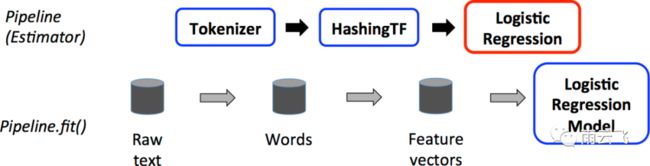
2.参数
MLlib Estimator和Transformers使用统一的API来指定参数。一个Param是带有独立文件的命名参数。一个ParamMap是一组(参数,值)对。
将参数传递给算法的主要方法有两种:
设置实例的参数。例如,如果lr是的一个实例LogisticRegression,一个可以调用lr.setMaxIter(10),使lr.fit()最多10次迭代使用。该API类似于spark.mllib软件包中使用的API 。
将ParamMap传递给fit()或transform()。中的任何参数都ParamMap将覆盖先前通过setter方法指定的参数。
3.ML持久性
通常,将模型或管道保存到磁盘以供以后使用是值得的。从Spark 2.3开始,基于DataFrame的API spark.ml并pyspark.ml具有完整的覆盖范围。ML持久性可跨Scala,Java和Python使用。
4.管道示例
import org.apache.spark.ml.{Pipeline, PipelineModel}
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.feature.{HashingTF, Tokenizer}
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
scala> val training = spark.createDataFrame(Seq(
| (0L, "hadoop spark hdfs streaming", 1.0),
| (1L, "rdd pipline ml graph", 0.0),
| (2L, "flink kafka hive storm", 1.0),
| (3L, "mr vector classification regression ", 0.0)
| )).toDF("id", "text", "label")
training: org.apache.spark.sql.DataFrame = [id: bigint, text: string ... 1 more field]
scala> val tokenizer = new Tokenizer().setInputCol("text").setOutputCol("words")
tokenizer: org.apache.spark.ml.feature.Tokenizer = tok_d558d41cf35a
scala> val hashingTF = new HashingTF().setNumFeatures(1000).setInputCol(tokenizer.getOutputCol).setOutputCol("features")
hashingTF: org.apache.spark.ml.feature.HashingTF = hashingTF_b401b9d293c1
scala> val lr = new LogisticRegression().setMaxIter(10).setRegParam(0.001)
lr: org.apache.spark.ml.classification.LogisticRegression = logreg_157e397530b7
scala> val pipeline = new Pipeline().setStages(Array(tokenizer, hashingTF, lr))
pipeline: org.apache.spark.ml.Pipeline = pipeline_5688fc038a90
scala> val model = pipeline.fit(training)
model: org.apache.spark.ml.PipelineModel = pipeline_5688fc038a90
scala> model.write.overwrite().save("tmp/flr-model")
scala> pipeline.write.overwrite().save("tmp/unfit-lr-model")
scala> val sameModel = PipelineModel.load("tmp/lr-model")
sameModel: org.apache.spark.ml.PipelineModel = pipeline_5688fc038a90
scala> val test = spark.createDataFrame(Seq(
| (4L, "spark kafka flink"),
| (5L, "rdd classification vector"),
| (6L, "hive hdfs streaming"),
| (7L, "pipline ml regression")
| )).toDF("id", "text")
test: org.apache.spark.sql.DataFrame = [id: bigint, text: string]
scala> model.transform(test).select("id", "text", "probability", "prediction").collect().foreach { case Row(id: Long, text: String, prob: Vector, prediction: Double) =>println(s"($id, $text) --> prob=$prob, prediction=$prediction")}
(4, spark kafka flink) --> prob=[0.007999539616433434,0.9920004603835666], prediction=1.0
(5, rdd classification vector) --> prob=[0.9920004603835666,0.007999539616433316], prediction=0.0
(6, hive hdfs streaming) --> prob=[0.03865862309026796,0.9613413769097321], prediction=1.0
(7, pipline ml regression) --> prob=[0.9920004603835666,0.007999539616433316], prediction=0.0
三、提取、转换和特征选择
1.特征提取
在Spark中特征提取主要有四种方案:
TF-IDF:术语频率逆文档频率(TF-IDF) 是一种特征向量化方法,广泛用于文本挖掘中,以反映术语对语料库中文档的重要性。
Word2Vec:Word2Vec是一个Estimator包含代表文档的单词序列并训练一个的 Word2VecModel。该模型将每个单词映射到唯一的固定大小的向量。
CountVectorizer:CountVectorizer和CountVectorizerModel旨在帮助转换文本文档的集合令牌计数的载体。当先验词典不可用时,CountVectorizer可以用作Estimator提取词汇表并生成CountVectorizerModel。
FeatureHasher:特征哈希将一组分类或数字特征投影到指定维度的特征向量中(通常大大小于原始特征空间的特征向量)。这是通过使用哈希技巧 将特征映射到特征向量中的索引来完成的。
此处用示例展现以下word2vec的用法:
import org.apache.spark.ml.feature.Word2Vec
import org.apache.spark.ml.linalg.Vector
import org.apache.spark.sql.Row
scala> val documentDF = spark.createDataFrame(Seq("Hi I heard about Spark".split(" "),"I wish Java could use case classes".split(" "),"Logistic regression models are neat".split(" ")).map(Tuple1.apply)).toDF("text")
documentDF: org.apache.spark.sql.DataFrame = [text: array]
scala> val word2Vec = new Word2Vec().setInputCol("text").setOutputCol("result").setVectorSize(3).setMinCount(0)
word2Vec: org.apache.spark.ml.feature.Word2Vec = w2v_681123543749
scala> val model = word2Vec.fit(documentDF)
model: org.apache.spark.ml.feature.Word2VecModel = w2v_681123543749
scala> val result = model.transform(documentDF)
result: org.apache.spark.sql.DataFrame = [text: array, result: vector]
scala> result.collect().foreach { case Row(text: Seq[_], features: Vector) =>println(s"Text: [${text.mkString(", ")}] => \nVector: $features\n") }
Text: [Hi, I, heard, about, Spark] =>
Vector: [-0.008142343163490296,0.02051363289356232,0.03255096450448036]
Text: [I, wish, Java, could, use, case, classes] =>
Vector: [0.043090314205203734,0.035048123182994974,0.023512658663094044]
Text: [Logistic, regression, models, are, neat] =>
Vector: [0.038572299480438235,-0.03250147425569594,-0.01552378609776497]
2.特征转换
Spark中的特征转换支持方法非常多,有Tokenizer、去除停用词、n-gram、二值化、多项式展开、余弦变换、字符串索引、OneHot编码、向量索引、特征交叉、归一化、标准化、SQL转换、离散化处理等等,在此用PCA方法举例,其余方法在此不做赘述。
import org.apache.spark.ml.feature.PCA
import org.apache.spark.ml.linalg.Vectors
scala> val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
df: org.apache.spark.sql.DataFrame = [features: vector]
scala> val pca = new PCA()
pca: org.apache.spark.ml.feature.PCA = pca_c5df742a6159
scala> val pca = new PCA().setInputCol("features").setOutputCol("pcaFeatures").setK(3).fit(df)
pca: org.apache.spark.ml.feature.PCAModel = pca_1a2765b21130
scala> val result = pca.transform(df).select("pcaFeatures")
result: org.apache.spark.sql.DataFrame = [pcaFeatures: vector]
scala> result.show(false)
+-----------------------------------------------------------+
|pcaFeatures |
+-----------------------------------------------------------+
|[1.6485728230883807,-4.013282700516296,-5.524543751369388] |
|[-4.645104331781534,-1.1167972663619026,-5.524543751369387]|
|[-6.428880535676489,-5.337951427775355,-5.524543751369389] |
+-----------------------------------------------------------+
3.特征选择
VectorSlicer:是一个采用特征向量并输出带有原始特征子数组的新特征向量的转换器。这对于从向量列中提取特征很有用。VectorSlicer接受具有指定索引的向量列,然后输出一个新的向量列,其值通过这些索引选择。
RFormula:由R模型公式指定的列。当前,我们支持R运算符的有限子集,包括“〜”,“。”,“:”,“ +”和“-”。
ChiSqSelector:代表Chi-Squared特征选择。它对具有分类特征的标记数据进行操作。ChiSqSelector使用 卡方独立性检验来决定选择哪些功能。
4.局部敏感哈希
局部敏感哈希(LSH)是一类重要的哈希技术,通常用于大型数据集的聚类,近似最近邻搜索和离群值检测。
LSH的一般想法是使用一个函数族(“ LSH族”)将数据点散列到存储桶中,以便彼此靠近的数据点很有可能位于同一存储桶中,而彼此相距很远的情况很可能在不同的存储桶中。LSH族的正式定义如下。在度量空间中(M, d),M是,d是上的距离函数M,LSH族是h满足以下属性的函数族:
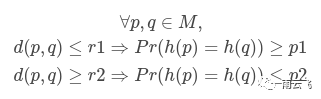
四、分类与回归
1.分类
分类是一种重要的机器学习和数据挖掘技术。分类的目的是根据数据集的特点构造一个分类函数或分类模型(也常常称作分类器),该模型能把未知类别的样本映射到给定类别中的一种技术。Spark MLlib库中支持的分类算法有限,大致如下:
逻辑回归
决策树分类器
随机森林分类器
梯度提升树分类器
多层感知器分类器
线性支持向量机
相对于静止的分类器
朴素贝叶斯
2.回归
Spark回归分析与分类相似,大致支持如下算法:
线性回归
广义线性回归
决策树回归
随机森林回归
梯度提升树回归
生存回归
等渗回归
本文就梯度提升树分类器(GBDT)进行测试举例:
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.feature.VectorIndexer
import org.apache.spark.ml.regression.{GBTRegressionModel, GBTRegressor}
scala> val data = spark.read.format("libsvm").load("file:///usr/local/spark/data/mllib/sample_libsvm_data.txt")
data: org.apache.spark.sql.DataFrame = [label: double, features: vector]
scala> val featureIndexer = new VectorIndexer().setInputCol("features").setOutputCol("indexedFeatures").setMaxCategories(4).fit(data)
featureIndexer: org.apache.spark.ml.feature.VectorIndexerModel = vecIdx_98e6565098b8
scala> val Array(trainingData, testData) = data.randomSplit(Array(0.7, 0.3))
trainingData: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [label: double, features: vector]
testData: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [label: double, features: vector]
scala> val gbt = new GBTRegressor().setLabelCol("label").setFeaturesCol("indexedFeatures").setMaxIter(10)
gbt: org.apache.spark.ml.regression.GBTRegressor = gbtr_ab02ea511704
scala> val pipeline = new Pipeline().setStages(Array(featureIndexer, gbt))
pipeline: org.apache.spark.ml.Pipeline = pipeline_78e609f11fd2
scala> val model = pipeline.fit(trainingData)
model: org.apache.spark.ml.PipelineModel = pipeline_78e609f11fd2
scala> val predictions = model.transform(testData)
predictions: org.apache.spark.sql.DataFrame = [label: double, features: vector ... 2 more fields]
scala> predictions.select("prediction", "label", "features").show(5)
+----------+-----+--------------------+
|prediction|label| features|
+----------+-----+--------------------+
| 0.0| 0.0|(692,[95,96,97,12...|
| 0.0| 0.0|(692,[122,123,148...|
| 0.0| 0.0|(692,[123,124,125...|
| 0.0| 0.0|(692,[124,125,126...|
| 0.0| 0.0|(692,[126,127,128...|
+----------+-----+--------------------+
only showing top 5 rows
scala> val evaluator = new RegressionEvaluator().setLabelCol("label").setPredictionCol("prediction").setMetricName("rmse")
evaluator: org.apache.spark.ml.evaluation.RegressionEvaluator = regEval_47ca0861b89d
scala> val rmse = evaluator.evaluate(predictions)
rmse: Double = 0.18569533817705186
scala> println(s"Root Mean Squared Error (RMSE) on test data = $rmse")
Root Mean Squared Error (RMSE) on test data = 0.18569533817705186
scala> val gbtModel = model.stages(1).asInstanceOf[GBTRegressionModel]
gbtModel: org.apache.spark.ml.regression.GBTRegressionModel = GBTRegressionModel (uid=gbtr_ab02ea511704) with 10 trees
scala> println(s"Learned regression GBT model:\n ${gbtModel.toDebugString}")
Learned regression GBT model:
GBTRegressionModel (uid=gbtr_ab02ea511704) with 10 trees
Tree 0 (weight 1.0):
...
五、聚类
1.K-means
k均值是最常用的聚类算法之一,它将数据点聚集成预定数量的聚类。MLlib实现包括k-means ++方法的并行变体,称为kmeans ||。KMeans实现为,Estimator并生成KMeansModel作为基础模型。
import org.apache.spark.ml.clustering.KMeans
import org.apache.spark.ml.evaluation.ClusteringEvaluator
scala> val dataset = spark.read.format("libsvm").load("file:///usr/local/spark/data/mllib/sample_kmeans_data.txt")
dataset: org.apache.spark.sql.DataFrame = [label: double, features: vector]
scala> val kmeans = new KMeans().setK(2).setSeed(1L)
kmeans: org.apache.spark.ml.clustering.KMeans = kmeans_e5a91572513f
scala> val model = kmeans.fit(dataset)
model: org.apache.spark.ml.clustering.KMeansModel = kmeans_e5a91572513f
scala> val predictions = model.transform(dataset)
predictions: org.apache.spark.sql.DataFrame = [label: double, features: vector ... 1 more field]
scala> val evaluator = new ClusteringEvaluator()
evaluator: org.apache.spark.ml.evaluation.ClusteringEvaluator = cluEval_ef4885f71d8a
scala> val silhouette = evaluator.evaluate(predictions)
silhouette: Double = 0.9997530305375207
scala> model.clusterCenters.foreach(println)
[0.1,0.1,0.1]
[9.1,9.1,9.1]
2.LDA
LDA实现为Estimator同时支持EMLDAOptimizer和Online-LDA-Optimizer,并生成LDAModel作为基础模型。如果需要,专家用户可以将LDAModel生成的 EMLDAOptimizer转换为DistributedLDAModel。
import org.apache.spark.ml.clustering.LDA
scala> val dataset = spark.read.format("libsvm").load("file:///usr/local/spark/data/mllib/sample_lda_libsvm_data.txt")
dataset: org.apache.spark.sql.DataFrame = [label: double, features: vector]
scala> val lda = new LDA().setK(10).setMaxIter(10)
lda: org.apache.spark.ml.clustering.LDA = lda_456208b1d37f
scala> val model = lda.fit(dataset)
model: org.apache.spark.ml.clustering.LDAModel = lda_456208b1d37f
scala> val ll = model.logLikelihood(dataset)
ll: Double = -788.3752801566864
scala> val lp = model.logPerplexity(dataset)
lp: Double = 3.0322126159872553
scala> println(s"The lower bound on the log likelihood of the entire corpus: $ll")
The lower bound on the log likelihood of the entire corpus: -788.3752801566864
scala> println(s"The upper bound on perplexity: $lp")
The upper bound on perplexity: 3.0322126159872553
scala>
scala> val topics = model.describeTopics(3)
topics: org.apache.spark.sql.DataFrame = [topic: int, termIndices: array ... 1 more field]
scala> topics.show(false)
+-----+-----------+---------------------------------------------------------------+
|topic|termIndices|termWeights |
+-----+-----------+---------------------------------------------------------------+
... ... ...
scala> val transformed = model.transform(dataset)
transformed: org.apache.spark.sql.DataFrame = [label: double, features: vector ... 1 more field]
scala> transformed.show(false)
+-----+-----------+----------------------+
|label|features |topicDistribution |
+-----+-----------+----------------------+
... ... ...
3.GMM
高斯混合模型(GMM)代表一个复合分布,由此点是从一个绘制ķ高斯子分布,每个具有其自己的概率。该spark.ml实现使用 期望最大化 算法在给定一组样本的情况下得出最大似然模型。GaussianMixture实现为,Estimator并生成GaussianMixtureModel作为基础模型。
import org.apache.spark.ml.clustering.GaussianMixture
scala> val dataset = spark.read.format("libsvm").load("file:///usr/local/spark/data/mllib/sample_lda_libsvm_data.txt")
:1: error: illegal character '\u200b'
val dataset = spark.read.format("libsvm").load("file:///usr/local/spark/data/mllib/sample_lda_libsvm_data.txt")
^
scala> val dataset = spark.read.format("libsvm").load("file:///usr/local/spark/data/mllib/sample_lda_libsvm_data.txt")
20/02/26 20:06:43 WARN libsvm.LibSVMFileFormat: 'numFeatures' option not specified, determining the number of features by going though the input. If you know the number in advance, please specify it via 'numFeatures' option to avoid the extra scan.
dataset: org.apache.spark.sql.DataFrame = [label: double, features: vector]
scala> val gmm = new GaussianMixture().setK(2)
gmm: org.apache.spark.ml.clustering.GaussianMixture = GaussianMixture_4c1984b8bd4c
scala> val model = gmm.fit(dataset)
model: org.apache.spark.ml.clustering.GaussianMixtureModel = GaussianMixture_4c1984b8bd4c
scala> for (i <- 0 until model.getK) {
| println(s"Gaussian $i:\nweight=${model.weights(i)}\n" +
| s"mu=${model.gaussians(i).mean}\nsigma=\n${model.gaussians(i).cov}\n")
| }
Gaussian 0:
...
Gaussian 1:
...
六、协同过滤
协作过滤通常用于推荐系统。这些技术旨在填充用户项关联矩阵的缺失条目。spark.ml当前支持基于模型的协作过滤,其中通过一小部分潜在因素来描述用户和产品,这些潜在因素可用于预测缺失条目。
1.显式反馈与隐式反馈
在许多实际使用案例中,通常只能访问隐式反馈(例如,视图,点击,购买,喜欢,分享等)。用于spark.ml处理此类数据的方法来自隐式反馈数据集的协同过滤。本质上,该方法不是尝试直接对评级矩阵建模,而是将数据视为代表强度的数字来观察用户的行为(例如,点击次数或某人观看电影所花费的累计时间)。然后,这些数字与观察到的用户偏好的置信度有关,而不是与对商品的明确评分有关。然后,该模型尝试查找可用于预测用户对某项商品的期望偏好的潜在因素。
2.正则化参数的缩放
regParam在解决每个最小二乘问题时,我们根据用户在更新用户因子时生成的评分数或在更新产品因数中获得的产品评分数来缩放正则化参数。这种方法被称为“ ALS-WR”,它regParam减少了对数据集规模的依赖,因此我们可以将从采样子集中学习的最佳参数应用于整个数据集,并期望获得类似的性能。
3.冷启动策略
使用协同过滤模型进行预测时,通常会遇到训练模型期间不存在的用户和/或测试数据集中的项目。这通常在两种情况下发生:
在生产中,对于没有评级历史记录并且尚未对其进行训练的新用户或新项目(这是“冷启动问题”)。
在交叉验证期间,数据在训练集和评估集之间分配。当使用Spark CrossValidator或中的简单随机拆分时TrainValidationSplit,实际上很常见的是遇到评估集中未包含的用户和/或评估集中的项目
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.recommendation.ALS
scala> case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long)
defined class Rating
scala> def parseRating(str: String): Rating = {
| val fields = str.split("::")
| assert(fields.size == 4)
| Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)
| }
parseRating: (str: String)Rating
scala> val ratings = spark.read.textFile("file:///usr/local/spark/data/mllib/als/sample_movielens_ratings.txt").map(parseRating).toDF()
ratings: org.apache.spark.sql.DataFrame = [userId: int, movieId: int ... 2 more fields]
scala> val Array(training, test) = ratings.randomSplit(Array(0.8, 0.2))
training: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [userId: int, movieId: int ... 2 more fields]
test: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [userId: int, movieId: int ... 2 more fields]
scala> val als = new ALS().setMaxIter(5).setRegParam(0.01).setUserCol("userId").setItemCol("movieId").setRatingCol("rating")
als: org.apache.spark.ml.recommendation.ALS = als_afbfc80de8a8
scala> val model = als.fit(training)
model: org.apache.spark.ml.recommendation.ALSModel = als_afbfc80de8a8
scala> model.setColdStartStrategy("drop")
res49: model.type = als_afbfc80de8a8
scala> val predictions = model.transform(test)
predictions: org.apache.spark.sql.DataFrame = [userId: int, movieId: int ... 3 more fields]
scala> val evaluator = new RegressionEvaluator().setMetricName("rmse").setLabelCol("rating").setPredictionCol("prediction")
evaluator: org.apache.spark.ml.evaluation.RegressionEvaluator = regEval_2e35fe5e4779
scala> val rmse = evaluator.evaluate(predictions)
rmse: Double = 1.8669648502700513
scala> println(s"Root-mean-square error = $rmse")
Root-mean-square error = 1.8669648502700513
scala> val userRecs = model.recommendForAllUsers(10)
userRecs: org.apache.spark.sql.DataFrame = [userId: int, recommendations: array>]
scala> val movieRecs = model.recommendForAllItems(10)
movieRecs: org.apache.spark.sql.DataFrame = [movieId: int, recommendations: array>]
scala> val users = ratings.select(als.getUserCol).distinct().limit(3)
users: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [userId: int]
scala> val userSubsetRecs = model.recommendForUserSubset(users, 10)
userSubsetRecs: org.apache.spark.sql.DataFrame = [userId: int, recommendations: array>]
scala> val movies = ratings.select(als.getItemCol).distinct().limit(3)
movies: org.apache.spark.sql.Dataset[org.apache.spark.sql.Row] = [movieId: int]
scala> val movieSubSetRecs = model.recommendForItemSubset(movies, 10)
movieSubSetRecs: org.apache.spark.sql.DataFrame = [movieId: int, recommendations: array>]
七、频繁模式挖掘
挖掘频繁项、项集、子序列或其他子结构通常是分析大规模数据集的第一步,而这是多年来数据挖掘中的活跃研究主题。我们向用户推荐Wikipedia的关联规则学习, 以获取更多信息。
1.FP增长
FP增长算法在Han等人的论文中进行了描述,该算法 挖掘没有候选者的频繁模式,其中“ FP”代表频繁模式。给定交易数据集,FP增长的第一步是计算项目频率并识别频繁项目。与为相同目的设计的类似Apriori的算法不同,FP-growth的第二步使用后缀树(FP-tree)结构对交易进行编码,而无需显式生成候选集,这通常成本较高。第二步之后,可以从FP树中提取频繁项集。
spark.ml的FP-growth实现采用以下超参数:
minSupport:对某个项目集的最低支持,该项目集被确定为频繁使用。例如,如果某项出现在5个事务中的3个,则其支持率为3/5 = 0.6。
minConfidence:生成关联规则的最低置信度。置信度表示发现关联规则为真的频率。例如,如果交易中的项目集X出现4次,X 并且Y仅共发生2次,则规则的置信度为X => Y2/4 = 0.5。该参数不会影响频繁项目集的挖掘,但会指定从频繁项目集生成关联规则的最小置信度。
numPartitions:用于分发作品的分区数。默认情况下,未设置参数,并且使用输入数据集的分区数。
scala> import org.apache.spark.ml.fpm.FPGrowth
import org.apache.spark.ml.fpm.FPGrowth
scala> val dataset = spark.createDataset(Seq("1 2 5","1 2 3 5","1 2")).map(t => t.split(" ")).toDF("items")
dataset: org.apache.spark.sql.DataFrame = [items: array]
scala> val fpgrowth = new FPGrowth().setItemsCol("items").setMinSupport(0.5).setMinConfidence(0.6)
fpgrowth: org.apache.spark.ml.fpm.FPGrowth = fpgrowth_dd559c554e9a
scala> val model = fpgrowth.fit(dataset)
model: org.apache.spark.ml.fpm.FPGrowthModel = fpgrowth_dd559c554e9a
scala> model.freqItemsets.show()
+---------+----+
| items|freq|
+---------+----+
... ...
scala> model.associationRules.show()
+----------+----------+------------------+----+
|antecedent|consequent| confidence|lift|
+----------+----------+------------------+----+
... ... ... ...
scala> model.transform(dataset).show()
+------------+----------+
| items|prediction|
+------------+----------+
... ...
2.前缀跨度
spark.ml的PrefixSpan实现采用以下参数:
minSupport:被视为频繁顺序模式所需的最低支持。
maxPatternLength:频繁顺序模式的最大长度。任何超出此长度的频繁模式都不会包含在结果中。
maxLocalProjDBSize:在开始对投影数据库进行本地迭代之前,前缀投影数据库中允许的最大项目数。该参数应根据执行程序的大小进行调整。
sequenceCol:数据集中序列列的名称(默认为“ sequence”),该列中为空的行将被忽略。
import org.apache.spark.ml.fpm.PrefixSpan
scala> val smallTestData = Seq(Seq(Seq(1, 2), Seq(3)),Seq(Seq(1), Seq(3, 2), Seq(1, 2)),Seq(Seq(1, 2), Seq(5)),Seq(Seq(6)))
smallTestData: Seq[Seq[Seq[Int]]] = List(List(List(1, 2), List(3)), List(List(1), List(3, 2), List(1, 2)), List(List(1, 2), List(5)), List(List(6)))
scala> val df = smallTestData.toDF("sequence")
df: org.apache.spark.sql.DataFrame = [sequence: array>]
scala> val result = new PrefixSpan().setMinSupport(0.5).setMaxPatternLength(5).setMaxLocalProjDBSize(32000000).findFrequentSequentialPatterns(df).show()
20/02/26 20:20:38 WARN fpm.PrefixSpan: Input data is not cached.
+----------+----+
| sequence|freq|
+----------+----+
... ...
八、模型选择和交叉验证
1.模型选择
ML中的一项重要任务是模型选择,或使用数据为给定任务找到最佳模型或参数。可以针对单个Estimator例如LogisticRegression或针对整个Pipeline进行调整,包括多个算法,功能化和其他步骤。用户可以Pipeline一次调整一个整体,而不必分别调整每个元素Pipeline。
2.交叉验证
交叉验证(CrossValidator)是在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预测,并求这小部分样本的预报误差,记录它们的平方加和。确定ParamMap最佳值后,CrossValidator最后使用Estimator的最佳值ParamMap和整个数据集重新拟合。
有关Spark MLlib的内容至此结束,下文将进一步对Spark Graph即Spark图计算的内容做详细介绍。
前文笔记请参考下面的链接:
Spark大数据分布式处理实战笔记(一):快速开始
Spark大数据分布式处理实战笔记(二):RDD、共享变量
Spark大数据分布式处理实战笔记(三):Spark SQL
Spark大数据分布式处理实战笔记(四):Spark Streaming
你可能错过了这些~
“高频面经”之数据分析篇
“高频面经”之数据结构与算法篇
“高频面经”之大数据研发篇
“高频面经”之机器学习篇
“高频面经”之深度学习篇

我就知道你“在看”
