Tensorboard的使用 ---- SummaryWriter类(pytorch版)
tensorboard在pytorch1.1之后就也支持pytorch了
1.tensorboard涉及的类:SummaryWriter
全称是:torch.utils.tensorboard.SummaryWriter
常用的方式就是:
from torch.utils.tensorboard import SummaryWriterutils就是torch中包括的常用的个工具箱集合罢了,很常用
2.官方文档对SummaryWriter描述:
"""Writes entries directly to event files in the log_dir to be
consumed by TensorBoard.
The `SummaryWriter` class provides a high-level API to create an event file
in a given directory and add summaries and events to it. The class updates the
file contents asynchronously. This allows a training program to call methods
to add data to the file directly from the training loop, without slowing down
training.
"""大意是:将条目直接写入 log_dir 中的事件文件以供 TensorBoard 使用。
`SummaryWriter` 类提供了一个高级 API,用于在给定目录中创建事件文件,并向其中添加摘要和事件。 该类异步更新文件内容。 这允许训练程序调用方法以直接从训练循环将数据添加到文件中,而不会减慢训练速度。
3. SummaryWriter使用方法:
重点解释__init__()函数:
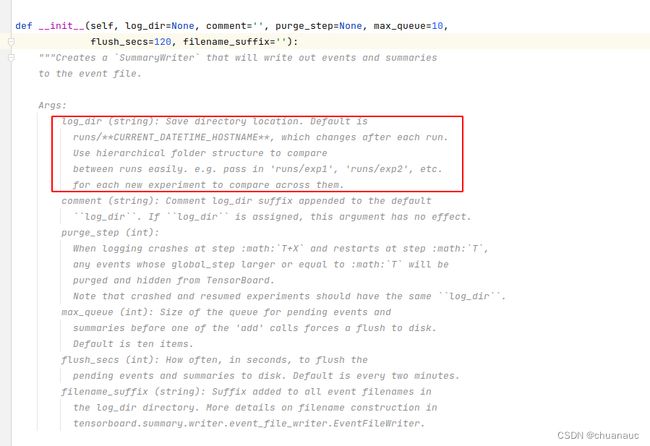
所有的参数都时可选的,
重点介绍一下:
第一个参数 log_dir : 用以保存summary的位置,比如我接下来的例子里,SummaryWriter生成的writer实例的第一个参数都是 ZCH_Tensorboard_Trying_logs ,那么,我的当前代码所在文件夹下方就会出现一个名为 ZCH_Tensorboard_Trying_logs 的文件夹里面装的就是summary
第二个参数是加一些comment
官方文档中还给了点样例,如下:

4. SummaryWriter类中的常用函数 ---- add_scalar()
1. add_scalar()函数的目的是添加一个标量数据(scalar data)到summary中

2. 重要的常用的其实就是前三个参数:
(1)tag:要求是一个string,用以描述 该标量数据图的 标题
(2)scalar_value :可以简单理解为一个y轴值的列表
(3)global_size:可以简单理解为一个x轴值的列表,与y轴的值相对应
3. 代码例子:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("ZCH_Tensorboard_Trying_logs") #第一个参数指明 writer 把summary内容 写在哪个目录下
for i in range(100):
writer.add_scalar("y=x",i,i)
for i in range(100):
writer.add_scalar("y=2*x",2*i,i)
writer.close() #将event log写完之后,记得close()这里,我们用 SummaryWriter 类 构建了一个实例writer,它的第一个参数为:这表明,我们的summary将会被写到名为 ZCH_Tensorboard_Trying_logs 的文件夹下。
因此,运行完后会在当前文件夹目录下多出一个名为 ZCH_Tensorboard_Trying_logs 的文件夹,里面装的就是可以被tensorboard所解释的文件:events.out.tfevents.XXXX.zch.XXXXXX.0

现在,可解释文件已经生成,如何在网页中可视化的看一看呢?
4.可视化展示:
在Pyharm 的 terminal中,键入指令:tensorboard –logdir=XXXX(XXXX就是你要求tensorboard writer把文件写入的那个地方,对于本例来说,即 :ZCH_Tensorboard_Trying_logs)
有的时候,主机可能很多人再用,这个时候,为了防止端口号冲突,我们就可以设定一个特别的主机端口,方法是,将上述命令再多加一个参数:--port=
即,长这样: tensorboard --logdir=ZCH_Tensorboard_Trying_logs --port=6666
5.一个注意:
因为我们每次都在向summary中添加内容,但添加内容的时候,若writer.add_scalar()的第一个参数不变,只改变了之后的描绘数据部分,那么writer.add_scalar()函数就会把此次的数据描绘出的图案 覆盖掉 之前的 第一个参数相同的 那块数据的图案
所以,如果你的代码长这个样子,最终网页上就之会有两个图:
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter("ZCH_Tensorboard_Trying_logs") #第一个参数指明 writer 把summary内容 写在哪个目录下
for i in range(100):
writer.add_scalar("y=x",i,i)
for i in range(100):
writer.add_scalar("lll",2*i,i)
for i in range(100):
writer.add_scalar("lll",5*i,i)
for i in range(100):
writer.add_scalar("lll",9*i,i)
writer.close() #将event log写完之后,记得close()
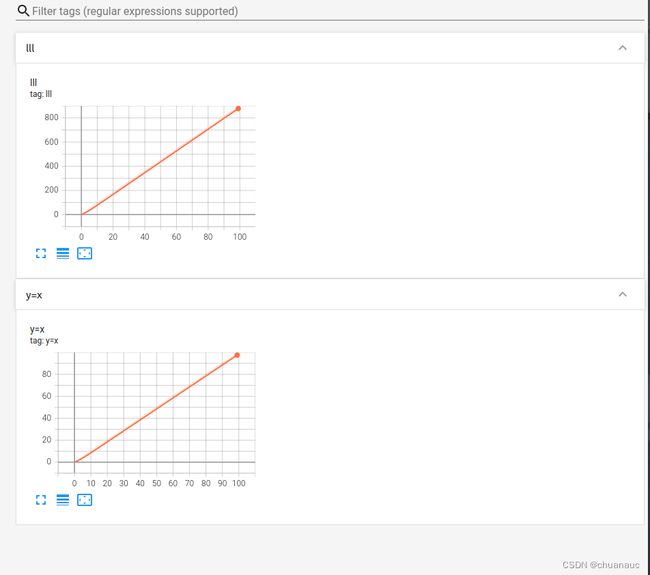
因此,其实我们也可以理解为对于用 add_scalar() 函数 画 标量数据图(scalar data)时,tag 参数有点像是唯一标识的意思。要保证图不被覆盖就要保证 add_scalar() 函数 中 tag参数是唯一的。
6. 两个小提示:
(1)在通过 tensorboard --logdir=ZCH_Tensorboard_Trying_logs –port=6666 指令打开网页后,就可以不用每次对代码修改后就在terminal中执行一次,代码修改完,运行完,直接啥新网页就可以看到更新了
(2)由于每次运行一次,就会在 ZCH_Tensorboard_Trying_logs文件夹中产生一个新的events.out.tfevents.1659857977.zch.34121.0文件,为了防止冗余和出错,简单的做法就是把这些文件都删除再重新运行一下(反正也会生成新的)。
5. SummaryWriter类中的常用函数 ---- add_image()
1.通过官方文档介绍一下这个函数是干吗的:
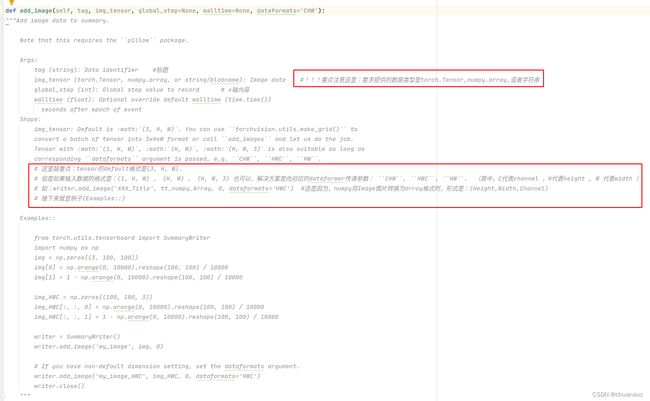
上图把要注意的部分标出来了: 首先明确这是一个向summary中添加图片的函数,然后该函数的参数还是老三样:
tag函数是该图片可视化的时候的标题;
img_tensor参数传入的是代表你要展示的图片的内容,格式必须要转换为 : torch.Tensor ,Numpy.array ,string ;
[注意] 这里特殊强调一下,图片上也标注了,就是如果我们将图片调整为Numpy.array格式,需要在向add_image()函数中传入一个为了对应 Numpy.array() 数据类型 而明确的 dataformats 参数,参数的目的是指明array的内容(具体解释原因见上图)
然后我也执行了一下通过PIL.Image()打开生成的图片是什么类型,再通过Numpy.array()函数转换后的类型又是个啥样:

可以看到,转换成array格式后,此时的数据组织形式就是HWC ,与defualt的数据组织形式不符合,所以add_image()函数中要加参数:dataformats='HWC'
PS : 通过Numpy.array()函数,是最方便的读取到(得到)numpy.array形式的方式之一
2.函数对应的大致的使用方法如下:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
import numpy as np
#add_image()常用来观察训练结果:
img_path = "tttimage.jpg" #文件的相对地址
img = Image.open(img_path)
img.show()
print( type(img) )
#但是,add_image()的第2个参数要求的格式是torch.Tensor ; numpy.array ; string
#转换成numpy.array格式
img = np.array(img)
print( type(img) )
writer = SummaryWriter("ZCH_Tensorboard_Trying_logs") # 第一个参数指明 writer 把summary内容 写在哪个目录下,那么这条语句的意思就是让summary写到当前路径下的 ZCH_Tensorboard_Trying_logs 文件夹下
writer.add_image("test",img,1,dataformats='HWC') #这里一定要注意一下:从PIL利用numpy转换到numpy.array格式,需要在add_image()函数的参数中,利用dataformats明确指定出shape中的每一个维度都表示的啥含义(三维的话就应该是'HWC')
writer.close()3.如何可视化展示的方式同(三)add_scalar()的方法:
再PyCharm的Terminal中执行:tensorboard --logdir=ZCH_Tensorboard_Trying_logs --port=6677
执行结果展示如下hh

4. 同样,与add_scalar()一样,add_image()来添图片同样也是如果tag参数一直就在同一个框中添加,但是,有些情况就是需要在同一个框中添加,那只需要指明这些图片的步骤就好了,比如下例就是同一个框来展示两张图片,只不过通过参数global_step来知名该u图片该tag对应的图片展示框中里面第几个出现
代码如下所示:
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
import numpy as np
writer = SummaryWriter("ZCH_Tensorboard_Trying_logs") # 第一个参数指明 writer 把summary内容 写在哪个目录下,那么这条语句的意思就是让summary写到当前路径下的 ZCH_Tensorboard_Trying_logs 文件夹下
#add_image()常用来观察训练结果:
img_path = "tttimage.jpg" #文件的相对地址
img = Image.open(img_path)
img = np.array(img)
writer.add_image("test",img,1,dataformats='HWC') #global_step = 1 表明:在tag=test中,第一张图片是img=tttimage.jpg
img_path = "2222.jpg" #文件的相对地址
img = Image.open(img_path)
img = np.array(img)
writer.add_image("test",img,2,dataformats='HWC') #global_step = 2 表明:在tag=test中,第一张图片是img=2222.jpg
writer.close()
4. 这里踩个坑:
(1)如果我们在使用writer后忘记了关闭writer,那么,代码运行不会出错,在terminal中打开网页版可视化时,tyerminal中也不会输出报错,但网页展示summary会报错,如下图所示:
这时候优先看看是否已经关闭了writer

(2)我通过用writer.add_scalar()先向summary中添加了一些标量数据,接下来我调用writer,close()函数,将writer关闭了
接着,我再次调用writer.add_image()函数向summary中添加了一些图片,但是此时,由于之前的writer已经被我们关闭了,所以在此重新赋值写入图片的writer(有时)会覆盖之前的操作,即,没有标量数据在网页中被可视化展示了,它已经被add_image()所添加的image覆盖掉了
但以不应定一定会覆盖,很神奇,所以建议大家再添加结束之前还是没必要去close()了