梯度下降——R语言
Gradient Descent
-
- 一、梯度下降
-
- 1. 一元梯度下降
-
- 1> 绘制方程的图像
- 2> 梯度下降
- 3> 修改 θ \theta θ
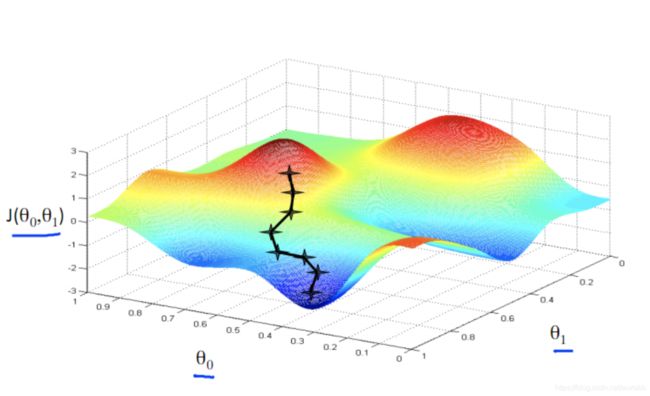
- 2. 多元梯度下降
- 二、梯度下降&线性回归
-
- 1. 批量梯度下降法(BGD)
-
- 1> R语言编写
- 2> R自带的线性回归
- 2. 随机梯度下降(SGD)
-
- 1> SGD的思路
- 2> SGD in R
- 3> SGD 的收敛
- 3. Mini-Batch Gradient Descent
- 三、梯度下降法的一些问题
-
- 1. 计算时间
- 2. 局部最小值问题
- 参考文献
一、梯度下降
梯度的本意是一个向量(矢量),表示某一函数在该点处的方向导数沿着该方向取得最大值,即函数在该点处沿着该方向(此梯度的方向)变化最快,变化率最大(为该梯度的模)。
g r a d f ( x 1 , x 2 , ⋅ ⋅ ⋅ , x n ) = ∇ f ( x 1 , x 2 , ⋅ ⋅ ⋅ , x n ) = { ∂ f ∂ x 1 , ∂ f ∂ x 2 , ⋅ ⋅ ⋅ , ∂ f ∂ x n } gradf(x_1,x_2,···,x_n) = \nabla f(x_1,x_2,···,x_n) = \{ \frac{\partial f}{\partial x_1},\frac{\partial f}{\partial x_2},···,\frac{\partial f}{\partial x_n}\} gradf(x1,x2,⋅⋅⋅,xn)=∇f(x1,x2,⋅⋅⋅,xn)={∂x1∂f,∂x2∂f,⋅⋅⋅,∂xn∂f}
思想:寻找最小值
1. 一元梯度下降
y = ( x − 2.5 ) 2 − 1 d y d x = 2 ∗ ( x − 2.5 ) y = (x-2.5)^2 - 1 \\ \frac{dy}{dx} = 2*(x-2.5) y=(x−2.5)2−1dxdy=2∗(x−2.5)
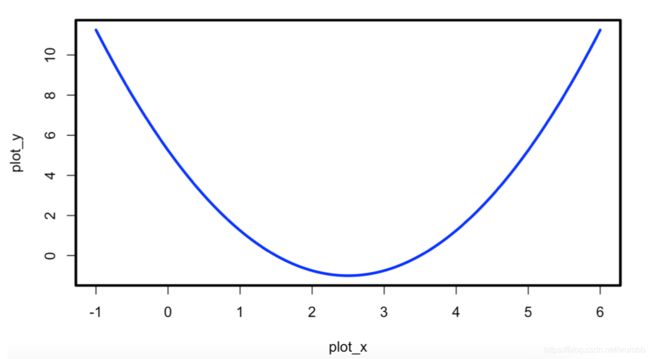
1> 绘制方程的图像
plot_x <- seq(-1, 6, 0.05)
plot_y <- (plot_x-2.5) ^ 2 - 1
par(lwd = 3)
plot(plot_x, plot_y, lty = 1, type = 'l', col = 'blue')
2> 梯度下降
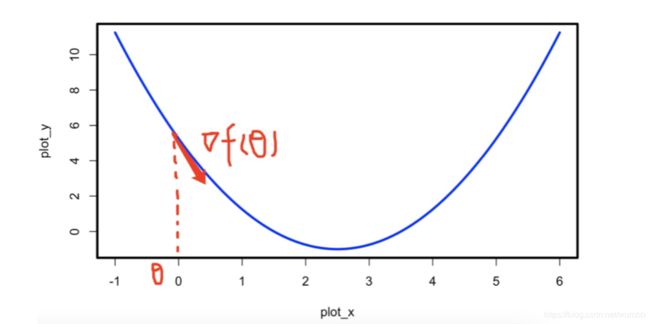
取得极值的必要条件: f ′ = 0 f' = 0 f′=0
∀ η > 0 , ∃ δ > 0 → w h e n 0 < ∣ △ x ∣ < δ , ∣ f ( x + △ x ) − f ( x ) ∣ < η θ n e w = θ o l d − η ∗ f ′ ( θ ) \forall \eta>0, \exist \delta>0 \\ \rightarrow \\when\ 0<|\triangle x|<\delta, |f(x+\triangle x)-f(x)|<\eta\\ \theta_{new} = \theta_{old} - \eta *f'(\theta) ∀η>0,∃δ>0→when 0<∣△x∣<δ,∣f(x+△x)−f(x)∣<ηθnew=θold−η∗f′(θ)
dY <- function(theta){
return(2*(theta - 2.5))
}
Y <- function(theta){
return((theta - 2.5)^2 - 1)
}
eta <- 0.1
epsilon <- 1e-8
theta <- 0.0
theta_history <- vector()
i = 1
while(TRUE){
theta_history[i] = theta
gradient = dJ(theta)
last_theta = theta
theta = theta - eta * gradient
i <- i+1
if (abs(J(theta) - J(last_theta)) < epsilon){
break
}
}
'''
+ theta
[1] 2.499891
+ J(theta)
[1] -1
'''
plot(plot_x, J(plot_x), lty = 1, type = 'l', col = 'blue', lwd = 3)
lines(theta_history, J(theta_history), type = 'o', col = 'red', pch = 16, lty = 1, lwd = 2)
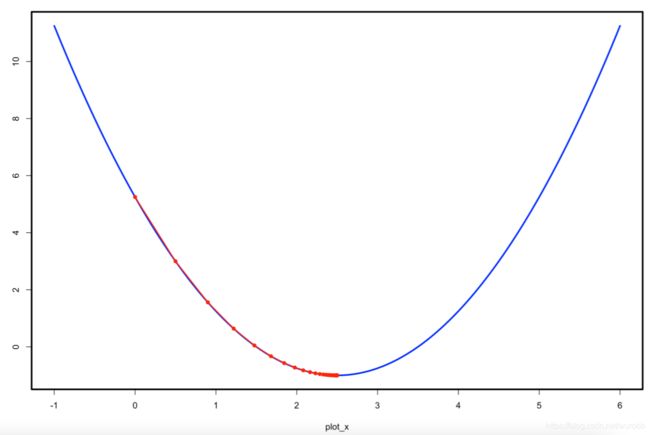
3> 修改 θ \theta θ
gradient_descent <- function(eta = 0.1, epsilon = 1e-8, theta = 0.0){
theta_history <- vector()
i = 1
while(TRUE){
theta_history[i] = theta
gradient = dJ(theta)
last_theta = theta
theta = theta - eta * gradient
i <- i+1
if (abs(J(theta) - J(last_theta)) < epsilon){
break
}
}
plot(plot_x, J(plot_x), lty = 1, type = 'l', col = 'blue', lwd = 3)
lines(theta_history, J(theta_history), type = 'o', col = 'red', pch = 16, lty = 1, lwd = 2)
}
gradient_descent(eta = 0.01)
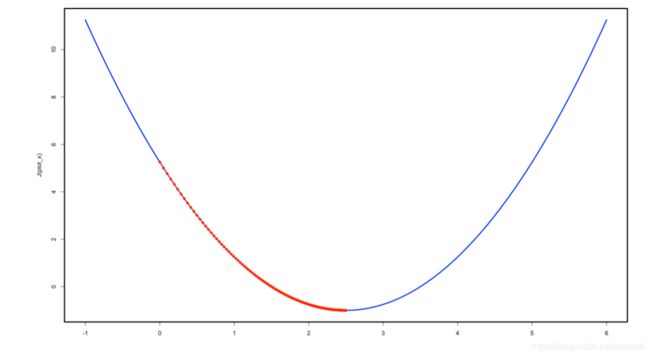
gradient_descent(eta = 0.8)
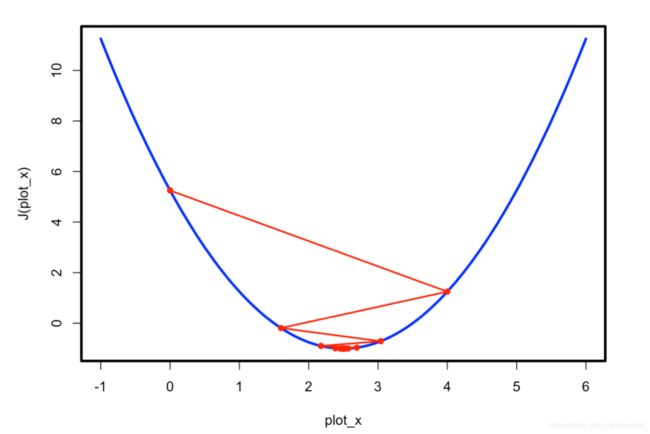
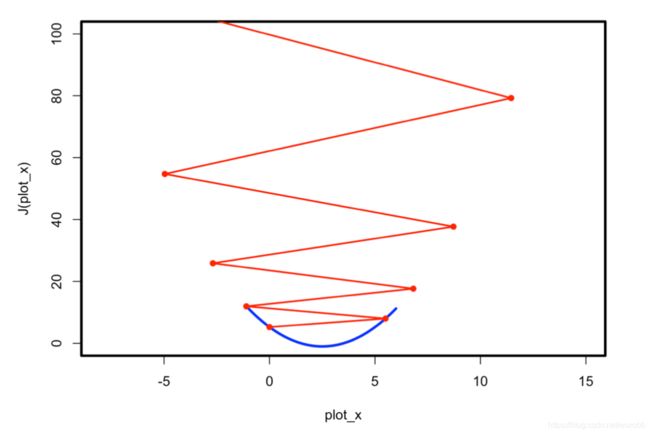
gradient_descent(eta = 1.1)
'''
Error in if (abs(J(theta) - J(last_theta)) < epsilon) { :
missing value where TRUE/FALSE needed
'''
eta <- 1.1
epsilon <- 1e-8
theta <- 0.0
theta_history <- vector()
i = 1
while(TRUE){
theta_history[i] = theta
gradient = dJ(theta)
last_theta = theta
theta = theta - eta * gradient
i <- i+1
if (i > 100){
break
}
}
plot(plot_x, J(plot_x), lty = 1, type = 'l', col = 'blue', lwd = 3, xlim = c(-8,15), ylim = c(0,100))
lines(theta_history, J(theta_history), type = 'o', col = 'red', pch = 16, lty = 1, lwd = 2)
2. 多元梯度下降
取得极值的必要条件: ∇ f = 0 \nabla f = 0 ∇f=0
∀ η > 0 , ∃ δ > 0 → w h e n 0 < ∣ △ x ∣ < δ , ∣ f ( x + △ x ) − f ( x ) ∣ < η θ n e w = θ o l d − η ∗ ∇ \forall \eta>0, \exist \delta>0 \\ \rightarrow \\when\ 0<|\triangle x|<\delta, |f(x+\triangle x)-f(x)|<\eta\\ \theta_{new} = \theta_{old} - \eta *\nabla ∀η>0,∃δ>0→when 0<∣△x∣<δ,∣f(x+△x)−f(x)∣<ηθnew=θold−η∗∇
二、梯度下降&线性回归
1. 批量梯度下降法(BGD)
多元线性回归的最小化问题:
J = a r g m i n ( ∑ 1 n ( y − y ^ ) 2 ) = a r g m i n ( Y − X β ^ ) ′ ( Y − X β ^ ) ∂ J ∂ β ^ = 2 X ′ ( X β ^ − Y ) J = argmin(\sum_{1}^n(y - \hat{y})^2)=argmin(Y-X\hat \beta)'(Y-X\hat \beta) \\ \frac{\partial J}{\partial \hat \beta} = 2X'(X\hat\beta-Y) J=argmin(1∑n(y−y^)2)=argmin(Y−Xβ^)′(Y−Xβ^)∂β^∂J=2X′(Xβ^−Y)
Modify:
J = a r g m i n 1 2 n ( ∑ 1 n ( y − y ^ ) 2 ) = a r g m i n 1 2 n ( Y − X β ^ ) ′ ( Y − X β ^ ) ∂ J ∂ β ^ = 1 n X ′ ( X β ^ − Y ) J = argmin\frac{1}{2n}(\sum_{1}^n(y - \hat{y})^2)=argmin\frac{1}{2n}(Y-X\hat \beta)'(Y-X\hat \beta) \\ \frac{\partial J}{\partial \hat \beta} = \frac{1}{n}X'(X\hat\beta-Y) J=argmin2n1(1∑n(y−y^)2)=argmin2n1(Y−Xβ^)′(Y−Xβ^)∂β^∂J=n1X′(Xβ^−Y)
1> R语言编写
首先先建立一个样本,样本如图所示。
J <- function(beta, X_b, y){
return(sum((y-X_b%*%beta)^2)/(2*dim(X_b)[1]))
}
dJ <- function(beta, X_b, y){
return(2*t(X_b)%*%(X_b%*%beta - y)/(2*dim(X_b)[1]))
}
gradient_descent <- function(X_b, y, initial_beta, eta, n_iters = 1e4, epsilon = 1e-4){
beta = initial_beta
i_iter = 0
while (i_iter < n_iters){
gradient = dJ(beta, X_b, y)
last_beta = beta
beta = beta - eta * gradient
if (abs(J(beta, X_b, y) - J(last_beta, X_b, y)) < epsilon){
break
}
i_iter = 1 + i_iter
}
return(beta)
}
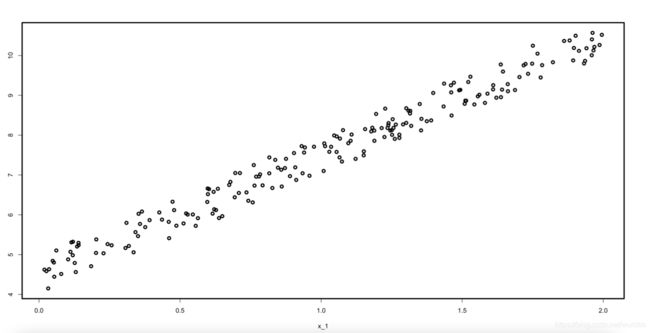
n <- 200
x_1 <- runif(n, 0, 2)
y = x_1 * 3. + 4. + runif(n)
plot(x_1,y)
x_0 <- rep(1, n)
x <- cbind(x_0, x_1)
initial_theta <- c(0,0)
eta = 0.1
theta = gradient_descent(x, y,initial_theta ,eta)
theta
'''
> theta
[,1]
x_0 4.407078
x_1 3.062182
'''
2> R自带的线性回归
fit <- lm(y~x_1)
summary(fit)
'''
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.57461 0.04038 113.28 <2e-16
x_1 2.91995 0.03498 83.48 <2e-16
'''
2. 随机梯度下降(SGD)
观察一下gradient
∇ J = ∂ J ∂ β ^ = 1 n X ′ ( X β ^ − Y ) = 1 n [ ∑ i = 1 n ( Y i − X i β ) ∑ i = 1 n ( Y i − X i β ) ( X i 1 ) ⋅ ⋅ ⋅ ⋅ ⋅ ∑ i = 1 n ( Y i − X i β ) ( X i ( k − 1 ) ) ] \nabla J = \frac{\partial J}{\partial \hat \beta} = \frac{1}{n}X'(X\hat\beta-Y) = \frac{1}{n} \begin{bmatrix} \sum_{i = 1}^n (Y_i - X_i\beta) \\ \sum_{i = 1}^n (Y_i - X_i\beta)(X_{i1}) \\ ····· \\ \sum_{i = 1}^n (Y _i- X_i\beta)(X_{i(k-1)}) \end{bmatrix} ∇J=∂β^∂J=n1X′(Xβ^−Y)=n1⎣⎢⎢⎡∑i=1n(Yi−Xiβ)∑i=1n(Yi−Xiβ)(Xi1)⋅⋅⋅⋅⋅∑i=1n(Yi−Xiβ)(Xi(k−1))⎦⎥⎥⎤
∇ J \nabla J ∇J 中的每一个分量都要经过n次的矩阵运算然后求和,这时候梯度的计算量就变的十分巨大,所以SGD的思想随即被提出。
1> SGD的思路
M o d i f i e d ∇ J : Modified\ \nabla J: Modified ∇J:
1 n [ ∑ i = 1 n ( Y i − X i β ) ∑ i = 1 n ( Y i − X i β ) ( X i 1 ) ⋅ ⋅ ⋅ ⋅ ⋅ ∑ i = 1 n ( Y i − X i β ) ( X i ( k − 1 ) ) ] ≈ [ ( X i β − Y i ) ( X i β − Y i ) X i 1 ⋅ ⋅ ⋅ ⋅ ⋅ ( X i β − Y i ) X i ( k − 1 ) ] = X i ′ ( X i β − Y i ) \frac{1}{n} \begin{bmatrix} \sum_{i = 1}^n (Y_i - X_i\beta) \\ \sum_{i = 1}^n (Y_i - X_i\beta)(X_{i1}) \\ ····· \\ \sum_{i = 1}^n (Y _i- X_i\beta)(X_{i(k-1)}) \end{bmatrix}\approx \begin{bmatrix} (X_i \beta - Y_i)\\ (X_i \beta - Y_i)X_{i1}\\ ·····\\(X_i \beta - Y_i)X_{i(k-1)} \end{bmatrix}= X_i'(X_i\beta - Y_i) n1⎣⎢⎢⎡∑i=1n(Yi−Xiβ)∑i=1n(Yi−Xiβ)(Xi1)⋅⋅⋅⋅⋅∑i=1n(Yi−Xiβ)(Xi(k−1))⎦⎥⎥⎤≈⎣⎢⎢⎡(Xiβ−Yi)(Xiβ−Yi)Xi1⋅⋅⋅⋅⋅(Xiβ−Yi)Xi(k−1)⎦⎥⎥⎤=Xi′(Xiβ−Yi)
经验表面SGD可以趋向于Loss Function的最小值。(证明查看本节3)
很显然,SGD所得到的 m o d i f i e d ∇ f modified\ \nabla f modified ∇f 是不等于真实的 ∇ f \nabla f ∇f 的,如果每一次都按照相同的步长进行梯度下降的话,结果很难达到 ∇ f = 0 \nabla f = 0 ∇f=0 的位置。于是我们思考如何将每一次的梯度变化趋向于真正的梯度,于是提出学习率的概念,随着计算次数的增加,每一步的权重逐渐减小,这样就可以让梯度的最后收敛在真正的极值。
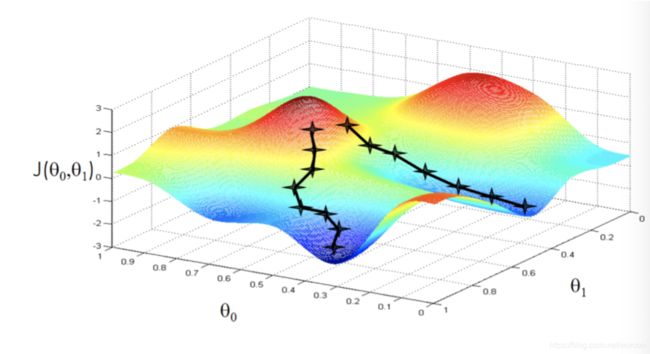
学习率:
η = 1 i _ i t e r s M o d i f y : η = a i _ i t e r s + b = η = t 0 i _ i t e r s + t 1 θ n e w = θ o l d − η ∗ ∇ \eta = \frac{1}{i\_iters}\\ \ \\ Modify:\\ \eta = \frac{a}{i\_iters + b} = \eta = \frac{t_0}{i\_iters + t_1}\\ \theta_{new} = \theta_{old} - \eta *\nabla η=i_iters1 Modify:η=i_iters+ba=η=i_iters+t1t0θnew=θold−η∗∇
2> SGD in R
sgd<- function(X_b, y, initial_theta, n_iters = 5, t0 = 5, t1 = 50){
learning_rate <- function(t){
return(t0/(t + t1))
}
theta = initial_theta
m = dim(x)[1]
for(cur_iter in 1:n_iters){
rand_i = ceiling(runif(1, 0, m))
X = t(X_b[rand_i,])
gradient = dJ(theta, X, y[rand_i])
theta = theta - learning_rate(cur_iter) * gradient
}
return(theta)
}
theta = sgd(x, y, initial_theta, n_iters = dim(x)[1])
theta
'''
> theta
[,1]
x_0 4.443793
x_1 3.027330
'''
theta <- 0.0
theta = sgd(x, y, initial_theta, n_iters = floor(dim(x)[1]))
theta
'''
> theta
[,1]
x_0 3.933352
x_1 3.406223
'''
跑了两次SGD后,发现两个 θ \theta θ 的取值差异较大,这就是是SGD的另一大特点,最后的收敛结果会在真实值附近。
3> SGD 的收敛
观察Loss Function的 ∇ J \nabla J ∇J 和 M o d i f i e d ∇ J Modified\ \nabla J Modified ∇J ,
1 n [ ∑ i = 1 n ( Y i − X i β ) ∑ i = 1 n ( Y i − X i β ) ( X i 1 ) ⋅ ⋅ ⋅ ⋅ ⋅ ∑ i = 1 n ( Y i − X i β ) ( X i ( k − 1 ) ) ] ≈ [ ( X i β − Y i ) ( X i β − Y i ) X i 1 ⋅ ⋅ ⋅ ⋅ ⋅ ( X i β − Y i ) X i ( k − 1 ) ] = X i ′ ( X i β − Y i ) \frac{1}{n} \begin{bmatrix} \sum_{i = 1}^n (Y_i - X_i\beta) \\ \sum_{i = 1}^n (Y_i - X_i\beta)(X_{i1}) \\ ····· \\ \sum_{i = 1}^n (Y _i- X_i\beta)(X_{i(k-1)}) \end{bmatrix}\approx \begin{bmatrix} (X_i \beta - Y_i)\\ (X_i \beta - Y_i)X_{i1}\\ ·····\\(X_i \beta - Y_i)X_{i(k-1)} \end{bmatrix}= X_i'(X_i\beta - Y_i) n1⎣⎢⎢⎡∑i=1n(Yi−Xiβ)∑i=1n(Yi−Xiβ)(Xi1)⋅⋅⋅⋅⋅∑i=1n(Yi−Xiβ)(Xi(k−1))⎦⎥⎥⎤≈⎣⎢⎢⎡(Xiβ−Yi)(Xiβ−Yi)Xi1⋅⋅⋅⋅⋅(Xiβ−Yi)Xi(k−1)⎦⎥⎥⎤=Xi′(Xiβ−Yi)
将 1 n \frac{1}{n} n1 代入矩阵,得到
∇ J ≈ M o d i f i e d ∇ J [ 1 n ∑ i = 1 n ( Y i − X i β ) 1 n ∑ i = 1 n ( Y i − X i β ) ( X i 1 ) ⋅ ⋅ ⋅ ⋅ ⋅ 1 n ∑ i = 1 n ( Y i − X i β ) ( X i ( k − 1 ) ) ] ≈ [ ( X i β − Y i ) ( X i β − Y i ) X i 1 ⋅ ⋅ ⋅ ⋅ ⋅ ( X i β − Y i ) X i ( k − 1 ) ] = X i ′ ( X i β − Y i ) \nabla J \approx Modified\ \nabla J\\ \ \\ \begin{bmatrix} \frac{1}{n}\sum_{i = 1}^n (Y_i - X_i\beta) \\ \frac{1}{n}\sum_{i = 1}^n (Y_i - X_i\beta)(X_{i1}) \\ ····· \\ \frac{1}{n}\sum_{i = 1}^n (Y _i- X_i\beta)(X_{i(k-1)}) \end{bmatrix}\approx \begin{bmatrix} (X_i \beta - Y_i)\\ (X_i \beta - Y_i)X_{i1}\\ ·····\\(X_i \beta - Y_i)X_{i(k-1)} \end{bmatrix}= X_i'(X_i\beta - Y_i) ∇J≈Modified ∇J ⎣⎢⎢⎡n1∑i=1n(Yi−Xiβ)n1∑i=1n(Yi−Xiβ)(Xi1)⋅⋅⋅⋅⋅n1∑i=1n(Yi−Xiβ)(Xi(k−1))⎦⎥⎥⎤≈⎣⎢⎢⎡(Xiβ−Yi)(Xiβ−Yi)Xi1⋅⋅⋅⋅⋅(Xiβ−Yi)Xi(k−1)⎦⎥⎥⎤=Xi′(Xiβ−Yi)
我们观察到 ∇ J \nabla J ∇J 实际上就是 E ( ∇ J ) E (\nabla J) E(∇J) ,而 M o d i f i e d ∇ J Modified\ \nabla J Modified ∇J 是一个样本量为1对样本对 ∇ J \nabla J ∇J 的点估计, X i ′ ( X i β − Y i ) X_i'(X_i\beta - Y_i) Xi′(Xiβ−Yi) 是来自于总体 X ′ ( X β − Y ) X'(X\beta - Y) X′(Xβ−Y) 的一个样本,我们可以得到:
E X i ′ ( X i β − Y i ) = E X ′ ( X β − Y ) E\ X_i'(X_i\beta - Y_i) = E X'(X\beta - Y) E Xi′(Xiβ−Yi)=EX′(Xβ−Y)
这样便可以理解为什么SGD的方法总是会收敛到真实值的附近。同时,这也造成了一个问题,就是样本量为1的样本的估计显而易见是不准确的,这也体现在SGD所得到的结果总是差异过大,根据朴素的统计学思想我们第一想到的就是增加样本,于是梯度下降就得到了第三种方法,批量随机梯度下降(Mini-Batch Gradient Descent)。
更为具体的数学证明请参考Léon Bottou, Frank E. Curtis, Jorge Nocedal的文章Optimization Methods for Large-Scale Machine Learning第四章。
3. Mini-Batch Gradient Descent
批量随机梯度下降(Mini-Batch Gradient Descent),在随机梯度下降的基础上提高了准确性。
∇ J ≈ M o d i f i e d ∇ J 1 n [ ∑ i = 1 n ( Y i − X i β ) ∑ i = 1 n ( Y i − X i β ) ( X i 1 ) ⋅ ⋅ ⋅ ⋅ ⋅ ∑ i = 1 n ( Y i − X i β ) ( X i ( k − 1 ) ) ] ≈ 1 m [ ∑ i = 1 m ( Y i − X i β ) ∑ i = 1 m ( Y i − X i β ) ( X i 1 ) ⋅ ⋅ ⋅ ⋅ ⋅ ∑ i = 1 m ( Y i − X i β ) ( X i ( k − 1 ) ) ] = 1 m X m ′ ( X m β − Y i ) ( m < n ) \nabla J \approx Modified\ \nabla J\\ \ \\ \frac{1}{n}\begin{bmatrix} \sum_{i = 1}^n (Y_i - X_i\beta) \\ \sum_{i = 1}^n (Y_i - X_i\beta)(X_{i1}) \\ ····· \\ \sum_{i = 1}^n (Y _i- X_i\beta)(X_{i(k-1)}) \end{bmatrix}\approx \frac{1}{m} \begin{bmatrix} \sum_{i = 1}^m (Y_i - X_i\beta) \\ \sum_{i = 1}^m (Y_i - X_i\beta)(X_{i1}) \\ ····· \\ \sum_{i = 1}^m (Y _i- X_i\beta)(X_{i(k-1)}) \end{bmatrix}= \frac{1}{m}X_m'(X_m\beta - Y_i) \quad (m< n) ∇J≈Modified ∇J n1⎣⎢⎢⎡∑i=1n(Yi−Xiβ)∑i=1n(Yi−Xiβ)(Xi1)⋅⋅⋅⋅⋅∑i=1n(Yi−Xiβ)(Xi(k−1))⎦⎥⎥⎤≈m1⎣⎢⎢⎡∑i=1m(Yi−Xiβ)∑i=1m(Yi−Xiβ)(Xi1)⋅⋅⋅⋅⋅∑i=1m(Yi−Xiβ)(Xi(k−1))⎦⎥⎥⎤=m1Xm′(Xmβ−Yi)(m<n)
**思考题:R语言编写批量随机梯度下降(Mini-Batch Gradient Descent) **
三、梯度下降法的一些问题
1. 计算时间
计算时间我们在上面的讨论过了,可以用SGD和M-BGD方法解决计算的一部分问题。
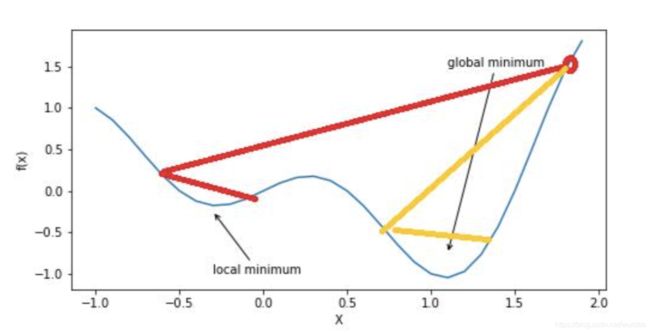
2. 局部最小值问题
SGD恰好能解决一部分的局部最小值的问题,其余方法可以参考SEBASTIAN RUDER的An overview of gradient descent optimization algorithms这篇文章。
网址:https://ruder.io/optimizing-gradient-descent/index.html#momentum
参考文献
[1] SEBASTIAN RUDER, An overview of gradient descent optimization algorithms[J], OPTIMIZATION, 2017
[2] 阿斯顿·张 李沐等,《动手学深度学习》,北京:人民邮电出版社,2019
[3] 李航,《统计学习方法(第2版)》, 北京:清华大学出版社,2019
[4] 日本数学会.数学百科词典:科学出版社,1984
[5] Léon Bottou, Frank E. Curtis, Jorge Nocedal, Optimization Methods for Large-Scale Machine Learning, 2018