图像文字识别:Python批量识别图片中的文字并自动改名
说明:最近学校要求班委收集每个同学青年大学习的学习完成截图,并核实学习情况,故此次想开发一套自动识别图片中的文字,并对其进行改名的程序,从而将人力解放出来去干些更有意义的事情。
任务目标
1.自动识别图像中特殊字段信息
2.批量读入图片
3.自动批量对图片进行命名
开发准备
Tesseract-OCR介绍
开源的OCR识别引擎,高版本识别基于LSTM,其整个处理流程如下:
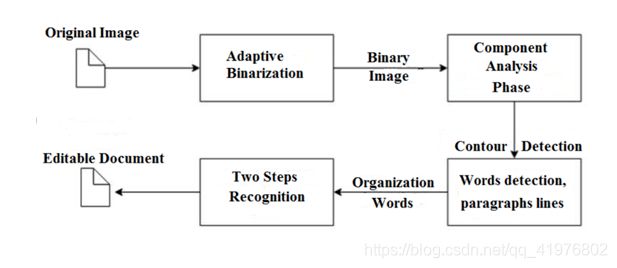
以上图片来源于小白学视觉 的博客
安装Tesseract-OCR Python SDK支持
pip install pytesseract
附:网上找到的Tesseract-OCR下载链接
http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe
下载Tesseract-OCR 5.0.0-alpha.20201127安装包并安装,然后在系统的环境变量中添加对于的安装路径,默认为:
C:\Program Files\Tesseract-OCR
若自定义安装,换为对应路径即可。
验证与测试
安装与配置好OpenCV-Python与Tesseract-OCR之后,需要进一步通过代码验证正确性。打开Pycharm IDE,新建一个python项目与python文件,输入以下代码:
import pytesseract as tess
print(tess.get_tesseract_version())
print(tess.get_languages())
运行结果如下:
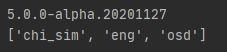
第一行是版本信息,第二行是支持的语言信息,默认只支持英文。'eng’表示支持英文,'chi_sim’表示支持简体中文。若要想也支持中文的识别,需要自行下载对应的语言包,并将其放在Tesseract OCR安装目录的tessdata文件夹下
Tesseract OCR中英文语言包的下载地址
https://github.com/tesseract-ocr/tessdata
下载chi_sim.traineddata文件,并把们放到tessdata文件夹中。此时,环境基本配置完成。
正式开发
1.利用python调用Tesseract进行图片中的文字识别提取
image=cv2.imread("C:/Users/dell/Desktop/test")
text = tess.image_to_string(image_rgb, lang="chi_sim")
print(text)
h, w, c = image.shape
boxes = tess.image_to_boxes(image)
for b in boxes.splitlines():
b = b.split(' ')
image = cv2.rectangle(image, (int(b[1]), h - int(b[2])), (int(b[3]), h - int(b[4])), (0, 255, 0), 2);
cv2.imshow('text detect', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
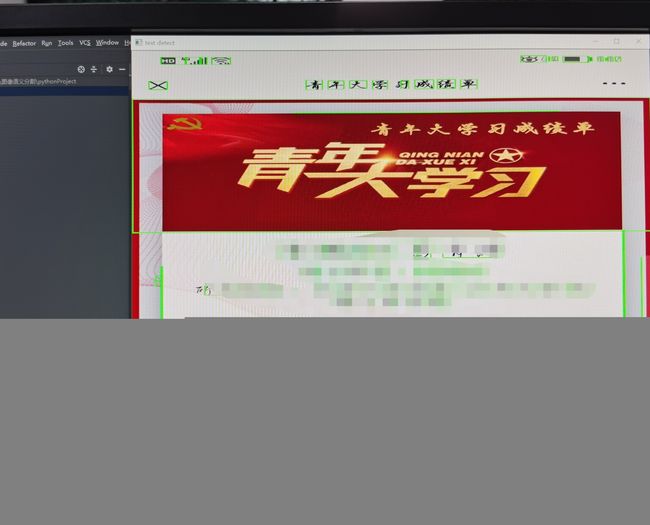

2.对于识别到的文字信息进行提取过滤
def get_str_btw(s, f, b):
par = s.partition(f)
return (par[2].partition(b))[0][:];
nameInfo = get_str_btw(text, "专 硕", "用 户 ")
#除去字符中的无用信息,例如空格等
def remove(string):
string = string.replace(" ", "")
string = string.replace("|", "")
return string.replace("\n", "");
3.文件重命名
ext = os.path.splitext(child)[1]
new_name = nameInfo + ext
print(new_name)
NewInfo = os.path.join('%s/%s' % (filePathC, new_name))
try:
os.rename(child, NewInfo)
except:
print("have the same name")
小结
本项目是本人第一次做图片中的文字识别提取,主要是通过调用了Tesseract实现。
本项目实际使用体验还算不错,但还是有很大的改进空间,例如:若图像中的字体特殊,则识别准确率会大幅下降。
本项目后续有空还会继续开发优化,争取做成一款智能通用化的文字识别提取工具。
本项目参考借鉴了小白学视觉的相关内容,以及部分网上的内容,在此向以上大佬表示感谢!
相关博客详情
说明:若有侵权请联系删除!