ICCV21 - 无监督语义分割《Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals》
文章目录
-
- 原文地址
- 初识
- 相知
- 回顾
原文地址
点我跳转到原文
初识
在无监督设置下,学习密集语义表征(dense semantic representations)是一个非常重要的问题,这引导网络学习像素级的语义表征/嵌入,这对无监督语义分割非常重要。如果解决了这个问题,那么后续直接使用K-Means聚类将每个像素聚集到对应的sematic groups就可以执行语义分割。
目前采用的无监督表征学习(自监督学习)通常学习到的是图像级的表征【比如进行实例判别的对比学习】,无法表征其具有像素判别性。而一个好的像素级表征应该是具有
判别性的,即具有语义判别性,同类物体像素聚集较近,异类像素特征距离较远(对于语义分割任务来说)
无监督语义分割通常是一个端到端的形式【直接学习聚类函数】,而本文将表征学习和聚类的过程进行解耦,如下图所示,先进行像素级表征学习(两阶段-I和II):采用无监督显著性检测得到物体掩码区域object mask proposals,以此作为先验去引导网络学习像素表征;然后再进行聚类/微调进行语义分割。
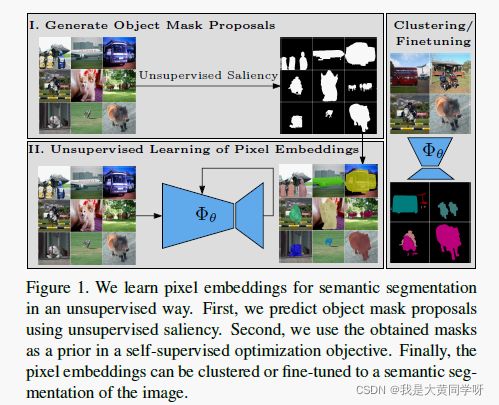
本文提出的方法能够在具有挑战性的数据集上得到应用(比如PASCAL VOC),而之前的方法仅应用于一些小规模数据集。
相知
整体框架:本文的整体架构如图1所示,首先进行两阶段的像素级表征学习,再进行微调聚类。为什么需要两阶段?因为直接进行端到端像素聚类是非常难的,容易只关注低级图像特征,比如颜色,对比度等,丧失特征的语义判别性。而查找一块像素可能聚集在一起的图像区域是比较容易的(利用显著性检测),虽然不能直接进行语义分割,但能够为像素级标注学习提供一个很好的先验。
因此本文提出一个名叫MaskContrast两阶段进行像素表征学习:第一步先获取Mid-level visual gropus,也就是显著性检测的结果(mask)作为先验;第二步采用对比学习学习像素级表征,如图2所示,将相似对象的像素特征在特征空间中靠拢,不同对象的像素特征进行推远。
这个先验也称为
shared pixel ownership:如果一对像素点属于同一个mask区域,那么它们应该聚在一起,即最大化它们之间的一致性。
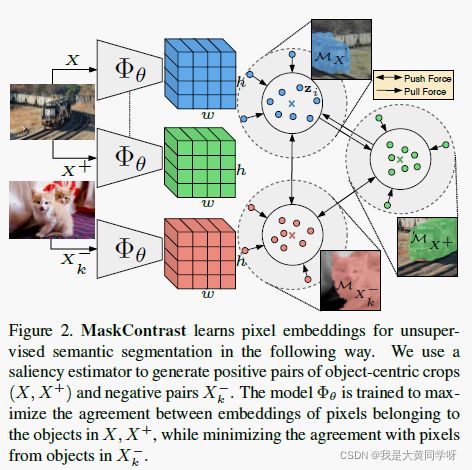
关于为什么要使用mid-level visual gropus作为先验,作者解释了两点好处:① 使用这类mid-level visual gropus,如对象信息,约束了表征(一种regularization方式)。这迫使网络不依赖低级图像信息进行聚类,而学习语义判别性特征。② 提供的物体线索(cue)对语义分割任务具有很高的信息量。
目标掩码区域生成:使用显著性检测生成mask区域,并使其作为mid-level visual gropus,下图展示了两种方法在PASCAL上的预测结果(一个为监督学习训练,一个为非监督训练)。

无监督方法为:Deepusps,监督方法为:Basnet
像素级对比学习:利用上述方法,对于一组图片 X X X就可以得到一组非重叠的目标mask区域 { M 0 , M 1 , . . . , M N } \{M_0,M_1,...,M_N\} {M0,M1,...,MN}。接下来就需要进行像素级表征学习,即学习一个网络,其可以将图像中的每个像素 i i i都映射为一个D维的特征 z i z_i zi(处于归一化超球面上,隐式地规范了网络输出范围【类似于weight decay】)。
对于图像级别的对比学习,公式如下【与SimCLR不太一样,分母没有正样本对】:

基于上式进行修改,使其应用于像素级的对比学习。首先计算每个mask内包含的平均特征作为该object的mean pixel embedding:
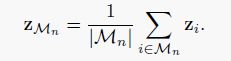
接下来再考虑要达到的两个目的:
- Pull-Force:为了进行
shared pixel ownership,需要拉近属于同一个object的像素级特特征间距离。与对比学习不同的是,这里将属于同一个mask的像素特征直接与对应的mean embedding最大化一致性【与像素个数乘scales linearly】。 - Push-Force:为了避免模型崩塌(所有像素映射到一个常数点),还需要将不同
object的像素级特征推远。与上节一,这里同样也是推远与其他目标的mean embedding。
最后形成的损失函数形式如下,其中像素 i i i属于 M x + M_{x+} Mx+。

应用上式可以使得网络让同一个目标在不同视角下(不同增广,如图2所示)的像素级特征之间最大化一致性,同时最小化不同目标的一致性。
值得注意的是,这个损失函数只对前景区域的像素使用,因为背景区域形式多样,难以聚集。但这样就带来了一个问题:在这个损失约束下,网络没有区分mask内像素特征和mask外像素特征之间的差异,导致同一张图片的像素特征出现崩塌【同一张图像的所有像素特征为一个值】。为了解决这个问题,额外增加了一个linear head预测显著性mask。
实现细节:网络采用ResNet-50为backbone的DeepLab v3,使用Moco v2作为backbone的初始化【之后也报告了采用ImageNet预训练作为初始化的性能】。使用的增广手段与SimCLR一致,会限制增广后的图像至少保留10%区域的目标。采用memory bank存储负样本,尺寸为128。下图展示了一些相关的消融实验:
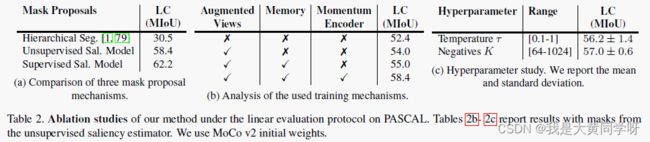
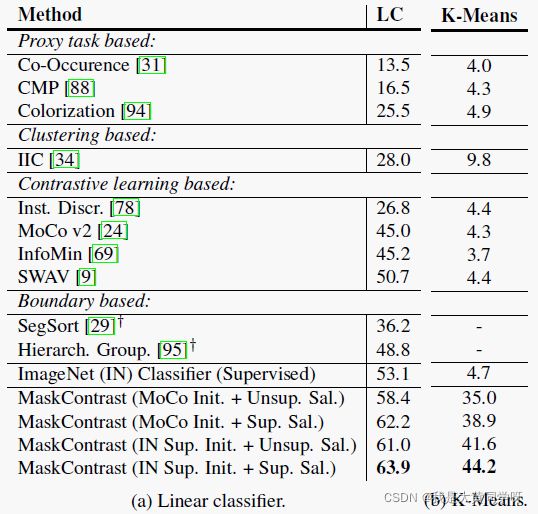
部分实验:这里只放出在PASCAL数据集上进行linear evaluation protocol和进行K-Means的结果,剩余结果看原文
其中
linear evaluation protocol和自监督学习的设置有点像,固定网络权重,额外增加一个线性分类器进行fine-tuning;而K-Means则是执行离线聚类【聚类数K=真实类别数】,直接将像素级特征聚类在语义簇中,然后再用匈牙利算法执行二分匹配将预测的簇与真实类别一一对应起来。
回顾
本文的主要创新点在于:首先引入了显著性检测的结果作为shared pixel ownership先验,在此基础上,构造像素级对比学习使得同一个目标(同一副图像的mask区域)内的所有像素级特征都足够接近,而推远不同目标的像素级特征距离。
提出的方法在性能上超越了之前的方法,并在PASCAL这类数据集上都有较好的表现,但我觉得主要原因是因为他引入了较强的先验监督(显著性检测结果),而之前的方法主要是采用边界 or 超像素信息作为先验。
虽然这个方法达到了不错的效果,但是其局限性也很明显。就是显著性检测只能提供一幅图像中显著物体的mask区域,只能索引到有限的物体,如果任务要求分割图像中更多目标(比如coco数据集),根据这种方法学出来的pixel embedding可能就无法胜任了,这里作者也提出后续可以使用unsupervised object detection这类方法生成mask区域来解决这类问题。
代码地址:https://github.com/wvangansbeke/Unsupervised-Semantic-Segmentation