python实现KNN模型分类预测并验证评估(附代码)
实现功能:
python实现KNN建模,选择最佳K值,对数据样本进行分类预测,并验证评估。
实现代码:
# 导入需要的库
from warnings import simplefilter
simplefilter(action='ignore', category=FutureWarning)
import pandas as pd
from sklearn.model_selection import train_test_split
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.metrics import roc_curve, auc
from sklearn.neighbors import KNeighborsClassifier
def Read_data(file):
dt = pd.read_csv(file)
dt.columns = ['age', 'sex', 'chest_pain_type', 'resting_blood_pressure', 'cholesterol',
'fasting_blood_sugar', 'rest_ecg', 'max_heart_rate_achieved','exercise_induced_angina',
'st_depression', 'st_slope', 'num_major_vessels', 'thalassemia', 'target']
data =dt
print(data.head())
return data
# ===================数据清洗======================
def data_clean(data):
# 重复值处理
print('存在' if any(data.duplicated()) else '不存在', '重复观测值')
data.drop_duplicates()
print('不存在' if any(data.isnull()) else '存在', '缺失值')
data.dropna() # 直接删除记录
data.fillna(method='ffill') # 前向填充
data.fillna(method='bfill') # 后向填充
data.fillna(value=2) # 值填充
data.fillna(value={'resting_blood_pressure': data['resting_blood_pressure'].mean()}) # 统计值填充
# 异常值处理
data1 = data['resting_blood_pressure']
# 标准差监测
xmean = data1.mean()
xstd = data1.std()
print('存在' if any(data1 > xmean + 2 * xstd) else '不存在', '上限异常值')
print('存在' if any(data1 < xmean - 2 * xstd) else '不存在', '下限异常值')
# 箱线图监测
q1 = data1.quantile(0.25)
q3 = data1.quantile(0.75)
up = q3 + 1.5 * (q3 - q1)
dw = q1 - 1.5 * (q3 - q1)
print('存在' if any(data1 > up) else '不存在', '上限异常值')
print('存在' if any(data1 < dw) else '不存在', '下限异常值')
data1[data1 > up] = data1[data1 < up].max()
data1[data1 < dw] = data1[data1 > dw].min()
return data
#========================数据编码===========================
def data_encoding(data):
data = data[["age", 'sex', "chest_pain_type", "resting_blood_pressure", "cholesterol",
"fasting_blood_sugar", "rest_ecg","max_heart_rate_achieved", "exercise_induced_angina",
"st_depression", "st_slope", "num_major_vessels","thalassemia","target"]]
Discretefeature=['sex',"chest_pain_type", "fasting_blood_sugar", "rest_ecg",
"exercise_induced_angina", "st_slope", "thalassemia"]
Continuousfeature=["age", "resting_blood_pressure", "cholesterol",
"max_heart_rate_achieved","st_depression","num_major_vessels"]
df = pd.get_dummies(data,columns=Discretefeature)
df[Continuousfeature]=(df[Continuousfeature]-df[Continuousfeature].mean())/(df[Continuousfeature].std())
df["target"]=data[["target"]]
return df
def data_partition(data):
#======================数据集划分==========================
# 1.4查看样本是否平衡
print(data["target"].value_counts())
# X提取变量特征;Y提取目标变量
X = data.drop('target', axis=1)
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.2,random_state=10)
return X_train, y_train, X_test, y_test
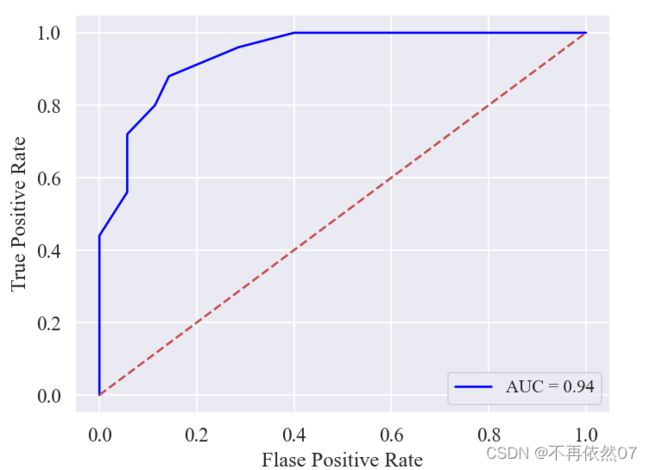
def Draw_ROC(list1,list2):
fpr_model,tpr_model,thresholds=roc_curve(list1,list2,pos_label=1)
roc_auc_model=auc(fpr_model,tpr_model)
font = {'family': 'Times New Roman',
'size': 12,
}
sns.set(font_scale=1.2)
plt.rc('font',family='Times New Roman')
plt.plot(fpr_model,tpr_model,'blue',label='AUC = %0.2f'% roc_auc_model)
plt.legend(loc='lower right',fontsize = 12)
plt.plot([0,1],[0,1],'r--')
plt.ylabel('True Positive Rate',fontsize = 14)
plt.xlabel('Flase Positive Rate',fontsize = 14)
plt.show()
return
# =========================================KNN====================================
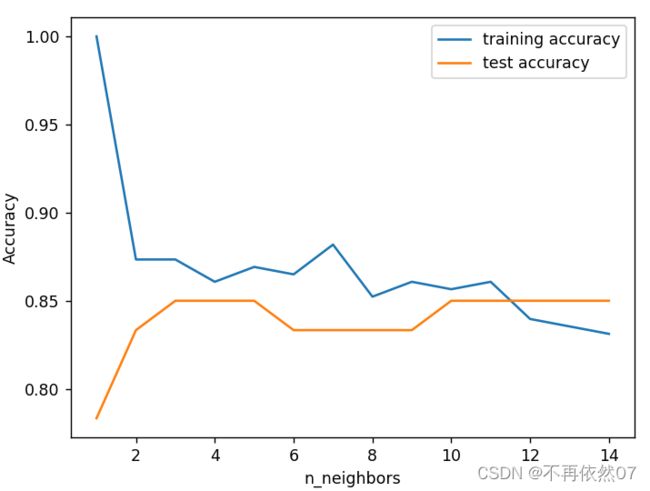
def KNN(X_train, y_train, X_test, y_test):
training_accuracy = []
test_accuracy = []
neighbors_settings = range(1, 15)
for n_neighbors in neighbors_settings:
knn = KNeighborsClassifier(n_neighbors=n_neighbors)
knn.fit(X_train, y_train)
training_accuracy.append(knn.score(X_train, y_train))
test_accuracy.append(knn.score(X_test, y_test))
plt.figure()
plt.plot(neighbors_settings, training_accuracy, label="training accuracy")
plt.plot(neighbors_settings, test_accuracy, label="test accuracy")
plt.ylabel("Accuracy")
plt.xlabel("n_neighbors")
plt.legend()
plt.show()
knn = KNeighborsClassifier(n_neighbors=11)
knn.fit(X_train, y_train)
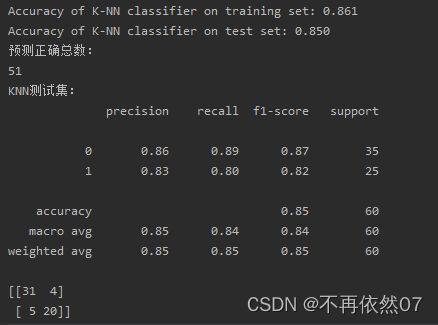
print("Accuracy of K-NN classifier on training set: {:.3f}".format(knn.score(X_train, y_train)))
print("Accuracy of K-NN classifier on test set: {:.3f}".format(knn.score(X_test, y_test)))
predict_target = knn.predict(X_test)
predict_target_prob = knn.predict_proba(X_test)
predict_target_prob_knn = predict_target_prob[:, 1]
print('预测正确总数:')
print(sum(predict_target == y_test))
print('KNN测试集:')
print(metrics.classification_report(y_test, predict_target))
print(metrics.confusion_matrix(y_test, predict_target))
print('KNN训练集:')
predict_Target = knn.predict(X_train)
print(metrics.classification_report(y_train, predict_Target))
print(metrics.confusion_matrix(y_train, predict_Target))
return y_test,predict_target_prob_knn
if __name__=="__main__":
data1=Read_data("F:\数据杂坛\\0504\heartdisease\Heart-Disease-Data-Set-main\\UCI Heart Disease Dataset.csv")
data1=data_clean(data1)
data2=data_encoding(data1)
X_train, y_train, X_test, y_test= data_partition(data2)
y_test,predict_target_prob_knn=KNN(X_train, y_train, X_test, y_test)
Draw_ROC(y_test,predict_target_prob_knn)
实现效果:
喜欢记得点赞,在看,收藏,
关注V订阅号:数据杂坛,获取完整代码和效果,将持续更新!
