深度收缩器:一种提高紧凑神经网络实硬件效率的新压缩范式
文章目录
- 摘要
- 一、引言
- 二、相关工作
- 三、激励灵感和观察
-
- 3.1. 从以前的作品中汲取灵感
- 3.2. 从真实设备分析中激发观察
- 总结
摘要
高效的深度神经网络(DNN)模型配备了紧凑的算子(如深度卷积),在降低DNN的理论复杂性(如权值/操作的总数)的同时保持良好的模型精度方面显示出了巨大的潜力。然而,现有的高效dnn由于其普遍采用的紧凑型操作器的硬件利用率较低,在实现其提高实硬件效率的承诺方面仍然受到限制。在这项工作中,我们为开发实际硬件高效的dnn开辟了一种新的压缩范式,在保持模型精度的同时提高了硬件效率。有趣的是,我们观察到,虽然一些DNN层的激活函数有助于DNN的训练优化和可达到的精度,但它们可以在训练后适当去除,而不影响模型精度。受到这一观察结果的启发,我们提出了一个名为DepthShrinker的框架,该框架通过将现有高效dnn(具有不规则计算模式)的基本构建块缩小为密集的结构块,从而开发硬件友好的紧凑网络,大大提高了硬件利用率,从而提高了实际硬件的效率。令人兴奋的是,我们的DepthShrinker框架提供了硬件友好的紧凑网络,其性能优于最先进的高效dnn和压缩技术,例如,与SOTA通道修剪方法MetaPruning相比,特斯拉V100的精度提高了3.06%,吞吐量提高了1.53倍。
一、引言
最近深度神经网络(DNNs)的突破推动了在现实设备中部署DNNs的需求不断增长。然而,dnn令人生畏的复杂性与通常受限的设备上资源是不一致的。因此,许多旨在提高dnn硬件效率的技术已经被开发出来,包括修剪(Han等人,2015a)、量化(Zhu等人,2016;Zhou等人,2016)和高效DNN模型(Howard等人,2017;谷歌。, 2020)利用紧凑运算符(例如,深度卷积)。然而,由上述技术得到的DNN模型大多需要专用的DNN加速器来实现所需的硬件效率。
同时,在高效DNN设计的趋势和现代计算平台进步之间存在着一个困境:虽然现代计算平台(如gpu和tpu)不断进步,倾向于更高程度的并行计算,但现有的高效DNN模型往往采用轻量级操作,硬件利用率低,因此可实现的硬件效率较低。
例如,深度卷积(Howard等人,2017年)通常被用于紧凑的dnn,如MobileNetV2和efficient net,与标准卷积层相比,深度卷积具有更加不规则的计算模式,由于其数据重用机会减少,很难很好地利用设备上的资源,并限制了现有的高效dnn释放其理论潜力(Chen等人,2019年)。因此,人们越来越有兴趣开发更硬件友好的dnn,提高硬件利用率,以更好地利用现代计算平台中的并行能力(Chen & Zhao, 2018;Elkerdawy等人,2020年;Zhou等人,2021)。
为了解决(1)现有高效dnn的低硬件利用率和(2)现代计算平台的计算并行度不断提高之间的差距,我们提出了一个有趣的问题:“我们如何设计高效dnn,同时享受状态的强大表达能力艺术(SOTA)高效DNN结构和提高现代计算平台的并行计算能力?”受到RepVGG (Ding等人,2021)的启发,RepVGG合并并行分支来构建良好的单分支网络,一个自然的想法是将连续的层合并为一个单层,具有密集的计算模式和提高的硬件利用率。然而,由于相关的激活函数,沿着深度维度合并层是不简单的,需要引入更多的非线性来增强模型的能力。
有趣的是,我们观察到,虽然一些DNN层的激活函数有助于DNN的训练优化,从而达到精度,但它们可以在训练后适当去除,而不影响模型精度。一个令人兴奋的结果是,除去激活函数的其余连续线性操作可以合并为一个单一的线性操作。值得注意的是,如果两个激活函数在一个反向残留块(Sandler et al, 2018), SOTA高效dnn的基本构建块(Sandler et al, 2018;谭乐,2019;吴等,2019;去掉Howard et al, 2019),其两个点卷积层和一个深度卷积层以及相关的残差连接可以合并为一个密集卷积(1)与原始深度卷积大小相同的核和(2)与原始倒置残差块相同的输入/输出通道数量。令人兴奋的是,与核大小为1 × 1的点卷积和原始倒置残块中的深度卷积相比,得到的密集卷积的硬件利用率都有了很大的提高,使得推导出来的DNN在保持原有精度的同时,获得了更高的硬件效率。
我们进行的实验表明,与理论复杂度相同的密集操作相比,现有高效dnn中普遍采用的构建模块在硬件效率上较低。
我们进行的实验表明,与理论复杂性相同的密集操作相比,现有高效dnn中普遍采用的构建模块在硬件效率上较低。
基于上述动机,我们提出了DepthShrinker,它提倡将连续的层合并到一个单一的致密层中,在这些层之间的激活函数被学习为不重要的推断。
DepthShrinker的衍生dnn可以在很大程度上利用现代计算平台的高度并行性,从而提高硬件效率,同时保持原始模型的准确性。
DepthShrinker为强大和硬件高效的dnn开辟了新的视角,可以被视为某种软层修剪,与分层修剪相比,即合并与硬修剪。值得注意的是,DepthShrinker提供的dnn优于SOTA通道和分层修剪技术,例如,与SOTA通道修剪方法MetaPruning相比,特斯拉V100的准确性提高了3.06%,吞吐量提高了1.53倍(Liu等人,2019)。
大量的实验和消融研究证实,DepthShrinker可以(1)在很大程度上推进dnn可实现的精度-效率折衷的前沿领域,(2)作为一种增强技术,提高微小dnn的准确性。
二、相关工作
高效款。各种有效的dnn已经被开发出来。早期有效的dnn主要依靠人类专家的手工设计,例如,MobileNets (Howard等人,2017;Sandler等人,2018)通过深度卷积提高模型效率和准确性权衡,这已成为高效dnn的标准算子。同时,硬件高效算子也被提出(Wu等人,2017;Chen et al, 2020)作为卷积的替代方案。多亏了神经结构搜索(NAS)的巨大成功(zooph & Le, 2016;Zoph等人,2018),通过强化学习自动化高效DNN设计(Tan等人,2019;霍华德等人,2019;Tan & Le, 2019)和可微分搜索(Liu等,2018;吴等,2019;Cai等人,2018)提出。然而,由于现有的高效dnn的基本构建块(如深度卷积)的硬件利用率较低,其硬件效率仍然有限(Howard et al, 2017)。
DNN压缩技术。现有的DNN压缩技术通过修剪来降低模型的复杂性(Han等人,2015b;a;文等,2016;他等人,2018;刘等,2019;He et al, 2017;2020;2019;Dong等人,2017),量化(Courbariaux等人,2015;2016;Rastegari等,2016;傅等,2020;2021a),低秩分解(Yin等,2021;Sainath等人,2013;Nakkiran等人,2015),或动态推理(Teerapittayanon等人,2016;王等,2018;Shen等人,2020),同时努力保持体面的准确性。然而,众所周知,一般的计算平台(如gpu和cpu)在硬件效率方面无法通过低位量化、低秩分解或动态推理的方式充分受益于DNN压缩,在实现修剪的效率提升方面仍然有限。
Layer-wise修剪。与DepthShrinker最相关的工作是分层修剪(Chen & Zhao, 2018;Elkerdawy等人,2020年;Zhou等,2021年;徐等人,2020年),它修剪整个层/块,其动机是,与通道修剪相比,修剪一层在减少硬件延迟方面更有效(徐等人,2020年)。
具体来说,(Chen & Zhao, 2018;Elkerdawy等人,2020)根据他们提出的标准修剪层;(Zhou et al, 2021)和(Xu et al, 2020)分别通过进化搜索和可微优化来确定哪些层/块需要修剪。然而,由于难以恢复修剪后模型的精度,激进的层修剪在大压缩比下不可避免地会出现非琐碎的精度下降。我们的DepthShrinker在训练后将连续的线性运算合并为一个密集运算,而不是硬修剪,由于(1)更好地维护了模型的表达性(2)合并的密集运算的高利用率和较低的延迟,可以获得精度和硬件效率。
三、激励灵感和观察
3.1. 从以前的作品中汲取灵感
具有较高利用率的浅网络有利于真正的硬件效率。最近的工作(Elkerdawy et al, 2020;Xu等人,2020)表明,浅网络倾向于更高程度的并行处理,因此更高的硬件利用率,导致现代计算设备(如gpu)上更好的实际硬件效率,比其计算成本相当的深层网络更好;我们在第3.2节中的分析实验也进一步验证了这一点。
尽管如此,现有的浅网络仍然不能接近深度网络的精确度,这激励我们创新浅网络,提高精确度。
dnn中的线性操作可以合并。众所周知,线性运算是可以正确合并的。
RepVGG (Ding等人,2021)表明,DNN的并行分支中的线性操作可以合并,以提供有竞争力的单分支网络。受此启发,构建强大的紧凑网络的一个自然想法是合并SOTA DNN中连续的层,以减少模型深度。但是,由于激活函数是非线性的,因此无法沿深度维度直接进行分层合并。这促使我们质疑“是否可以适当地删除一些激活函数来进行推断”。
激活函数的作用。基于现有的DNN压缩,我们假设上述问题的答案是肯定的(Han等人,2016;Jacob等人,2018)和培训(Zhou等人,2020;Cai等人,2021)的研究表明,dnn较高的复杂性有利于训练,但可以在推理过程中削减,而不影响准确性。具体来说,迭代修剪(Han等人,2016)和量化感知训练(Jacob等人,2018)用dnn的原始复杂性训练dnn,然后在不影响准确性的情况下对推理模型进行稀疏/量化;同时,(Zhou et al, 2020;Cai等人,2021)通过在训练期间扩大dnn的宽度来提高准确性,而推理期间的模型保持不变。从这些现有技术中得到的一个启发是,激活函数可以被视为增强dnn复杂性和表现力的一个特定模型维度,因此在训练后可以适当地删除一些,而不影响准确性。
3.2. 从真实设备分析中激发观察
由于我们的工作是硬件驱动的,目的是提高实际设备的效率,而不是理论的,我们进行了广泛的实际设备分析实验来验证我们的假设,并获得对设计空间更好的理解,这些实验在本小节中进行了总结。
关键假设/动机。而常用的瓶颈块(He et al, 2016)和更有效的倒置剩余块(Sandler et al, 2018)已经显示令人印象深刻的理论效率和准确性权衡,在相同的计算复杂度下,它们的实际设备效率不如密集的对等体,因为它们更不规则的计算模式导致数据重用减少和硬件利用率降低。
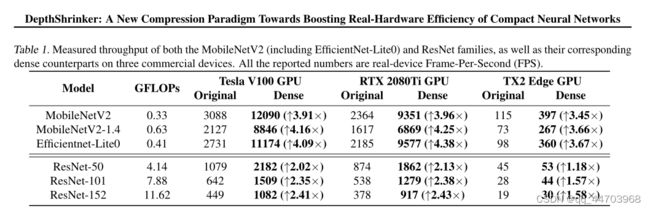
实验设置。在我们的分析中,我们替换了MobileNetV2 (Sandler等人,2018)中的每个构建块(包括efficient entnet - lite0(谷歌。, 2020))和ResNet (He et al, 2016)族,具有一个密集卷积层(1),其内核大小与每个块的第二个卷积层相同,这是瓶颈/反向残留块中惟一的内核大小大于1 × 1的卷积;(2)具有缩放数量的通道,以保持与原始块相同的浮点操作(FLOPs)。我们总结了这两个网络家族的实际设备吞吐量,这两个网络家族具有两种不同类型的基本构建块和它们在ImageNet上的密集对应,如表1所示,分辨率为224 × 224。
考虑设备和测量设置。我们考虑三种商用设备,包括(1)NVIDIA Tesla V100 GPU (NVIDIA。, c), (2) NVIDIA RTX 2080Ti GPU (NVIDIA。, b)和(3)Jetson TX2 Edge GPU (NVIDIA。, a),以覆盖Desktop和边缘gpu。
对于前两个设备,我们采用128的批量大小,以下(Ding等人,2021),最后一个设备采用64的批量大小,以帧每秒(FPS)作为效率度量。
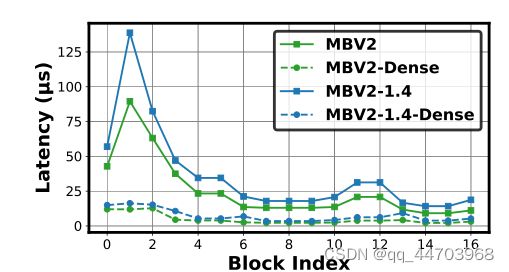
结果与分析。如表1所示,我们可以观察到(1)对于具有相同flop的原始网络,无论模型族和分析设备如何,密集对等体始终能够获得更高的吞吐量。具体来说,在MobileNetV2家族之上的密集卷积对应将特斯拉V100/RTX 2080Ti GPU和TX2 Edge GPU的吞吐量分别提高了3.91× ~ 4.38×和3.45× ~ 3.67×;同样,在ResNet系列的基础上,他们将特斯拉V100/RTX 2080Ti GPU和TX2 Edge GPU的吞吐量分别提高了2.02× ~ 2.43×和1.18× ~ 1.58×。为了进一步理解这一点,我们还在图1中可视化了在RTX 2080Ti GPU上MobileNetV2/MobileNetV2-1.4的块延迟,包括原始块的延迟和相应的密集卷积。结果表明,每个块的密集对应可以持续减少高达88.2%的延迟。
这组分析实验表明:(1)用相同FLOPs的密集操作替换常用的构建块,可以显著提高实际设备的效率,这得益于硬件资源利用率的提高;(2)在MobileNetV2家族之上的吞吐量改善比ResNet家族更为显著,因为前者的深度卷积和在现有高效dnn中广泛采用的深度卷积引入了更多不规则的计算模式,因此我们看到了更明显的用密度大的替换后的改进;(3)吞吐量的提高在不同的设备上得到了一致的观察,并且在特斯拉v100r00/ 2080ti GPU上比TX2 Edge GPU上的提高更大,因为前者具有更高的并行处理程度,有利于密集对应的可实现吞吐量,这表明我们的DepthShrinker有更大的效率提高,符合现代人工智能驱动计算平台的并行化趋势。
备注。硬件利用率以及实际设备效率的提高主要归因于两个方面:(1)从操作角度看,不规则操作的数据重用机会较少,因此需要更多的数据移动成本(Chen等人,2019),例如。在我们的剖面实验中,内核大小为1×1的标准卷积和深度卷积都被替换为内核大小为3×3的密集卷积,这导致了更多的数据重用机会和相同FLOPs下更少的数据移动;(2)从深度/宽度权衡的角度来看,用一个相同FLOPs的密集卷积替换一个积木块,既浅又宽的原始网络,从而有利于在具有越来越高并行度的现代计算平台上运行时提高利用率。我们在附录中进一步研究上述观点(2)的独立影响。C.
总结
为了解决现有的高效DNN由于硬件利用率低而无法实现其提高实际硬件效率的承诺,我们开辟了一个新的压缩范式,并提出了DepthShrinker,通过将不规则块合并为密集操作来开发硬件高效的紧凑型DNN,并大大改善了实际硬件效率。大量的实验验证了我们的DepthShrinker既赢得了通道式修剪的高精确度,又赢得了层式修剪的良好效率,为DNN压缩开辟了一个具有成本效益的层面。