深度学习--Pytorch构建栈式自编码器实现以图搜图任务(以cifar10数据集为例)
Pytorch构建栈式自编码器实现以图搜图任务
-
- 搞清楚pytorch与tensorflow区别
-
- pytorch
- tensorflow
- 搞清楚栈式自编码器的内部原理
- 效果图
- 代码及效果图
-
- 欠完备编码器
- 卷积栈式编码器
- 栈式编码器
本文旨在使用CIFAR-10数据集,构建与训练栈式自编码器,提取数据集中图像的特征;基于所提取的特征完成CIFAR-10中任意图像的检索任务并展示效果。
搞清楚pytorch与tensorflow区别
pytorch
学习文档
pytorch是一种python科学计算框架
作用:
- 无缝替换numpy,通过GPU实现神经网络的加速
- 通过自动微分机制,让神经网络实现更容易(即自动求导机制)
张量:类似于数组和矩阵,是一种特殊的数据结构。在pytorch中,神经网络的输入、输出以及网络的参数等数据,都是使用张量来进行描述的。
张量的基本方法,持续更新
每个变量中都有两个标志:requires_grad volatile
requires_grad:
如果有一个单一的输入操作需要梯度,它的输出就需要梯度。只有所有输入都不需要梯度时,输出才不需要。
volatile:
只需要一个volatile的输入就会得到一个volatile输出。
tensorflow
学习文档
TensorFlow 是由 Google Brain 团队为深度神经网络(DNN)开发的功能强大的开源软件库
TensorFlow 则还有更多的特点,如下:
- 支持所有流行语言,如 Python、C++、Java、R和Go。
- 可以在多种平台上工作,甚至是移动平台和分布式平台。
- 它受到所有云服务(AWS、Google和Azure)的支持。
- Keras——高级神经网络 API,已经与 TensorFlow 整合。
- 与Torch/Theano 比较,TensorFlow 拥有更好的计算图表可视化。 允
- 许模型部署到工业生产中,并且容易使用。
- 有非常好的社区支持。 TensorFlow 不仅仅是一个软件库,它是一套包括 TensorFlow,TensorBoard 和TensorServing 的软件。
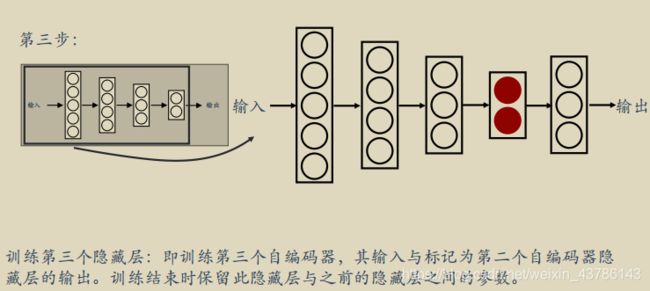
搞清楚栈式自编码器的内部原理

我们构建栈式编码器,用编码器再解码出来的结果和原标签对比进行训练模型,然后用中间编码提取到的特征直接和原图的特征进行对比,得到相似度,实现以图搜图。
整个网络的训练不是一蹴而就的,而是逐层进行的。


效果图
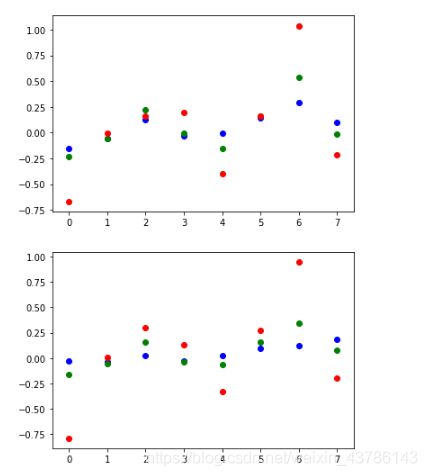
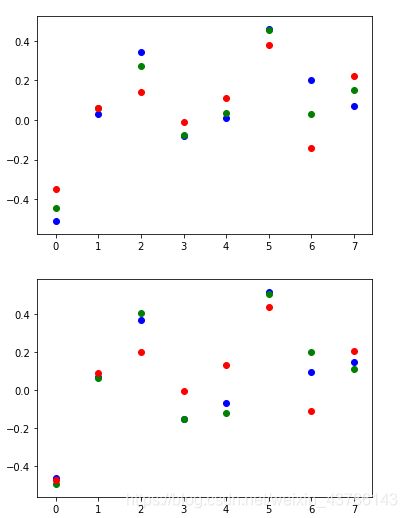
随机取测试集的五张图片,进行以图搜图(TOP8)
提取的分布式特征聚集图像:第一张为原图散点图,第二张以检索的TOP8的TOP1的提取特征散点图为例

代码及效果图
欠完备编码器
# -*- coding: utf-8 -*-
"""
Created on Sat Apr 24 18:37:55 2021
@author: ASUS
"""
import torch
import torchvision
import torch.utils.data
import torch.nn as nn
import matplotlib.pyplot as plt
import random #随机取测试集的图片
import time
starttime = time.time()
torch.manual_seed(1)
EPOCH = 10
BATCH_SIZE = 64
LR = 0.005
trainset = torchvision.datasets.CIFAR10(
root='./data',
train=True,
transform=torchvision.transforms.ToTensor(),
download=False)
testset = torchvision.datasets.CIFAR10(
root='./data',
train=False,
transform=torchvision.transforms.ToTensor(),
download=False)
# dataloaders
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE,
shuffle=True)
testloader = torch.utils.data.DataLoader(testset, batch_size=BATCH_SIZE,
shuffle=True)
train_data = torchvision.datasets.MNIST(
root='./data',
train=True,
transform=torchvision.transforms.ToTensor(),
download=False
)
loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
class Stack_AutoEncoder(nn.Module):
def __init__(self):
super(Stack_AutoEncoder,self).__init__()
self.encoder = nn.Sequential(
nn.Linear(32*32,256),
nn.Tanh(),
nn.Linear(256, 128),
nn.Tanh(),
nn.Linear(128, 32),
nn.Tanh(),
nn.Linear(32, 16),
nn.Tanh(),
nn.Linear(16, 8)
)
self.decoder = nn.Sequential(
nn.Linear(8, 16),
nn.Tanh(),
nn.Linear(16, 32),
nn.Tanh(),
nn.Linear(32, 128),
nn.Tanh(),
nn.Linear(128, 256),
nn.Tanh(),
nn.Linear(256, 32*32),
nn.Sigmoid()
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded,decoded
Coder = Stack_AutoEncoder()
print(Coder)
optimizer = torch.optim.Adam(Coder.parameters(),lr=LR)
loss_func = nn.MSELoss()
for epoch in range(EPOCH):
for step,(x,y) in enumerate(trainloader):
b_x = x.view(-1,32*32)
b_y = x.view(-1,32*32)
b_label = y
encoded , decoded = Coder(b_x)
# print(encoded)
loss = loss_func(decoded,b_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# if step%5 == 0:
print('Epoch :', epoch,'|','train_loss:%.4f'%loss.data)
torch.save(Coder,'Stack_AutoEncoder.pkl')
print('________________________________________')
print('finish training')
endtime = time.time()
print('训练耗时:',(endtime - starttime))
#以图搜图函数
Coder = Stack_AutoEncoder()
Coder = torch.load('Stack_AutoEncoder.pkl')
def search_by_image(x,inputImage,K):
c = ['b','g','r'] #画特征散点图
loss_func = nn.MSELoss()
x_ = inputImage.view(-1,32*32)
encoded , decoded = Coder(x_)
# print(encoded)
lossList=[]
for step,(test_x,y) in enumerate(testset):
if(step == x): #去掉原图
lossList.append((x,1))
continue
b_x = test_x.view(-1,32*32)
b_y = test_x.view(-1,32*32)
b_label = y
test_encoded , test_decoded = Coder(b_x)
loss = loss_func(encoded,test_encoded)
# loss = round(loss, 4) #保留小数
lossList.append((step,loss.item()))
lossList=sorted(lossList,key=lambda x:x[1],reverse=False)[:K]
print(lossList)
plt.figure(1)
# plt.figure(figsize=(10, 10))
trueImage = inputImage.reshape((3, 32, 32)).transpose(0,2)
plt.imshow(trueImage)
plt.title('true')
plt.show()
for j in range(K):
showImage = testset[lossList[j][0]][0] #遍历相似度最高列表里的图
showImage = showImage.reshape((3, 32, 32)).transpose(0,2)
plt.subplots_adjust(left=4, right=5) #好像没起作用
plt.subplots(figsize=(8, 8))
plt.subplot(2,4,j+1)
plt.title("img" + str(lossList[j][0])+"loss:"+str(round(lossList[j][1],5)))
plt.imshow(showImage)
plt.show()
#特征散点图 只显示第一个相似度最高的特征散点图聚集关系
y_li = encoded.detach()
x_li = [x for x in range(8)]
for i in range(len(encoded)):
plt.scatter(x_li, y_li[i],c = c[i])
plt.show()
sim = testset[lossList[j][0]][0].view(-1,32*32)
sim_encoded , _d = Coder(sim)
# print(sim_encoded)
sim_li = sim_encoded.detach() #将torch转为numpy画图要加上detach
x_li = [x for x in range(8)]
for i in range(len(encoded)):
plt.scatter(x_li, sim_li[i],c = c[i])
plt.show()
for i in range(5):
x = random.randint(0, len(testset))
print(x)
im,_ = testset[x]
search_by_image(x,inputImage = im,K = 8)
# break
Epoch : 0 | train_loss:0.0536
Epoch : 1 | train_loss:0.0411
Epoch : 2 | train_loss:0.0293
Epoch : 3 | train_loss:0.0274
Epoch : 4 | train_loss:0.0339
Epoch : 5 | train_loss:0.0337
Epoch : 6 | train_loss:0.0313
Epoch : 7 | train_loss:0.0338
Epoch : 8 | train_loss:0.0279
Epoch : 9 | train_loss:0.0289
finish training
训练耗时: 395.6197159290314





卷积栈式编码器
import numpy as np
import torch
import torchvision
import torch.nn as nn
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
import torch.optim as optim
import os
class layer1(nn.Module):
def __init__(self):
super(layer1,self).__init__()
self.encoder=nn.Sequential(
nn.Conv2d(3, 16, kernel_size=5), # 16*28*28
nn.BatchNorm2d(16),
nn.ReLU(inplace=True),
# nn.MaxPool2d(kernel_size=2,stride=2)#16*15*15
)
self.decoder=nn.Sequential(
nn.ConvTranspose2d(16,3,kernel_size=5,stride=1),
nn.BatchNorm2d(3),
nn.ReLU(inplace=True)
)
def forward(self,x):
encode=self.encoder(x)
decode=self.decoder(encode)
return encode,decode
class layer2(nn.Module):
def __init__(self,layer1):
super(layer2,self).__init__()
self.layer1=layer1
self.encoder=nn.Sequential(
nn.Conv2d(16, 10, kernel_size=5), # 10*24*24
nn.BatchNorm2d(10),
nn.ReLU(inplace=True),
# nn.MaxPool2d(kernel_size=2,stride=2)#10*6*6
)
self.decoder=nn.Sequential(
nn.ConvTranspose2d(10,3,kernel_size=9,stride=1),
nn.BatchNorm2d(3),
nn.ReLU(inplace=True)
)
def forward(self,x):
self.layer1.eval()
x,_=self.layer1(x)
encode=self.encoder(x)
decode=self.decoder(encode)
return encode,decode
class layer3(nn.Module):
def __init__(self,layer2):
super(layer3,self).__init__()
self.layer2=layer2
self.encoder=nn.Sequential(
nn.Conv2d(10, 5, kernel_size=5), # 5*20*20
nn.BatchNorm2d(5),
nn.ReLU(inplace=True)
)
self.decoder=nn.Sequential(
nn.ConvTranspose2d(5,3,kernel_size=13,stride=1),
nn.BatchNorm2d(3),
nn.ReLU(inplace=True)
)
def forward(self,x):
self.layer2.eval()
x,_=self.layer2(x)
encode=self.encoder(x)
decode=self.decoder(encode)
return encode,decode
def train_layer(layer,k):
loss_fn = torch.nn.MSELoss().to(device)
optimizer = optim.Adam(layer.parameters(), lr=0.01)
for epoch in range(10):
i = 0
for data, target in trainloader:
data,target=data.to(device),target.to(device)
encoded, decoded = layer(data)
loss = loss_fn(decoded, data)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if i % 50 == 0:
print(loss)
i += 1
print("epoch:%d,loss:%f"%(epoch,loss))
torch.save(layer.state_dict(), '卷积model/layer%d.pkl'%k)
def search_pic(test_dataset,input_img,input_label,K=8):
model=layer3
loss_fn = nn.MSELoss()
input_img=input_img.to(device)
input_img=input_img.unsqueeze(0)
inputEncode,inputDecoder = model(input_img)
lossList = []
for (i, (testImage,_)) in enumerate(test_dataset):
testImage=testImage.to(device)
testImage=testImage.unsqueeze(0)
testEncode,testDecoder = model(testImage)
enLoss = loss_fn(inputEncode, testEncode)
lossList.append((i, np.sqrt(enLoss.item())))
lossList = sorted(lossList, key=lambda x: x[1], reverse=False)[:K]
input_img=input_img.squeeze(0)
input_img=input_img.to(torch.device("cpu"))
npimg = input_img.numpy()
npimg = npimg /2 +0.5
plt.imshow(np.transpose(npimg, (1, 2, 0))) # transpose()
plt.show()
search_labels=[]
search_dises=[]
k=0
for i,dis in lossList:
search_dises.append(dis)
plt.subplot(1, 8, k + 1)
img=test_dataset[i][0].numpy()
search_labels.append(test_dataset[i][1])
plt.imshow(np.transpose(img, (1, 2, 0)))
k+=1
plt.show()
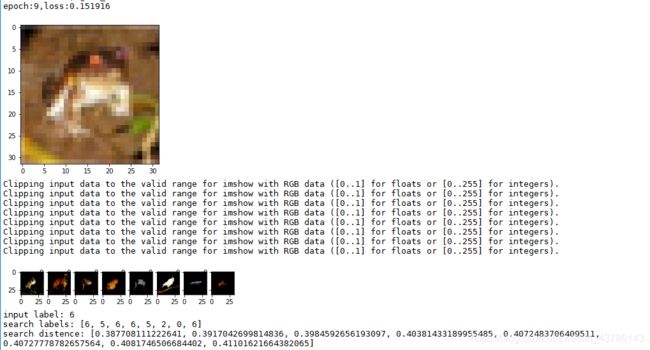
print("input label:",input_label)
print("search labels:",search_labels)
print("search distence:",search_dises)
if __name__ == '__main__':
# device=torch.device("cuda:0")
device = torch.device("cuda"if torch.cuda.is_available() else "cpu")
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_dataset = torchvision.datasets.CIFAR10(root='data/',
train=True,
transform=transform,
download=False)
test_dataset = torchvision.datasets.CIFAR10(root='data/',
train=False,
transform=transform,
download=False)
trainloader = DataLoader(train_dataset, batch_size=256, shuffle=True)
layer1 = layer1().to(device)
if os.path.exists('卷积model/layer1.pkl'):
layer1.load_state_dict(torch.load("卷积model/layer1.pkl"))
else:
train_layer(layer1, 1)
layer2 = layer2(layer1).to(device)
if os.path.exists('卷积model/layer2.pkl'):
layer2.load_state_dict(torch.load("卷积model/layer2.pkl"))
else:
train_layer(layer2, 2)
layer3 = layer3(layer2).to(device)
if os.path.exists('卷积model/layer3.pkl'):
layer3.load_state_dict(torch.load("卷积model/layer3.pkl"))
else:
train_layer(layer3, 3)
search_pic(test_dataset,train_dataset[0][0],train_dataset[0][1])
我把生成和模型和代码会放到资源上,方便大家下载
栈式编码器
import numpy as np
import torch
import torchvision
import torch.nn as nn
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
from torch.utils.data import DataLoader
import torch.optim as optim
import os
class Layer1(nn.Module):
def __init__(self,hidden_size):
super(Layer1, self).__init__()
self.hidden_size=hidden_size
self.encoder = nn.Linear(3 * 32 * 32, hidden_size)
self.decoder = nn.Linear(hidden_size, 3 * 32 * 32)
def forward(self, x):
x = x.view(-1, 3 * 32 * 32)
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
class Layer2(nn.Module):
def __init__(self,layer1,hidden_size):
super(Layer2, self).__init__()
self.layer1=layer1
self.hidden_size=hidden_size
self.encoder = nn.Linear(layer1.hidden_size, hidden_size)
self.decoder = nn.Sequential(
nn.Linear(hidden_size, self.layer1.hidden_size),
nn.Linear(self.layer1.hidden_size,3*32*32)
)
def forward(self, x):
#保证前一层参数不变
self.layer1.eval()
x = x.view(-1, 3 * 32 * 32)
x,_=layer1(x)
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
class Layer3(nn.Module):
def __init__(self,layer2,hidden_size):
super(Layer3, self).__init__()
self.layer2=layer2
self.hidden_size=hidden_size
self.encoder = nn.Linear(layer2.hidden_size, hidden_size)
self.decoder = nn.Sequential(
nn.Linear(hidden_size, self.layer2.hidden_size),
nn.Linear(self.layer2.hidden_size,self.layer2.layer1.hidden_size),
nn.Linear(self.layer2.layer1.hidden_size,3*32*32)
)
def forward(self, x):
#保证前一层参数不变
self.layer2.eval()
x = x.view(-1, 3 * 32 * 32)
x,_=self.layer2(x)
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
def train_layer(layer,k):
loss_fn = torch.nn.MSELoss().to(device)
optimizer1 = optim.Adam(layer.parameters(), lr=0.01)
for epoch in range(20):
i = 0
for data, target in trainloader:
data,target=data.to(device),target.to(device)
encoded, decoded = layer(data)
label = data.view(-1, 3072)
loss = loss_fn(decoded, label)
loss.backward()
optimizer1.step()
optimizer1.zero_grad()
if i % 50 == 0:
print(loss)
i += 1
print("epoch:%d,loss:%f"%(epoch,loss))
torch.save(layer.state_dict(), '全连接model/layer%d.pkl'%k)
def search_pic(test_dataset,input_img,input_label,K=8):
model=layer3
loss_fn = nn.MSELoss()
input_img=input_img.to(device)
input_img=input_img.unsqueeze(0)
inputEncode,inputDecoder = model(input_img)
lossList = []
for (i, (testImage,_)) in enumerate(test_dataset):
testImage=testImage.to(device)
testEncode,testDecoder = model(testImage)
enLoss = loss_fn(inputEncode, testEncode)
lossList.append((i, np.sqrt(enLoss.item())))
lossList = sorted(lossList, key=lambda x: x[1], reverse=False)[:K]
input_img=input_img.squeeze(0)
input_img=input_img.to(torch.device("cpu"))
npimg = input_img.numpy()
npimg = npimg / 2 + 0.5
plt.imshow(np.transpose(npimg, (1, 2, 0))) # transpose()
plt.show()
search_labels=[]
search_dises=[]
k=0
for i,dis in lossList:
search_dises.append(dis)
plt.subplot(1, 8, k + 1)
img=test_dataset[i][0].numpy()
search_labels.append(test_dataset[i][1])
plt.imshow(np.transpose(img, (1, 2, 0)))
k+=1
plt.show()
print("input label:",input_label)
print("search labels:",search_labels)
print("search distence:",search_dises)
if __name__ == '__main__':
# device=torch.device("cuda:0")
device = torch.device("cuda"if torch.cuda.is_available() else "cpu")
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
train_dataset = torchvision.datasets.CIFAR10(root='data/',
train=True,
transform=transform,
download=False)
trainloader = DataLoader(train_dataset, batch_size=256, shuffle=True)
test_dataset = torchvision.datasets.CIFAR10(root='data/',
train=False,
transform=transform,
download=False)
layer1=Layer1(2048).to(device)
if os.path.exists('全连接model/layer1.pkl'):
layer1.load_state_dict(torch.load("全连接model/layer1.pkl"))
else:
train_layer(layer1,1)
layer2=Layer2(layer1,1024).to(device)
if os.path.exists('全连接model/layer2.pkl'):
layer2.load_state_dict(torch.load("全连接model/layer2.pkl"))
else:
train_layer(layer2,2)
layer3 = Layer3(layer2, 512).to(device)
if os.path.exists('全连接model/layer3.pkl'):
layer3.load_state_dict(torch.load("全连接model/layer3.pkl"))
else:
train_layer(layer3, 3)
search_pic(test_dataset,train_dataset[8][0],train_dataset[8][1])