解决ValueError: arrays must all be same length问题
解决ValueError: arrays must all be same length问题
简单来看造成这种问题的原因
import pandas as pd
df = pd.DataFrame({'w1':[1,2],'w1':[3]})
print(df.to_csv('2.csv'))可以发现,是因为w1与w2的长度不匹配造成的,这也体现了PD的严谨性。但是事实上,在我们平时使用的时候会经常想要一次性将多个列表全部写入,而不是一次一个墨迹,所以我在pandas的基础上进行了一个简单的优化,主要是通过生成器重新获取数据,空值填充不匹配长度列表,如
| 变量 | Value |
|---|---|
| w1 | [1,2]故不动 |
| w2 | [3,nan]加入nan |
这样长度就匹配了,当然在提取的时候也要做特殊处理,需要判断isnull
测试代码:
# 引入此模板常规操作可以不再引入pandas
import tpandas as td
table = td.DataFrame([1,2,3],[1,3],[1],name = ['contents2','contents3','contents4'])
#设置索引 不出现多余列,设不设看自己情况
table.set_index('contents3',inplace=True)
# 如果保存中文出乱码可以加上编码utf-8-sig
table.to_excel('2.xlsx',encoding='utf-8-sig')
table.to_csv('2.csv',encoding='utf-8-sig')效果如图
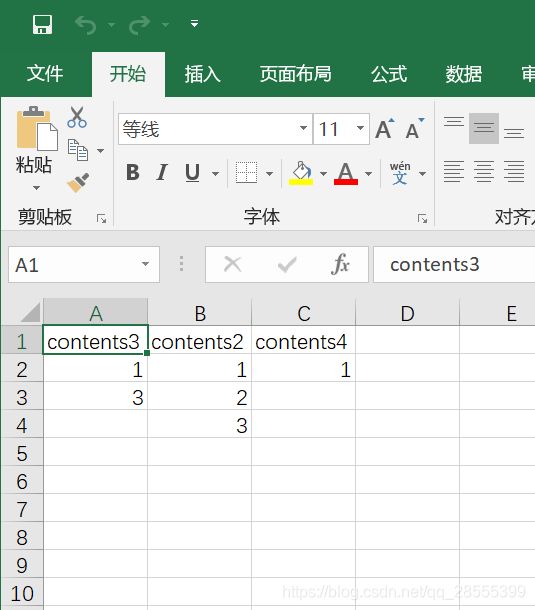
读取更加简单只需要一个路径名即可,默认表单为第一个(sheet_name=0),编码为utf8,可以使用sheet_name与encoding更改
df =td.read_excel(r'2.xlsx')
#df =td.read_excel(r'2.xlsx',sheet_name=0,encoding='utf-8')
q = td.tolist(df.contents2)
print('excel is ',q)
>>>excel is [[1.0, 3.0]]
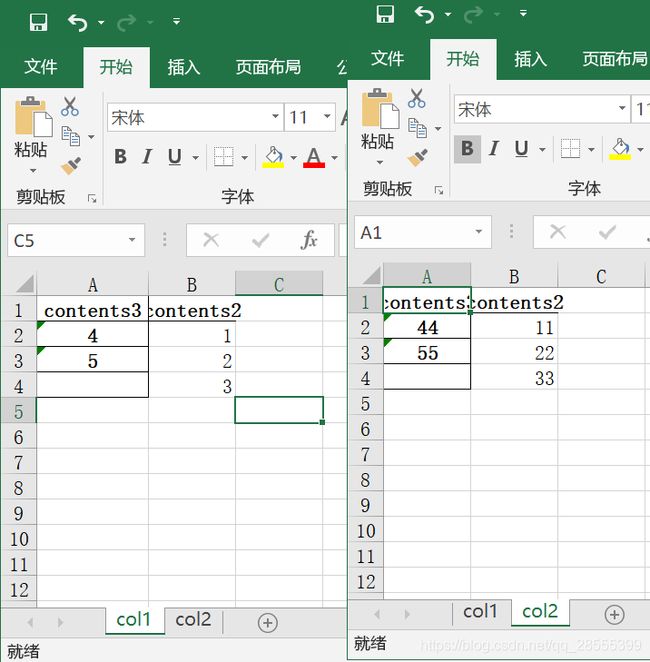
>>>csv is [[1, 2, 3], [1.0, 3.0]]还可以实现一个excel文件同时添加多个表单
DF1 = td.DataFrame([1,2,3],['3','3'],name = ['contents2','contents3'])
DF2 = td.DataFrame([1,2,3],['3','4'],name = ['contents2','contents3'])
DF1.set_index('contents3',inplace=True)
DF2.set_index('contents3',inplace=True)
td.add_sheet(r'2.xlsx',DF1,DF2,sheet_name=['col1','col2'])
效果如图
@github:https://github.com/tcarrt/tpandas
文件test.py为上述测试代码
tpandas.py是作者写的优化模块
如果觉得好用就在GIT里给个星星吧~
(纯个人觉得麻烦才写出此模块)
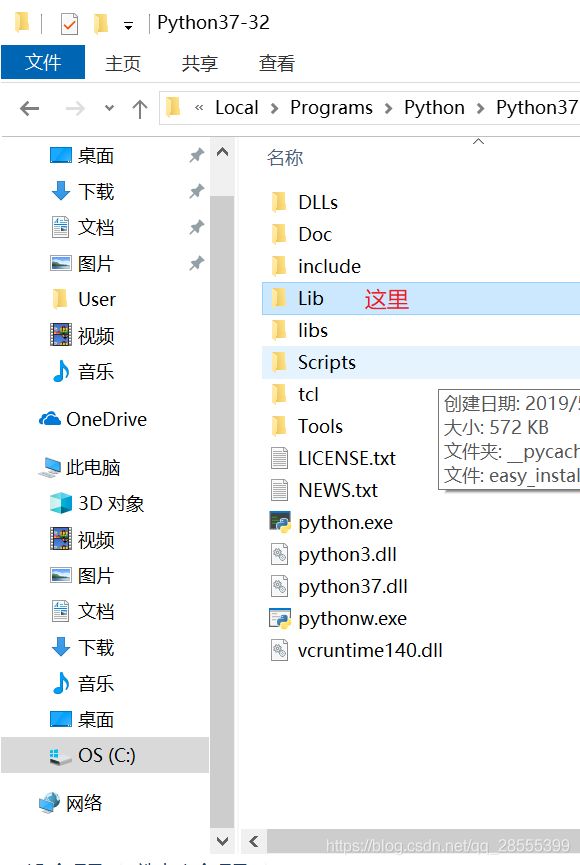
#使用方法
将tpandas.py直接放入python的Lib中,如图
 ####欢迎转载,令请注明出处###
####欢迎转载,令请注明出处###