[Transformer] Deformable DETR:Deformable Transformers for End-to-End Object Detection
2020.10
作者单位:商汤
目标检测:在DETR中加入了Deformable和多尺度特征融合策略
Paper: https://arxiv.org/abs/2010.04159
Code: https://github.com/fundamentalvision/Deformable-DETR
1 简介
DETR可以避免在进行目标检测时手工设计很多组件,但由于transformer注意模块在处理图像特征图时的局限性,导致收敛速度慢,特征空间分辨率有限。
为了解决这些问题,提出了Deformable DETR,其注意力模块只关注参考点周围的一小组关键采样点。可变形的DETR比DETR(特别是在小物体上)可以获得更好的性能,训练周期少10个。
![[Transformer] Deformable DETR:Deformable Transformers for End-to-End Object Detection_第1张图片](http://img.e-com-net.com/image/info8/381e384021634442a11c8054d99ac217.jpg)
![[Transformer] Deformable DETR:Deformable Transformers for End-to-End Object Detection_第2张图片](http://img.e-com-net.com/image/info8/543635de70f344f88d235bf1dc4f65d5.jpg)
2 结构
2.1 可变形注意力模块
只关心参考点周围的一小组关键采样点,而不考虑特征图的空间大小。
通过为每个query分配少量固定数量的key,可以缓解收敛性和特征空间分辨率问题。
给定一个输入特征图x(C*H*W),Zq为content feature,q用于索引Zq的query元素,Pq为一个2D参考点,可形变注意力如下计算:
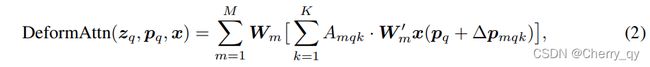
m表示attention head的索引,k表示采样key的索引,K是总的采样key的数量。
ΔPmqk和Amqk分别表示第m个attention head中第k个采样点的采样偏移和注意力权重。
Amqk在[0,1]范围内,对k求和为1。
ΔPmqk是一个范围无约束的二维实数。
由于Pq+ΔPmqk不是整数,按照双线性差值方法计算x(Pq+ΔPmqk)。
ΔPmqk和Amqk都是通过对Zq进行线性投影得到的。
在实现中,Zq被提供给一个3MK通道的线性投影运算操作,其中前2MK通道对采样偏移量Pmqk进行编码,其余的MK通道被提供给softmax运算符以获得注意力权重Amqk。
2.2 多尺度可变形注意力模块
![[Transformer] Deformable DETR:Deformable Transformers for End-to-End Object Detection_第3张图片](http://img.e-com-net.com/image/info8/7a6a5d9a3aa04a3a94c7f782f80cec5d.jpg)
m用于索引attention head,l用于索引输入特征层,k用于索引采样点。
ΔPmqk和Amqk分别表示第l特征层,第m个attention head中第k个采样点的采样偏移和注意力权重。
Amqk在[0,1]范围内,对l和k两重求和为1。
使用归一化的坐标Pq,(0,0)表示左上角,(1,1)表示右下角。
φl(Pq)将归一化坐标重新缩放到第l层的输入特征图的尺度。
多尺度可形变注意力和先前的单尺度版本很相似,只不过它从多尺度feature maps中选取LK点,而不是从单尺度feature maps中选取K点。
2.3 可变形Transformer Encoder
我们使用提出的多尺度可形变注意力模块代替DETR当中处理特征图的transformer注意力模块。
Encoder的输入和输出都是相同分辨率的多尺度特征图。
在Encoder中,我们从ResNet中提取C3到C5stage(通过1×1卷积进行变换)的多尺度(三级)特征图 {xl}。最低分辨率的特征图 xL是在C5最后进行3×3 stride 2卷积得到的,记为C6。所有的多尺度特征图的通道 C=256。
本文并没有使用FPN中自上而下的架构,因为多尺度可形变注意力可以在多尺度特征图之间交换信息。
多尺度特征图的构建如下图。
![[Transformer] Deformable DETR:Deformable Transformers for End-to-End Object Detection_第4张图片](http://img.e-com-net.com/image/info8/791a243756f7400faae79e8ac5e5e7d9.jpg)
在Encoder的多尺度可变形注意模块应用中,输出是与输入具有相同分辨率的多尺度特征图。
key元素和query元素都是来自多尺度特征图的像素。对于每个query像素,参考点就是它自己。
为了分辨每个query像素在哪个特征层,除了位置嵌入之外,我们还在特征表示中添加了一个尺度级别的向量,表示为el。和位置嵌入的固定编码不同,尺度级特征向量{el} l =1~L是随机初始化的,并与网络共同训练。
2.4 可形变transformer解码器
在解码器中有交叉注意力和自注意力模块,这两种类型的注意力模块的query元素都来自object queries。
在交叉注意力模块中,object queries从特征图中提取特征,key元素来自encoder的输出特征图。
在自注意力模块中,object queries相互交流,key元素来自object queries。
由于可变形注意模块是将卷积特征图作为key元素处理,因此我们只将每个交叉注意模块替换为多尺度可变形注意模块,而保留自注意模块不变。
对于每个object queries,参考点Pq的2D归一化坐标由其object query embedding来预测,通过一个可学习的线性映射以及一个sigmoid函数。
因为多尺度可形变注意模块只提取参考点周围的图片特征,我们让detection head将边框预测作为参考点的相对偏移量。参考点作为边框中心的初始猜测,detection head预测参考点的相对偏移量。
这样,学习到的decoder注意力会与预测的边界框有很强的相关性,也加快了训练的收敛速度。
通过使用可形变注意力模块代替DETR中的transformer注意力模块,我们建立了一个有效且快速收敛的检测系统,称为Deformable DETR
2.5 Deformable DETR中额外的改进和提升
Deformable DETR为我们开发端到端目标检测器的各种变体提供了可能性,受益于快速收敛,以及计算和内存效率。
Iterative Bounding Box Refinement. 这是受到光流估计中迭代改进的启发。
我们建立了一个简单并且有效的迭代边框矫正机制来提高检测性能。
每个解码器层根据前一层的预测来细化边界框。
Two-Stage Deformable DETR. 在原始的DETR中,解码器中的object queries与当前图像无关。受two-stage检测器的启发,我们探索了一个Deformable DETR的变种来生成候选区域来作为first-stage。生成的候选区域会送进解码器作为object queries以进一步优化矫正,从而形成two-stage Deformable DETR。
在first-stage中,为了实现高召回的候选区域,多尺度特征图中的每个像素将作为一个object query。然而,对于解码器中的每个自注意力模块,其复杂度随查询次数呈二次增长,直接设置像素为object queries会带来不可接受的计算和内存花费。为了避免这个问题,我们移除了解码器并形成了一个只有编码器的Deformable DETR来生成候选区域。其中,每个像素被分配为一个目标查询,直接预测一个边界框。选择得分最高的边界框作为区域建议。在将区域建议提交到第二阶段之前,不应用NMS。
3 对比
![[Transformer] Deformable DETR:Deformable Transformers for End-to-End Object Detection_第5张图片](http://img.e-com-net.com/image/info8/c28c28cc6f8f4364b652bcd66c956fda.jpg)
![[Transformer] Deformable DETR:Deformable Transformers for End-to-End Object Detection_第6张图片](http://img.e-com-net.com/image/info8/1318d719e301463ea11d256f1bb3c575.jpg)