【深度学习】ToMe:我的方法无需训练即可加速 ViT 模型|搞懂Transformer系列
作者丨科技猛兽
编辑丨极市平台
导读
这篇文章提出了一种无需训练即可加速 ViT 模型,提高吞吐量的方法 Token Merging (ToMe)。ToMe 通过一种轻量化的匹配算法,逐步合并 ViT 内部的相似的 tokens,实现了在基本不损失性能的前提下,大幅提升 ViT 架构的吞吐量。
本文目录
51 无需训练,Token 合并打造更快的 ViT 架构
(来自佐治亚理工学院,Meta AI)
51.1 ToMe 论文解读
51.1.1 背景和动机
51.1.2 Token Merging 的基本思路
51.1.3 什么样的 tokens 是相似的
51.1.4 Token Merging 的具体步骤:二分软匹配
51.1.5 Token Merging 的后续操作:调节注意力权重
51.1.6 其他消融实验结果
51.1.7 图像实验结果
51.1.8 视频实验结果
Transformer 是 Google 的团队在 2017 年提出的一种 NLP 经典模型,现在比较火热的 Bert 也是基于 Transformer。Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
51 无需训练,Token 合并打造更快的 ViT 架构
论文名称:Token Merging: Your ViT But Faster
论文地址:https://arxiv.org/pdf/2210.09461.pdf
51.1.1 背景和动机
与卷积神经网络 (CNN) 相比,视觉 Transformer 模型 (ViT) 有一系列优良的性质,比如:
Transformer 模型的 Attention 模块和 MLP 模块主要有矩阵乘法这种可以加速的操作构成。
Transformer 支持一些性能强大的自监督学习任务 (掩码图像建模 MAE 等等)。
Transformer 适配多种模态的输入数据 (图片,文本,音频等)。
Transformer 对于超大规模数据集 (ImageNet-22K) 的泛化性好,预训练之后的模型在下游任务中 (比如 ImageNet-1K 图像分类任务) 表现卓越。
但是在资源受限的边缘设备 (如手机和无人机) 上实际运行 Transformer 不太友好,因为 Transformer 模型又相对较大的延时。一种常见的加速视觉 Transformer 模型的方法是对 token (图片 Patch) 进行剪枝。比如 DynamicViT[1],AdaViT[2],A-ViT[3],SPViT[4]等。这些 token Pruning 方法虽然在精度方面能够实现不错的效果,但是 token 剪枝的缺点有:
需要额外的训练过程,对资源不友好。
token 剪枝限制了模型的实用性,当 token 数量随着输入的变化而发生变化时,无法进行批处理 (Batch Inference)。为了解决这个问题,大多数 token 剪枝的工作借助了 Mask,对冗余的 token 进行遮挡。但是这样的做法并没有真正剪去这些冗余的 token,使得这些方法并不能在实际业务中真正加速。
token 剪枝带来的信息损失限制了可以允许剪枝的 token 数量。
另一种加速 ViT 的做法是对 token (图片 Patch) 进行融合。比如 Token Pooling[5],Token Learner[6]。和本文方法最接近的 Token Pooling 使用了一个缓慢的基于 k-means 的方法,但是速度较慢,不适用于现成的模型。
本文希望做一个无需训练并且兼顾性能-速度权衡的 token 融合方法。因为其无需训练的优良属性,对于大模型将会非常友好。在训练过程中使用 ToMe,可以观察到训练速度增长,总训练时间缩短了一半。
51.1.2 Token Merging 的基本思路
Token Merging 的基本思路是在一个 ViT 模型中间插入一些 token merging 的模块, 希望把这些模块植入 ViT 以后, 训练和推理的速度都有提升。基本作法是在每一个层之后减少 个 token, 那么一个有 层的 Transformer 模型从头到尾减少的 token 数量就是 。这个 值越高, 减少的 token 数量就越多, 但是精度也会越差。而且值得注意的是, 无论一张输入图片有多少个 tokens, 都会减少 个 token, 而不是像上文的 token 剪枝算法那样使得 token 的数量动态变化。为什么这么设计呢? 原因就是如上文所述当 token 数量随着输入的变化而发生变化时, 无法进行批处理 (Batch Inference), 使得这些方法并不能在实际业务中真正加速。
如下图1所示是 Token Merging 的示意图,ToMe 的位置被插在 Attention 模块和 MLP 模块之间,因为作者希望借助 Attention 中的特征帮助决定该去融合哪些 tokens。
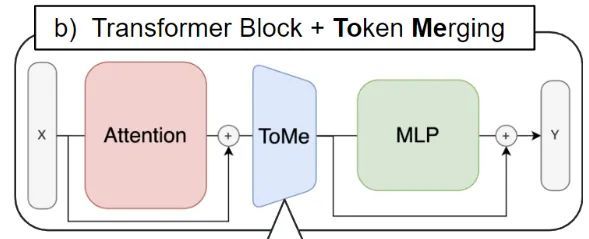 图1:Token Merging 的位置
图1:Token Merging 的位置
51.1.3 什么样的 tokens 是相似的
根据上面的基本思路,要考虑的第1个问题是我们应该合并哪些 tokens,即什么样的 tokens 可以被认为是相似的 tokens?一种比较直接的想法是距离比较近的 tokens 是相似的,但是并不是最优解。
如下图2所示为消融实验结果,意在探索什么样的 tokens 是相似的。消融实验使用的模型是 MAE 训练策略下得到的 ViT-L/16 预训练模型 (acc: 85.96%, im/s: 93.3),不再进行任何额外训练。使用合并,这将在网络的24层上逐渐移除 98% 的 tokens。
如左图所示为使用什么特征衡量相似度,作者发现使用 Key 来衡量相似度对性能最友好,因为 Attention 模块中的 Key 已经总结了每个 token 中包含的信息,以便用于 Attention 中的 dot-product 相似度。如右图所示为使用什么距离衡量相似度,作者发现使用余弦距离来衡量 token 之间的相似度可以获得最好的精度-速度权衡。
如下图3所示,把不同 head 的 Key 进行取平均操作,而不是拼接在一起,更有助于效率。
 图2:什么样的 tokens 是相似的。左:使用什么特征衡量相似度;右:使用什么距离衡量相似度
图2:什么样的 tokens 是相似的。左:使用什么特征衡量相似度;右:使用什么距离衡量相似度  图3:把不同 head 的 Key 进行取平均操作,而不是拼接在一起,可以提高效率
图3:把不同 head 的 Key 进行取平均操作,而不是拼接在一起,可以提高效率
51.1.4 Token Merging 的具体步骤:二分软匹配
在定义了 tokens 的相似性之后,下面就需要一种快速的方法来确定要匹配哪些 tokens,以便在实际运行时能够快速将 tokens 的数量减少 。这个过程对于延时的要求很高,因为在 ViT 模型中要对可能上千个 tokens 执行匹配 次,所以这个匹配算法的运行时间必须完全可以忽略不计。
作者在这里为什么不用聚类算法 (clustering),而是匹配算法 (matching) 呢?
答: 因为聚类算法没有限制每个类的具体数量,因此无法做到在每层精确地减少 个 tokens。而匹配算法不同,匹配算法可以做到精确地匹配 对 tokens,并把它们融合在一起。这样一来,就做到了在每层精确地减少 个 tokens。
下面是作者在本文提出的二分软匹配算法 (Bipartite Soft Matching),如下图4所示。
 图4:Token Merging 的步骤:二分软匹配
图4:Token Merging 的步骤:二分软匹配
把 ToMe 模块输入的所有 tokens 分为相同大小的 2 个集合 。
把从集合 中的每个 token 到 中与其最相似的 token 画一条边。
只留下最相似的 条边, 其余删掉。
融合仍然相连的 条边 (特征取均值)。
把这两个集合拼在一起, 得到 ToMe 模块的融合结果。
这个算法的 PyTorch 代码如下:
def bipartite_soft_matching(
metric: torch.Tensor,
r: int,
class_token: bool = False,
distill_token: bool = False,
) -> Tuple[Callable, Callable]:
"""
Applies ToMe with a balanced matching set (50%, 50%).
Input size is [batch, tokens, channels].
r indicates the number of tokens to remove (max 50% of tokens).
Extra args:
- class_token: Whether or not there's a class token.
- distill_token: Whether or not there's also a distillation token.
When enabled, the class token and distillation tokens won't get merged.
"""
protected = 0
if class_token:
protected += 1
if distill_token:
protected += 1
# We can only reduce by a maximum of 50% tokens
t = metric.shape[1]
r = min(r, (t - protected) // 2)
if r <= 0:
return do_nothing, do_nothing
with torch.no_grad():
metric = metric / metric.norm(dim=-1, keepdim=True)
a, b = metric[..., ::2, :], metric[..., 1::2, :]
scores = a @ b.transpose(-1, -2)
if class_token:
scores[..., 0, :] = -math.inf
if distill_token:
scores[..., :, 0] = -math.inf
node_max, node_idx = scores.max(dim=-1)
edge_idx = node_max.argsort(dim=-1, descending=True)[..., None]
unm_idx = edge_idx[..., r:, :] # Unmerged Tokens
src_idx = edge_idx[..., :r, :] # Merged Tokens
dst_idx = node_idx[..., None].gather(dim=-2, index=src_idx)
if class_token:
# Sort to ensure the class token is at the start
unm_idx = unm_idx.sort(dim=1)[0]
def merge(x: torch.Tensor, mode="mean") -> torch.Tensor:
src, dst = x[..., ::2, :], x[..., 1::2, :]
n, t1, c = src.shape
unm = src.gather(dim=-2, index=unm_idx.expand(n, t1 - r, c))
src = src.gather(dim=-2, index=src_idx.expand(n, r, c))
dst = dst.scatter_reduce(-2, dst_idx.expand(n, r, c), src, reduce=mode)
if distill_token:
return torch.cat([unm[:, :1], dst[:, :1], unm[:, 1:], dst[:, 1:]], dim=1)
else:
return torch.cat([unm, dst], dim=1)
def unmerge(x: torch.Tensor) -> torch.Tensor:
unm_len = unm_idx.shape[1]
unm, dst = x[..., :unm_len, :], x[..., unm_len:, :]
n, _, c = unm.shape
src = dst.gather(dim=-2, index=dst_idx.expand(n, r, c))
out = torch.zeros(n, metric.shape[1], c, device=x.device, dtype=x.dtype)
out[..., 1::2, :] = dst
out.scatter_(dim=-2, index=(2 * unm_idx).expand(n, unm_len, c), src=unm)
out.scatter_(dim=-2, index=(2 * src_idx).expand(n, r, c), src=src)
return out
return merge, unmerge其中, 关键变量的含义, 维度和相关的注释如下:
src: 集合 A, shape: (B,N,c)
dst: 集合 B, shape: (B,N,c), 其中第1个 token 是 [distillation] token
unm: 集合 A 中不 merge 的 tokens, shape: (B,N−r,c) ,其中第1个 token 是 [class] token
src:集合 A 中要 merge 的 tokens, shape: (B,r,c)
借助 dst.scatter_reduce() 函数在集合 B 中完成 token merging 操作。
借助 torch.cat() 函数完成 merge 之后的集合 B 与不 merge 的集合 A 中的 tokens 的拼接工作。
51.1.5 Token Merging 的后续操作:调节注意力权重
前文提到, ToMe 模块会融合 个 token。在 ViT 模型里面, 一个 token 代表输入图片的一个 Patch, 比如输入图片有 个 Patch, 就是有 个 token。Attention 矩阵的维度也是 的, 它代表了 个 Patch 之间的相关关系。但是现在我们融合了 个 token 之后呢, Attention 矩阵的维度应该是 的, 融合了 token 之后, 有的 Key 应该占的 Attention 比重大一些, 因为它融合了多个 token 的信息。
所以作者在这里定义了一个行向量 。 是包含每个 token 大小 (token 所代表的 Patch 数量) 的行向量。
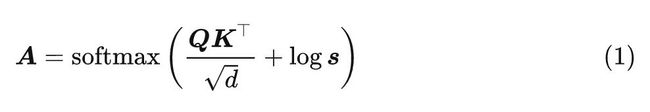
通过上式将行向量 直接加在 Attention 矩阵上面,相当于是人为增加了有些 Key 的 attention weight,而这些 key 恰好是发生了融合的 Key。
到目前为止,已经能够直接向已经训练好的 ViT 模型中添加 ToMe 模块。使用 ToMe 模块进行训练虽然不是必须的,但是它可以减少准确度下降,并且加快训练速度。ToMe 模块本质上是 token 的均值操作,因此可以视为是一种池化操作 (Pooling)。因此,我们可以按照平均池化操作 (Average Pooling) 的方式进行反向传播。
51.1.6 其他消融实验结果
定义式1所示的对不同 tokens 进行加权的方式为 weighted avg,在决定合并哪些 tokens 之后,通过对 tokens 进行平均加权来合并它们。下图5左侧的消融实验结果表明,weighted avg 的方式优于直接的 average pooling 的方式以及 max pooling 的方式。
下图5右侧的 sequential 代表在将 tokens 分为集合 和集合 时采用顺序的方式,alternating 代表交替分的方式,结果更好。
 图5:划分集合的方式
图5:划分集合的方式
如下图6所示为不同 token 缩减算法的实验结果对比,这些 token 缩减算法包括剪枝,合并等等。Pruning 速度很快,但是随着 98% 的 token 被移除,重要的信息丢失了。相比之下,合并 token 的算法只有在合并不相似的 token 时才会丢失信息。因此,正确地选择要合并的相似 token 非常重要。
k-means 确实是一种显而易见的 token 合并算法,但是除了速度慢的缺点之外,它只比 Pruning 算法好一点。因为 k-means 算法允许大量的 tokens 被匹配在一起,因此增加了不相似的 tokens 被合并在一起的概率。
相反,本文提出的 merging 算法只会合并最相似的 tokens,通过重复 次逐渐减小 token 的数量,具有更好的性能和 Pruning 方法的速度优势。
 图6:不同 token 缩减算法的实验结果对比
图6:不同 token 缩减算法的实验结果对比
作者接下来对比了15000种 merging 的策略,结果如下图7所示。模型是训练好的 AugReg ViT-B/16 模型,以 fp16 在 ImageNet-1K 上的精度。折现是每层融合 个 tokens 的 Constant Merging Schedule。作者发现,这种均匀融合的策略已经接近最优了。
 图7:不同融合策略的影响
图7:不同融合策略的影响
51.1.7 图像实验结果
对于图像实验,作者使用 ImageNet-1K 数据集,使用了4种不同的方式来训练,分别是:AugReg[7],MAE[8],SWAG[9],DeiT[10]。
有监督和弱监督模型实验结果
作者在11个 SOTA 的预训练 ViT 模型 (直接下载开源模型,不进行任何额外的训练) 上使用了本文提出的 ToMe 方法。AugReg 实验结果如下图8所示,为在大规模数据集预训练的模型,再在 ImageNet-1K 上 fine-tune 得到的结果。SWAG 实验结果如下图9所示,为在大规模数据集弱监督预训练的模型,再在 ImageNet-1K 上 fine-tune 得到的结果。结果表明,无论模型的尺寸和类型,ToMe 都能够带来约2倍的吞吐量加速。即使减少 96-98% 的 tokens,最大的模型几乎没有任何精度下降:在2倍吞吐量的设置下,AugReg 得到的 ViT-B,ViT-S 和 ViT-Ti 都有大约 4-5% 的精度下降。ViT-L 在 224px 图像上仅下降 2%,在 384px 图像上下降 0.7%,可能是因为更大的输入图片有更多的 tokens。而且,因为大型模型更深,因此允许其中间特征发生更渐进的变化,这也减少了 merging 带来的影响。
 图8:AugReg 实验结果
图8:AugReg 实验结果  图9:SWAG 实验结果
图9:SWAG 实验结果
自监督模型实验结果
MAE 实验结果如下图10所示,为在大规模数据集弱监督预训练的模型,再在 ImageNet-1K 上 fine-tune 得到的结果。结果显示,在2倍吞吐量的设置下,MAE 得到的 ViT-H,ViT-L 和 ViT-TB 分别有 0.4%,0.6% 和 1.7% 的精度下降。
 图10:MAE 实验结果
图10:MAE 实验结果
与其他模型对比
如下图11所示是 ToMe 方法 + MAE 微调的模型 (具体是在 MAE 进行微调的环节用上了本文的 ToMe 方法) 与其他 ImageNet-1K 模型的性能对比,可以看到 ToMe 方法可以提高 ViT 模型的吞吐量,使得较深的 ViT 模型 (如 ViT-H 和 ViT-L) 的吞吐量与较浅的模型相当。
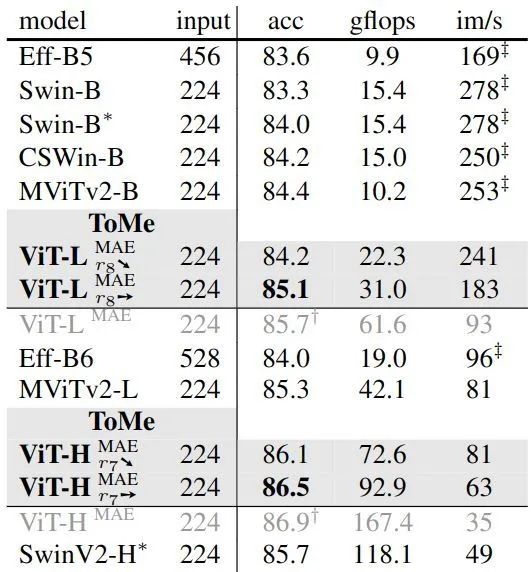 图11:与其他模型对比结果
图11:与其他模型对比结果
与 Token Pruning 方法对比
如下图12所示是 ToMe 方法与 Token Pruning 方法 (DynamicViT[1],A-ViT[3],SPViT[4]) 在 DeiT-S 模型上的对比结果。ToMe 方法可以再不使用梯度技巧,如 gumbel softmax 等,不添加额外的参数,以及不使用额外的训练技巧的情况下匹配性能,并超过现有的 Token Pruning 方法。
而且,Token Pruning 方法通过由于自身的限制往往使用 token padding 或者 attention 掩码的方法,使得剪枝带来的好处没法发挥出来。但是,ToMe 方法不受这个问题的影响。
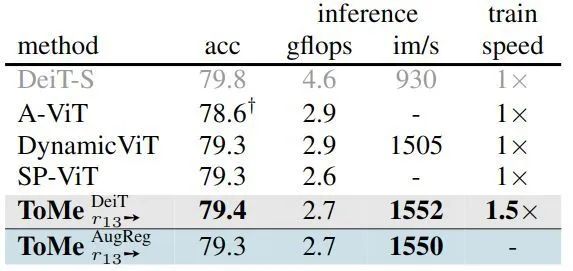 图12:与 Token Pruning 方法对比结果
图12:与 Token Pruning 方法对比结果
可视化实验结果
如下图13所示是在网络的结尾处的每个合并的 token 所对应的输入 Patch。可以发现,ToMe 方法造成的 token 融合的效果和分割很像。比如,在第2张图中,哈士奇的腿、身体和脸被合并到了不同的 token 中。在第3张图中,猴子的手、身体、脸、眼睛和嘴都被合并到了不同的 token 中。在最后1张图中,所有实例 (狗) 中相同的部分会被合并在一起。值得注意的是,与剪枝不同,ToMe 这种 token 融合的方法能够合并背景和前景中的大量冗余的 tokens,而且不丢失信息。
 图13:可视化实验结果
图13:可视化实验结果
51.1.8 视频实验结果
对于视频实验,作者使用 Kinetics-400 数据集,使用了 Spatiotemporal MAE[11] 的方式来训练。仿照图像实验的两种做法进行验证,一种是直接把 ToMe 方法应用在现成的训练好的模型中,另一种是在 MAE 进行微调的环节用上 ToMe 方法。实验结果如下图14所示。将 ToMe 方法应用在 ViT-L 上之后,吞吐量与 Swin-B 接近,同时性能更好。而且,将 ToMe 方法应用在 ViT-L 上之后,使用 Spatiotemporal MAE[11] 的方式,性能明显优于 MAE 方式训练的 ViT-B 模型,说明 token 融合的方法比 model scaling 更好。
 图14:视频任务实验结果,蓝色是无需训练直接使用 ToMe 方法的结果,灰色是微调阶段使用 ToMe 方法的结果
图14:视频任务实验结果,蓝色是无需训练直接使用 ToMe 方法的结果,灰色是微调阶段使用 ToMe 方法的结果
总结
ToMe 是一个无需训练并且兼顾性能-速度权衡的 token 融合方法,意在缩减 ViT 模型中大量冗余的 tokens。Token Merging 的基本思路是在一个 ViT 模型中间插入一些 token merging 的模块,希望把这些模块植入 ViT 以后,训练和推理的速度都有提升。在图像和视频中多个模型的实验结果表明,这种 token 融合的方法能够合并背景和前景中的大量冗余的 tokens,提高 ViT 模型的吞吐量,而且不丢失信息。
参考
^abDynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
^Adavit: Adaptive vision transformers for efficient image recognition
^abA-ViT: Adaptive tokens for efficient vision transformer
^abSpvit: Enabling faster vision transformers via soft token pruning
^Token pooling in vision transformers
^Tokenlearner: Adaptive space-time tokenization for videos
^How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers
^Masked autoencoders are scalable vision learners
^Revisiting weakly supervised pre-training of visual perception models
^Training data-efficient image transformers & distillation through attention
^abMasked Autoencoders As Spatiotemporal Learners

往期精彩回顾
适合初学者入门人工智能的路线及资料下载(图文+视频)机器学习入门系列下载机器学习及深度学习笔记等资料打印《统计学习方法》的代码复现专辑机器学习交流qq群955171419,加入微信群请扫码