强化学习 | 基于Novelty-Pursuit的高效探索方法
深度强化学习实验室
官网:http://www.neurondance.com/
论坛:http://deeprl.neurondance.com/
Li, Ziniu, and Xiong-Hui Chen. “Efficient Exploration by Novelty-Pursuit.” International Conference on Distributed Artificial Intelligence, 2020, pp. 85–102.
01
—
强化学习--基于采样的学习机制
基于采样的学习机制,即在环境中交互试错,是强化学习和传统的监督学习的一大区别。监督学习中,我们的数据集与每一个数据的标签,都是事先收集好的。我们使用一个函数近似器来尽可能高概率地使得每一个数据点的标签都被函数近似器准确预测。
而在强化学习中,我们没有事先收集好的数据集,所有的数据(即 状态-动作 对)都是在环境中在线采样而获得的;同时,我们也无需得到每一个采样的数据的标签(即每一个状态的最优动作标签),强化学习算法通过采集到的数据的回报(reward)信息来做自我提升,从而找到每一个状态数据中的最优动作选择(即使得智能体累积的回报最高的动作)。
强化学习的采样过程类比于人类的试错过程,人类在尝试用某一个策略执行任务且失败后,会根据执行结果反思失败的原因,然后尝试一些新的未知结果的行为,通过观察尝试的结果,优化自己下次做该任务时的决策。通过不断的尝试-学习,我们最终就会趋向于精通该任务。图1是一个人类决策的例子。

图1 人类试错决策示意。一个简单的人类基于采样进行有优化示例:一开始我们学会的技能是控制智能体向右走,但是这样的策略会让智能体最终掉下悬崖 (当前策略);下次我们遇到这个场景的时候,高效的做法是在悬崖边尝试其他的选择,比如尝试跳跃,并观察跳跃后会发生什么 (选择新的尝试);当我们发现在悬崖边进行跳跃式前进的方法可以让我们不坠入悬崖,我们便会学会 以后在控制智能体前进的过程中,若遇到悬崖,便进行跳跃(基于采样的优化)。
可以发现,在这个过程中,对于某一个策略,进行不同的采样,对于策略提升的效果都是不一样的。一个直观的例子是,如果已经采样知道了执行某一个动作序列将会使得我们无法完成任务,那么,再大量重复地采样这个动作序列得到同样的轨迹样本数据,对于我们找到更优的策略没有太大意义。
上面所述的“尝试”,在强化学习中称为探索(exploration)过程,这个进行新“尝试”的策略也称为探索策略(exploration policy),或者行为策略(behavior policy)。
因此,在设计一个强化学习算法时,我们需要考虑的一个问题是:基于当前的策略,我们应该如何确定如何探索,使得新采的样本利用率更大,从而提高 强化学习的学习效率。这边是高效探索的强化学习所期望解决的问题。
02
—
高效探索的原则
为了提高强化学习的优化效率,我们需要设计一个探索策略的优化目标。根据不同的任务特点,可用的探索策略的优化目标是不同的 [1, 2, 3]。
本文的优化目标是让策略尽可能高效地遍历环境中所有未见过的状态。这样的优化目标的对于稀疏奖励的探索任务具有较好的适应性,因为这种目标函数不依赖于环境的奖励函数信息。同时,这样的优化目标也有助于获得更高上限的收敛性能,因为通过遍历,我们可以不错过任何可能产生更高回报的状态。这在一些不看重样本利用率,但是看重策略的收敛性能的场景更有意义,比如:有一个低采样成本的环境模拟器,我们希望利用这组模拟器得到一个真实世界最优的策略。
此类方法的一个经典工作是maximum state entropy exploration (MSEE) [3]。Hazan 在MSEE 这个方法中,给出基于该目标函数的一个有效的实现。在MSEE方法中,策略的优化目标被定义为 最大化状态空间的熵,并以此构造了可最大化状态-动作熵的内部奖励函数,用奖励函数来指导策略的学习。其学习效果见图 2。

图2 横轴代表环境的状态,我们用状态的索引来表达不同的状态。纵轴代表的是每一个状态的被采样概率密度。
03
—
基于Novelty-Pursuit的高效探索机制
MSEE 的一大局限性是:需要事先知道状态空间的所有状态,若存在事先未知的状态,那么算法无法对未知区间的数据进行有效的探索。
本文的Novelty-Pursuit [5] 方法,也希望高效地遍历环境的状态空间,但不对状态空间的状态的存在性作出先验假设,这会使得算法更加实用。我们希望探索策略在这个过程中也能尽可能的遍历环境所有可能的状态。为了实现这个目标,我们将算法转化成两个步骤,图3是该方法的一种直观解释:
Max support: 尽可能多的采样未知的状态空间,扩展我们已知的状态空间中的状态;
Max entropy: 再在给定的状态空间的状态集合中进行采样,使得每一个数据尽可能被均衡地采样。
 图3 横轴代表环境的状态,我们用状态的索引来表达不同的状态。纵轴代表的是每一个状态的被采样概率密度。
图3 横轴代表环境的状态,我们用状态的索引来表达不同的状态。纵轴代表的是每一个状态的被采样概率密度。
经过对该范式的理论推导,我们发现,可以使用一个探索区域边界(Exploration boundary)和目标导向的策略(Goal-conditional policy)来实现上面的优化目标。具体而言,算法包括两个步骤:
使用一个访问状态的频率的近似器来确定我们各个访问状态的访问频次。这个部分我们使用随机网络蒸馏(Random Network Distillation [4])来实现;
根据访问状态的频率,我们得到已访问状态中访问频率较低的状态集合,并将这些状态集合成为 探索边界集合(Exploration boundary);
在做强化学习训练的过程中,我们额外训练一个目标导向策略(Goal-conditional policy),这个策略的优化目标是用最快的速度达到每一个目标状态;
在探索时,探索策略分为两个部分:首先,以探索边界为目标,让目标导向策略指引智能体走向访问边界;之后,使用随机策略在访问边界上进行探索。
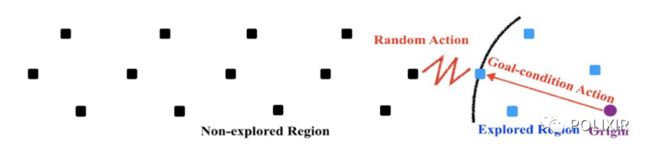
图4 Novelty-Pursuit 的探索过程示例
图4直观展示了 Novelty-Pursuit 的探索过程。在这个过程中,我们使用目标导向的策略让智能体直接走到已访问状态的边界,通过执行随机策略的方式来扩增访问状态空间的支撑集(max support)。目标导向的策略也可以避免传统的方法(比如 epsilon greedy)的方法,在已经频繁访问的区域进行高频的无效探索。当所有未知状态都被访问完毕之后,上述的机制为引导策略走向访问最少的状态,使得让策略做到尽可能均衡的在状态空间采样,从而做到最大化状态熵(max entropy)。
04
—
在迷宫、机械臂和超级玛丽环境中高效探索
我们在迷宫,机械臂和超级玛丽环境中验证了Novelty-Pursuit 方法对探索的高效性。
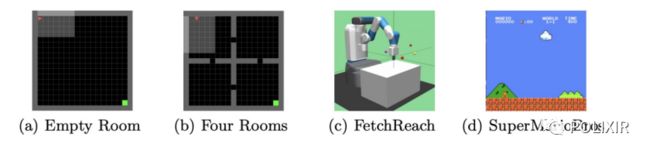 图5 实验环境示意图
图5 实验环境示意图
我们首先在empty room 上验证我们的方法是否能够做到在全状态空间中最大化状态熵,下表是我们的实验结果

从结果中可以看出,我们的方法比起 random 和bonus 的方法能更好的最大化状态熵。由于认为训练的goal-conditional policy和访问状态评估近似器(RND)存在误差,所以我们也测试了如果这两者的近似器不存在误差的时候,novelty-pursuit的结果如何。具体而言,表1的 novelty-pursuit-planning-oracle 使用的是最优的目标导向策略,而不是训练的策略;novelty-pursuit-counts-oracle使用的是精确的访问频次统计量,而不进行近似。novelty-pursuit-oracles指的是两者都用的精确值。可以看到,随着近似误差的消除,novelty-pursuit可以更为精确的做到最大化状态熵,即越接近最大值5.666。
接下来,我们在 empty room,four room 和 FetchReach三个环境中验证了我们的方法和其他SOTA探索方法的性能差距
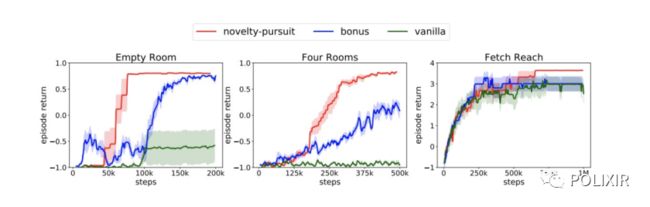
图6 empty room,four room 和 FetchReach三个环境中的训练曲线
同时,我们也在超级玛丽的1-1,1-2,1-3三个关卡中对比了我们的算法和其他SOTA探索方法的性能差距

图7 超级玛丽的1-1,1-2,1-3三个关卡的训练曲线
结果表明,novelty-pursuit 在以上的所有环境中是一致性好于 其他的baseline 算法的,这说明了novelty-pursuit的强大的探索能力。
最后,我们在马里奥1-1关卡中对 算法的探索轨迹进行可视化,从轨迹的可视化结果(绿色点)中可以看出,我们的方法能够更快的覆盖整个探索空间。

图8 马里奥 1-1 可视化
05
—
总结和展望
本文介绍了novelty-pursuit 的探索方法,作为一种最大化状态空间的状态熵的算法的高效实现。我们的实验结果展示了基于novelty-pursuit 探索的RL算法的强大的收敛性能。可以从empty room的实验中看到,目前的性能瓶颈主要在于边界评估近似器的误差和 目标导向的策略的能力上,未来我们会在边界的评估近似器和目标导向策略的训练上做进一步的强化,使得novelty-pursuit 的算法更为强大。我们也期望在更多的场景中验证novelty-pursuit 的收敛性能。
参考文献
[1] Chen, Xiong-Hui, and Yang Yu. "Reinforcement learning with derivative-free exploration." Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems. 2019.
[2] Houthooft, Rein, et al. "Curiosity-driven exploration in deep reinforcement learning via bayesian neural networks." (2016).
[3] Hazan, Elad, et al. "Provably efficient maximum entropy exploration." International Conference on Machine Learning. PMLR, 2019.
[4] Burda, Yuri, et al. "Exploration by random network distillation." arXiv preprint arXiv:1810.12894 (2018).
[5] Li, Ziniu, and Xiong-Hui Chen. "Efficient Exploration by Novelty-Pursuit." International Conference on Distributed Artificial Intelligence. Springer, Cham, 2020.
完
总结1:周志华 || AI领域如何做研究-写高水平论文
总结2:全网首发最全深度强化学习资料(永更)
总结3: 《强化学习导论》代码/习题答案大全
总结4:30+个必知的《人工智能》会议清单
总结5:2019年-57篇深度强化学习文章汇总
总结6: 万字总结 || 强化学习之路
总结7:万字总结 || 多智能体强化学习(MARL)大总结
总结8:深度强化学习理论、模型及编码调参技巧
完
第111篇:Reward is enough奖励机制实现各种目标。
第110篇:163篇ICML2021强化学习领域论文汇总
第109篇:【Easy-RL】200页强化学习总结笔记
第108篇:清华大学李升波老师《强化学习与控制》
第107篇:阿里巴巴2022届强化学习实习生招聘
第106篇:奖励机制不合理:内卷,如何解决?
第105篇:FinRL: 一个量化金融自动交易RL库
第104篇:RPG: 通过奖励发现多智能体多样性策略
第103篇:解决MAPPO(Multi-Agent PPO)技巧
第102篇:82篇AAAI2021强化学习论文接收列表
第101篇:OpenAI科学家提出全新强化学习算法
第100篇:Alchemy: 元强化学习(meta-RL)基准环境
第99篇:NeoRL:接近真实世界的离线强化学习基准
第98篇:全面总结(值函数与优势函数)的估计方法
第97篇:MuZero算法过程详细解读
第96篇: 值分布强化学习(Distributional RL)总结
第95篇:如何提高"强化学习算法模型"的泛化能力?
第94篇:多智能体强化学习《星际争霸II》研究
第93篇:MuZero在Atari基准上取得了新SOTA效果
第92篇:谷歌AI掌门人Jeff Dean获冯诺依曼奖
第91篇:详解用TD3算法通关BipedalWalker环境
第90篇:Top-K Off-Policy RL论文复现
第89篇:腾讯开源分布式多智能TLeague框架
第88篇:分层强化学习(HRL)全面总结
第87篇:165篇CoRL2020 accept论文汇总
第86篇:287篇ICLR2021深度强化学习论文汇总
第85篇:279页总结"基于模型的强化学习方法"
第84篇:阿里强化学习领域研究助理/实习生招聘
第83篇:180篇NIPS2020顶会强化学习论文
第82篇:强化学习需要批归一化(Batch Norm)吗?
第81篇:《综述》多智能体强化学习算法理论研究
第80篇:强化学习《奖励函数设计》详细解读
第79篇: 诺亚方舟开源高性能强化学习库“刑天”
第78篇:强化学习如何tradeoff"探索"和"利用"?
第77篇:深度强化学习工程师/研究员面试指南
第76篇:DAI2020 自动驾驶挑战赛(强化学习)
第75篇:Distributional Soft Actor-Critic算法
第74篇:【中文公益公开课】RLChina2020
第73篇:Tensorflow2.0实现29种深度强化学习算法
第72篇:【万字长文】解决强化学习"稀疏奖励"
第71篇:【公开课】高级强化学习专题
第70篇:DeepMind发布"离线强化学习基准“
第69篇:深度强化学习【Seaborn】绘图方法
第68篇:【DeepMind】多智能体学习231页PPT
第67篇:126篇ICML2020会议"强化学习"论文汇总
第66篇:分布式强化学习框架Acme,并行性加强
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第63篇:华为诺亚方舟招聘 || 强化学习研究实习生
第62篇:ICLR2020- 106篇深度强化学习顶会论文
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第60篇:滴滴主办强化学习挑战赛:KDD Cup-2020
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第56篇:RL教父Sutton实现强人工智能算法的难易
第55篇:内推 || 阿里2020年强化学习实习生招聘
第54篇:顶会 || 65篇"IJCAI"深度强化学习论文
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第46篇:DQN系列(2): Double DQN 算法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第43篇:起死回生|| 如何rebuttal顶会学术论文?
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第38篇:AAAI-2020 || 52篇深度强化学习论文
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第33篇:DeepMind-102页深度强化学习PPT
第32篇:腾讯AI Lab强化学习招聘(正式/实习)
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第18篇:"DeepRacer" —顶级深度强化学习挑战赛
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第15篇:DeepMind开源三大新框架!
第14篇:61篇NIPS2019DeepRL论文及部分解读
第13篇:OpenSpiel(28种DRL环境+24种DRL算法)
第12篇:模块化和快速原型设计Huskarl DRL框架
第11篇:DRL在Unity自行车环境中配置与实践
第10篇:解读72篇DeepMind深度强化学习论文
第9篇:《AutoML》:一份自动化调参的指导
第8篇:ReinforceJS库(动态展示DP、TD、DQN)
第7篇:10年NIPS顶会DRL论文(100多篇)汇总
第6篇:ICML2019-深度强化学习文章汇总
第5篇:深度强化学习在阿里巴巴的技术演进
第4篇:深度强化学习十大原则
第3篇:“超参数”自动化设置方法---DeepHyper
第2篇:深度强化学习的加速方法
第1篇:深入浅出解读"多巴胺(Dopamine)论文"、环境配置和实例分析
