模型推理部署
TVM针对不同的深度学习框架和硬件平台,实现了统一的软件栈,以尽可能高效的方式,将不同框架下的深度学习模型部署到硬件平台上。与LLVM的架构相似,在2017年由陈天奇团队推出,和 NNVM 一起组成深度学习到各种硬件的完整优化工具链,支持手机,cuda, opencl, metal, javascript 以及其它各种后端。
如果从编译器的视角来看待如何解决这个问题,各种框架写的网络可以根据特定的规则转化成某种统一的表示形式,在统一表示的基础上进行一些可重用的图优化,之后再用不同的后端来生成对应不同设备的代码,这就是目前各家都在尝试的设计思路了。
- TensorFlow 的 XLA 会把高级代码抽象成 XLA HLO 的表示,做目标无关优化之后再用对应后端来生成更深一层的代码。
- NVIDIA 的 TensorRT 的优化策略也是在图转化之后的统一表示上做,例如根据设定好的规则来做一些相邻计算单元的合并(Kernel Fusion)等等,但TensorRT最重要的Kernel部分的实现未开源。
一、TVM软件栈

二、工作流程
- 从已有的深度学习框架中获取一个模型并将此模型转换为计算图表示(深度学习框架的前端主要提供计算图表示以及自动梯度的功能);
- 图中 Section 3 使用一些方法优化当前的计算图得到优化后的计算图;
- 图中 Section 4 针对计算图中每个融合的算子生成有效的代码,生成过程中结合了张量表达式以及硬件优化原语,在算子级进行优化;
- 由于优化空间非常大,图中 Section 5 基于机器学习技术实现自动优化;
- 系统打包生成的代码到部署模块中。
三、模型转化
我们可能会在某一任务中将Pytorch或者TensorFlow模型转化为ONNX模型(ONNX模型一般用于中间部署阶段),然后再拿转化后的ONNX模型进而转化为我们使用不同框架部署需要的类型。
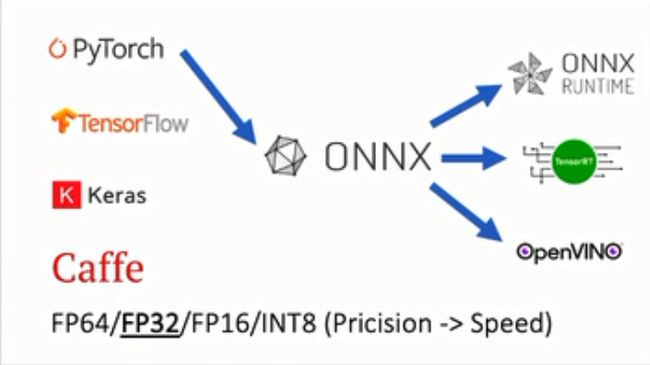
常见的转换形式有如下:
- Pytorch -> ONNX -> TensorRT
- Pytorch -> ONNX -> TVM
- Pytorch -> ONNX -> openvino
- pytorch->ONNX->ONNX RUNTIME
- TF – onnx – ncnn
- WebAssembly
对于精度和速度而言,两者是相悖的,一般而言间隔一个精度层次,速度相差2倍左右,对于检测样本比较精细或者模糊的,推荐使用高精度模型进行训练。ONNX采用的是protobuf这个序列化数据结构协议去存储神经网络权重信息,Protobuf是一种平台无关、语言无关、可扩展且轻便高效的序列化数据结构的协议,可以用于网络通信和数据存储。我们可以通过protobuf自己设计一种数据结构的协议,然后使用各种语言去读取或者写入,通常我们采用的语言就是C++。至于量化之间的区别,可以参考这篇博客https://www.maixj.net/ict/float16-32-64-19912。需要注意的是,由于onnx是一个发展中的网络模型转化器,对于神经网络有些操作并不是很好支持,这个需要注意。
针对不同的框架,服务器端一般借助docker来实现,常见的配置有以下几种,
- TensorFlow Serving
TensorFlow Serving是google提供的一种生产环境部署方案,一般来说在做算法训练后,都会导出一个模型,在应用中直接使用。Google提供了一种生产环境的新思路,他们开发了一个tensorflow-serving的服务,可以自动加载某个路径下的所有模型,模型通过事先定义的输入输出和计算图,直接提供rpc或者rest的服务。
一方面,支持多版本的热部署(比如当前生产环境部署的是1版本的模型,训练完成后生成一个2版本的模型,tensorflow会自动加载这个模型,停掉之前的模型)。
另一方面,tensorflow serving内部通过异步调用的方式,实现高可用,并且自动组织输入以批次调用的方式节省GPU计算资源。
- pytorch
环境配置:首先确保安装了pytorch,因为需要使用flask这个web框架,所以当然需要安装flask,flask框架
配置REST API:我们知道每次启动模型,load参数是一件非常费时间的事情,而每次做前向传播的时候模型其实都是一样的,所以我们最好的办法就是load一次模型,然后做完前向传播之后仍然保留这个load好的模型,下一次有新的数据进来,我们就可以不用重新load模型,可以直接做前向传播得到结果,这样无疑节约了很多load模型的时间。所以我们需要建立一个类似于服务器的机制,将模型在服务器上load好,方便我们不断去调用模型做前向传播,那么怎么能够达到这个目的呢?我们可以使用flask来建立一个REST API来达到这一目的。REST API 是什么呢?REST 是Representational State Transfer的缩写,这是一种架构风格
- Nginx web 服务器
Nginx:Nginx 是一个开源网络服务器,但也可以用作负载均衡器,其以高性能和很小的内存占用而著称。它可以大量生成工作进程,每个进程能处理数千个网络连接,因而在极重的网络负载下也能高效工作。在上图中,Nginx 是某个服务器或实例的本地均衡器,用于处理来自公共负载均衡器的所有请求。我们也可以用 Apache HTTP Server 代替 Nginx。
- 移动端部署
首先针对模型选型,优先考虑mobilenet,ghostnet等轻量网络结构,其次考虑模型剪枝等策略,针对ios端,苹果官方给出了Core ML框架,它的出现使部署移动端的任务量可以缩减到最少两行代码。至于使用可以查看iOS(swift): Core ML的使用_亚古兽要进化的博客-CSDN博客与跑在浏览器里的ncnn和webassembly - 知乎
在国内当前主流的移动端推理框架有ncnn、MACE、MNN、TNN。
ncnn 是腾讯优图实验室首个开源项目,是一个为手机端极致优化的高性能神经网络前向计算框架。ncnn 从设计之初深刻考虑手机端的部属和使用。无第三方依赖,跨平台,手机端 cpu 的速度快于目前所有已知的开源框架。
MACE是小米公司推出的一个专为移动端异构计算平台的神经网络计算框架,主要从性能、功耗、系统响应内存占用、模型加密与保护、硬件支持范围进行了专门的优化。
MNN是一个高效、轻量的深度学习框架。它支持深度模型推理与训练,尤其在端侧的推理与训练性能在业界处于领先地位。目前,MNN已经在阿里巴巴的手机淘宝、手机天猫、优酷、钉钉、闲鱼等20多个App中使用,覆盖直播、短视频、搜索推荐、商品图像搜索、互动营销、权益发放、安全风控等70多个场景。此外,IoT等场景下也有若干应用。
TNN:由腾讯优图实验室打造,移动端高性能、轻量级推理框架,同时拥有跨平台、高性能、模型压缩、代码裁剪等众多突出优势。TNN框架在原有Rapidnet、ncnn框架的基础上进一步加强了移动端设备的支持以及性能优化,同时也借鉴了业界主流开源框架高性能和良好拓展性的优点。
移动端推理框架ncnn、MACE、MNN、TNN,并不能直接兼容Tensorflow、Pytorch的模型,而需要先将Tensorflow、Pytorch转换成ONNX(Open Neural Network Exchange),再将ONNX转换到ncnn、MACE、MNN、TNN所支持的模型。ONNX是一个用于表示深度学习模型的标准,可使模型在不同框架之间进行转移。
- 网页端部署
WebAssembly/wasm WebAssembly 或者 wasm 是一个可移植、体积小、加载快并且兼容 Web 的全新格式。面向下一代Web的深度学习编译:WebAssembly和WebGPU初探 - 知乎
四、训练
为了考虑模型检测结果和时效性,训练精度需要综合考虑。常见的有混合精度训练等,混合精度是指在训练期间在模型中同时使用16位和32位浮点类型,以使其运行更快并使用更少的内存。通过将模型的某些部分保持在32位类型中以保持数值稳定性,模型将具有更短的步长时间,并且在评估指标(如准确性)方面同样可以训练。可以在现代GPU和TPU上将性能提高。
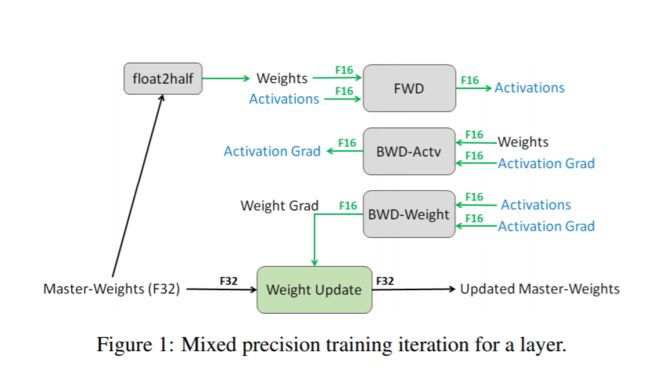
详情可见:Nvidia GPU的浮点计算能力(FP64/FP32/FP16)_haima1998的博客-CSDN博客_fp32算力,tensorflow fp16训练 - sunny,lee - 博客园与tensorflow 混合精度训练_冰菓(笑)的博客-CSDN博客_tensorflow 混合精度训练
五、示例代码
###模型转换
import onnx
import numpy as np
import tvm
import tvm.relay as relay
onnx_model = onnx.load('test.onnx')
target = tvm.target.create('llvm')
input_name = '0' # change '1' to '0'
shape_dict = {input_name: (1, 3, 224, 224)}
sym, params = relay.frontend.from_onnx(onnx_model, shape_dict)
with relay.build_config(opt_level=2):
graph, lib, params = relay.build_module.build(sym, target, params=params)
dtype = 'float32'
from tvm.contrib import graph_runtime
print("Output model files")
libpath = "./test.so"
lib.export_library(libpath)
graph_json_path = "./test.json"
with open(graph_json_path, 'w') as fo:
fo.write(graph)
param_path = "./test.params"
with open(param_path, 'wb') as fo:
fo.write(relay.save_param_dict(params))
###模型部署
import numpy as np
import tvm
import tvm.relay as relay
from tvm.contrib import graph_runtime
import cv2 as cv
test_json = 'test.json'
test_lib = 'test.so'
test_param = 'test.params'
loaded_json = open(test_json).read()
loaded_lib = tvm.module.load(test_lib)
loaded_params = bytearray(open(test_param, "rb").read())
def preprocess(img_src):
img_src= cv.cvtColor(img_src, cv.COLOR_BGR2RGB)
img_src= cv.resize(img_src, (224, 224))
input_data = np.array(img_src).astype(np.float32)
input_data = input_data / 255.0
input_data = np.transpose(input_data, (2, 0, 1))
input_data[0] = (input_data[0] - 0.485)/ 0.229
input_data[1] = (input_data[1] - 0.456)/ 0.224
input_data[2] = (input_data[2] - 0.406)/ 0.225
input_data = input_data[np.newaxis, :].copy()
return input_data
img = cv.imread("29.jpg")
img_input = preprocess(img)
ctx = tvm.cpu(0)
module = graph_runtime.create(loaded_json, loaded_lib, ctx)
module.load_params(loaded_params)
# run the module
module.set_input("0", img_input)
module.run()
out_deploy = module.get_output(0).asnumpy()
print(classes[np.argmax(out_deploy)])参考链接:
TVM简介_Dark-Rich的博客-CSDN博客_tvm介绍 (TVM简介)
如何利用 TVM 优化深度学习GPU op?教你用几十行Python代码实现2-3倍提升 | 雷峰网(如何利用 TVM 优化深度学习GPU op?教你用几十行Python代码实现2-3倍提升)
tvm学习笔记 (三):载入onnx格式模型-python黑洞网(tvm学习笔记 (三):载入onnx格式模型)
https://blog.csdn.net/manong_wxd/article/details/78720236?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase(PyTorch学习总结(三)——ONNX)
https://blog.csdn.net/luolinll1212/article/details/107091820?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5.nonecase(【环境搭建】onnxruntime)
https://blog.csdn.net/heiheiya/article/details/100320682?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-2.nonecase(【ncnn】Ubuntu16.04+OpenCV3.4.0 ncnn环境搭建)