利用谷歌的联邦学习框架Tensorflow Federated实现FedAvg(详细介绍)
目录
- I. 前言
- II. 数据介绍
- III. 联邦学习
-
- 1. 整体框架
- 2. 服务器端
- 3. 客户端
- IV. Tensorflow Federated
-
- 1. 数据处理
- 2. 构造TFF的Keras模型
- 3. 训练
- 4. 测试
- 5. 实验结果及分析
- V. 一些思考
- VI. 源码及数据
I. 前言
关于联邦学习,前面已经有几篇文章做了一些阐述:
- 联邦学习原始论文解读
- IEEE ICIP 2019 | 更快更好的联邦学习:一种特征融合方法
- 联邦学习基本算法FedAvg的代码实现
- KBS 2021 | 联邦学习综述
- WorldS4 2020 | 联邦学习的个性化技术综述
谷歌作为联邦学习的提出者,在其深度学习框架TensorFlow的基础上开发出了一套联邦学习的框架Tensorflow Federated(后文简称TFF)。TFF是一个开源框架,用于机器学习和其他分散数据计算,其开发旨在促进联邦学习的研究与试验。
TFF的接口分为两层:
- Federated Learning (FL) API:该层提供了一组高级接口,允许开发人员将包含的联邦训练和评估实现应用到他们现有的TensorFlow模型中。
- Federated Core (FC) API:该系统的核心是一组较低级别的接口,用于通过在强类型函数式编程环境中将TensorFlow与分布式通信运算符相结合来简洁地表达联邦算法。这一层也是我们构建联邦学习的基础。
之前我一直用的是PyTorch,之前的一篇博客联邦学习基本算法FedAvg的代码实现也是基于numpy来实现的,因此很少接触TensorFlow。
不过没办法,自己造轮子的效果不是很好,PyTorch也没有对联邦学习进行封装,那就只有学习TensorFlow以及Tensorflow Federated了。
有关TensorFlow和Tensorflow Federated的安装可以参考我的另一篇博客:安装tensorflow-gpu和tensorflow_federated。
II. 数据介绍
联邦学习中存在多个客户端,每个客户端都有自己的数据集,这个数据集他们是不愿意共享的。
本文选用的数据集为中国北方某城市10个区/县从2016年到2019年三年的真实用电负荷数据,采集时间间隔为1小时,即每一天都有24个负荷值。
我们假设这10个地区的电力部门不愿意共享自己的数据,但是他们又想得到一个由所有数据统一训练得到的全局模型。
这里我们用某一时刻前24个时刻的负荷值以及该时刻的相关气象数据(如温度、湿度、压强等)来预测该时刻的负荷值。各个地区应该就如何制定特征集达成一致意见,本文使用的各个地区上的数据的特征是一致的,可以直接使用。
不过有一点需要注意:客户端参与联邦学习的主要动机是获得更好的模型。客户端如果没有足够的私人数据来开发准确的本地模型,就可以从联邦学习的模型中获益。然而,对于有足够私人数据来训练准确的本地模型的客户来说,参与联邦学习是否有好处是有争议的。这里每个客户端都拥有了足够多的本地数据,因此仅仅利用本地数据训练出的模型应该比全局模型表现出更好的性能,实验结果也证实了这一点。
III. 联邦学习
1. 整体框架
原始论文中提出的FedAvg的框架为:

本文中需要利用各个客户端的模型参数来对服务器端的模型参数进行更新,这里采用TensorFlow的keras模块来搭建了一个简单的神经网络:
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(20, tf.nn.sigmoid, input_shape=(30,),
kernel_initializer='zeros'),
tf.keras.layers.Dense(20, tf.nn.sigmoid),
tf.keras.layers.Dense(20, tf.nn.sigmoid),
tf.keras.layers.Dense(1, tf.sigmoid)
])
2. 服务器端
服务器端执行以下步骤:
- 初始化参数
- 对第t轮训练来说:首先计算出 m = m a x ( C ⋅ K , 1 ) m=max(C \cdot K, 1) m=max(C⋅K,1),然后随机选择m个客户端,对这m个客户端做如下操作(所有客户端并行执行):更新本地的 w t k w_t^{k} wtk得到 w t + 1 k w_{t+1}^{k} wt+1k。所有客户端更新结束后,将 w t + 1 k w_{t+1}^{k} wt+1k传到服务器,服务器整合所有 w t + 1 k w_{t+1}^{k} wt+1k得到最新的全局参数 w t + 1 w_{t+1} wt+1。
- 服务器将最新的 w t + 1 w_{t+1} wt+1分发给所有客户端,然后进行下一轮的更新。
简单来说,每一轮通信时都只是选择部分客户端,这些客户端利用本地的数据进行参数更新,然后传给服务器,服务器汇总所有客户端的参数形成自己的参数,然后将汇总的参数再次分发给所有客户端,然后进行下一轮更新。
3. 客户端
客户端没什么可说的,就是利用本地数据对神经网络模型的参数进行更新。
IV. Tensorflow Federated
1. 数据处理
代码:
# Data processing
def client_data(n, B, train_flag):
print('处理数据:')
data = load_data(clients[n])
if train_flag:
data = data[0:int(len(data) * 0.9)]
else:
data = data[int(len(data) * 0.9):len(data)]
load = data[data.columns[1]].values.tolist()
# print(load)
data = data.values.tolist()
X, Y = [], []
for i in range(len(data) - 30):
train_seq = []
# train_label = []
for j in range(i, i + 24):
train_seq.append(load[j])
# 添加温度、湿度、气压等信息
for c in range(2, 8):
train_seq.append(data[i + 24][c])
Y.append(load[i + 24])
X.append(train_seq)
X = tf.reshape(X, [len(X), -1])
Y = tf.reshape(Y, [len(Y), -1])
X = tf.data.Dataset.from_tensor_slices(X)
Y = tf.data.Dataset.from_tensor_slices(Y)
seq = tf.data.Dataset.zip((X, Y))
seq = seq.batch(B, drop_remainder=True).shuffle(100).prefetch(B)
# print(list(seq.as_numpy_iterator())[0])
return seq
对于函数client_data(n, B, train_flag),如果train_flag=True,返回客户端n的batch_size=B的训练集,否则返回测试集。
任意输出其中一条数据:
print(list(seq.as_numpy_iterator())[0])
结果:
(array([[0.4195624 , 0.43211627, 0.48750123, 0.46142522, 0.50673616,
0.49603754, 0.46745548, 0.4261831 , 0.4905846 , 0.49231917,
0.47030267, 0.5219719 , 0.52490044, 0.4579194 , 0.43583727,
0.41776225, 0.34858742, 0.33259332, 0.40729982, 0.3909672 ,
0.393119 , 0.36626622, 0.37780192, 0.35956943, 0. ,
1. , 0.26086956, 0.6666667 , 0.41860464, 0.34146342],
[0.43211627, 0.48750123, 0.46142522, 0.50673616, 0.49603754,
0.46745548, 0.4261831 , 0.4905846 , 0.49231917, 0.47030267,
0.5219719 , 0.52490044, 0.4579194 , 0.43583727, 0.41776225,
0.34858742, 0.33259332, 0.40729982, 0.3909672 , 0.393119 ,
0.36626622, 0.37780192, 0.35956943, 0.42298427, 0. ,
1. , 0.3043478 , 0.6666667 , 0.41860464, 0.34146342],
[0.48750123, 0.46142522, 0.50673616, 0.49603754, 0.46745548,
0.4261831 , 0.4905846 , 0.49231917, 0.47030267, 0.5219719 ,
0.52490044, 0.4579194 , 0.43583727, 0.41776225, 0.34858742,
0.33259332, 0.40729982, 0.3909672 , 0.393119 , 0.36626622,
0.37780192, 0.35956943, 0.42298427, 0.39648312, 0. ,
1. , 0.3478261 , 0.6666667 , 0.41860464, 0.34146342],
[0.46142522, 0.50673616, 0.49603754, 0.46745548, 0.4261831 ,
0.4905846 , 0.49231917, 0.47030267, 0.5219719 , 0.52490044,
0.4579194 , 0.43583727, 0.41776225, 0.34858742, 0.33259332,
0.40729982, 0.3909672 , 0.393119 , 0.36626622, 0.37780192,
0.35956943, 0.42298427, 0.39648312, 0.4274243 , 0. ,
1. , 0.39130434, 0.6666667 , 0.41860464, 0.34146342],
[0.50673616, 0.49603754, 0.46745548, 0.4261831 , 0.4905846 ,
0.49231917, 0.47030267, 0.5219719 , 0.52490044, 0.4579194 ,
0.43583727, 0.41776225, 0.34858742, 0.33259332, 0.40729982,
0.3909672 , 0.393119 , 0.36626622, 0.37780192, 0.35956943,
0.42298427, 0.39648312, 0.4274243 , 0.44137946, 0. ,
1. , 0.4347826 , 0.6666667 , 0.41860464, 0.34146342]],
dtype=float32), array([[0.42298427],
[0.39648312],
[0.4274243 ],
[0.44137946],
[0.44090188]], dtype=float32))
这里batch_size=5。
2. 构造TFF的Keras模型
# Wrap a Keras model for use with TFF.
def model_fn():
model = tf.keras.models.Sequential([
tf.keras.layers.Dense(20, tf.nn.sigmoid, input_shape=(30,),
kernel_initializer='zeros'),
tf.keras.layers.Dense(20, tf.nn.sigmoid),
tf.keras.layers.Dense(20, tf.nn.sigmoid),
tf.keras.layers.Dense(1, tf.sigmoid)
])
return tff.learning.from_keras_model(
model,
input_spec=train_data[0].element_spec,
loss=tf.keras.losses.MeanSquaredError(),
metrics=[tf.keras.metrics.MeanAbsolutePercentageError()])
其中model是一个简单的Keras模型,model_fn()最终返回的是一个tff.learning.Model,该模型将用于联邦学习。来看一下官方API:
tff.learning.from_keras_model(
keras_model: tf.keras.Model,
loss: Loss,
input_spec,
loss_weights: Optional[List[float]] = None,
metrics: Optional[List[tf.keras.metrics.Metric]] = None
) -> tff.learning.Model
- keras_model:为联邦学习封装的Keras模型,该模型不能compile。
- loss:损失函数。如果只提供一个损失函数,则所有模型都使用该损失函数;如果提供一个损失函数列表,则与各个客户端模型相互对应。这里选择MSE。
- input_sec:指定模型的输入数据类型。input_spec必须是两个元素的复合结构,即x和y。如果作为列表提供,则必须按 [x, y]的顺序,如果作为字典提供,则键必须明确命名为“x”和“y”。本文是按照列表进行提供的。
- loss_weights:可选项。如果loss为一个列表,那么就可以为每一个客户端的loss指定一个权重,最后求加权和。
- metrics:可选项。这里选择了MAPE。
3. 训练
def train():
# Simulate a few rounds of training with the selected client devices.
trainer = tff.learning.build_federated_averaging_process(
model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.Adam(0.08),
# server_optimizer_fn=lambda: tf.keras.optimizers.SGD(1.0),
# use_experimental_simulation_loop=True
)
state = trainer.initialize()
for _ in range(20):
state, metrics = trainer.next(state, train_data)
print('loss:', metrics['train']['loss'])
首先需要定义一个tff.templates.IterativeProcess对象:
trainer = tff.learning.build_federated_averaging_process(
model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.Adam(0.08)
)
看一下官方API:
tff.learning.build_federated_averaging_process(
model_fn: Callable[[], tff.learning.Model],
client_optimizer_fn: Callable[[], tf.keras.optimizers.Optimizer],
server_optimizer_fn: Callable[[], tf.keras.optimizers.Optimizer] = DEFAULT_SERVER_OPTIMIZER_FN,
*,
client_weighting: Optional[tff.learning.ClientWeighting] = None,
broadcast_process: Optional[tff.templates.MeasuredProcess] = None,
aggregation_process: Optional[tff.templates.MeasuredProcess] = None,
model_update_aggregation_factory: Optional[tff.aggregators.WeightedAggregationFactory] = None,
use_experimental_simulation_loop: bool = False
) -> tff.templates.IterativeProcess
- model_fn:前面构造的tff.learning.Model对象。
- client_optimizer_fn:客户端的优化器。这里为Adam(lr=0.08)。
- server_optimizer_fn:服务器端优化器。默认为SGD(lr=1.0)。
- client_weighting:梯度聚合方式。默认根据客户端样本数量进行聚合。
- broadcast_process:一个tff.templates.MeasuredProcess对象,它将服务器上的模型权重广播到客户端,默认使用tff.federated_broadcast进行广播。
- aggregation_process:一个tff.templates.MeasuredProcess对象,它将客户端的模型权重聚合更新回服务器。
- model_update_aggregation_factory:用于在服务器上聚合客户端模型更新。
- use_experimental_simulation_loop:为True时进行高性能GPU模拟。
现在我们定义好了tff.templates.IterativeProcess对象,该对象包含初始化和迭代计算的过程。
state = trainer.initialize()
for r in range(20):
state, metrics = trainer.next(state, train_data)
print('round', r + 1, 'loss:', metrics['train']['loss'])
state = trainer.initialize()返回迭代过程对象的初始状态。然后训练20轮:
for r in range(20):
state, metrics = trainer.next(state, train_data)
print('round', r + 1, 'loss:', metrics['train']['loss'])
每次调用next方法时,使用广播函数将服务器模型广播到每个客户端。对于每个客户端,通过客户端优化器的tf.keras.optimizers.Optimizer.apply_gradients方法执行一个epoch的本地训练。然后每个客户端计算训练后的客户端模型与初始广播模型之间的差异,再使用一些聚合函数在服务器上聚合这些模型增量。最后通过使用服务器优化器的tf.keras.optimizers.Optimizer.apply_gradients方法在服务器上应用聚合模型增量。
训练过程:
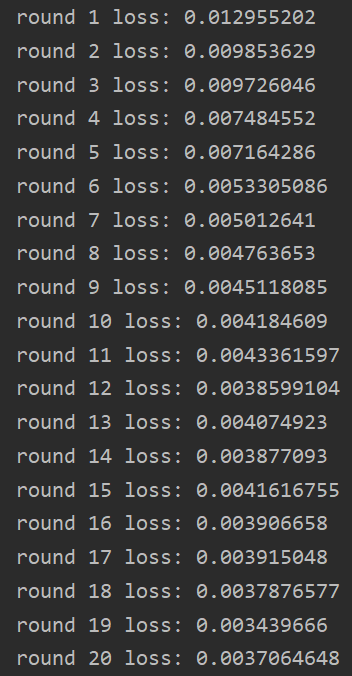
4. 测试
利用服务器端最终获得的全局模型在每个客户端的本地测试集上进行测试:
evaluation = tff.learning.build_federated_evaluation(model_fn)
for i in range(10):
test_data = [client_data(n, 20, train_flag=False) for n in range(i, i + 1)]
# print('test:')
test_metrics = evaluation(state.model, test_data)
print(str(test_metrics['mean_absolute_percentage_error'] / len(test_data[0])))
test_metrics = evaluation(state.model, test_data)用于对test_data进行测试,并返回loss和metrics。
5. 实验结果及分析
| 客户端编号 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | avg |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 本地模型MAPE / % | 5.26 | 4.81 | 6.09 | 4.47 | 3.81 | 3.71 | 6.92 | 4.71 | 2.99 | 5.58 | 4.74 |
| numpy MAPE / % | 15.11 | 19.00 | 17.84 | 15.34 | 24.71 | 11.08 | 17.46 | 21.55 | 8.52 | 9.93 | 16.65 |
| TFF MAPE / % | 9.05 | 7.05 | 6.16 | 5.52 | 4.87 | 7.98 | 6.03 | 5.47 | 7.82 | 6.64 | 6.66 |
本地模型MAPE是各个客户端仅利用本地数据进行模型训练后得到的预测表现。numpy MAPE是利用numpy手写联邦学习得到的预测表现(50轮通信),TFF MAPE是利用Tensorflow Federated进行联邦学习(20轮通信)后得到的预测表现。后两种实验方案中的客户端模型是一样的(前者是利用numpy手搭的,后者是利用Keras搭建的)。
可以发现:
- 由于各个客户端数据量十分充足,本地模型的效果无疑应该是最佳的。
- TFF仅通信20轮就能十分接近本地模型的效果,并且远好于numpy通信50轮的效果。
V. 一些思考
这不禁引发了一个疑问:既然自己手写的模型效果很差劲,那么在算法的学习过程中,真的有必要自己造轮子吗?
答案是肯定的。在学习过程中,只有真正理解模型内的原理,才能知道如何选取合适的模型以及如何修改模型参数。但如果是在工作场景下,能够直接调包就直接调包,这是从效率出发的。不过即使是标准模型,在很多业务场景下也并不能直接使用,这个时候就需要自己针对业务做出一些修改。
简单来说,你可以不重复造轮子,但你得会自己造轮子。
搞算法的人可以简单分成三个类别:
- 调包很熟练,但对算法的原理不是很了解,这是很多初学者的特征。
- 调包很熟练,算法原理了解一些,但是自己不能写出来。
- 能够根据算法原理自己手动写出模型。
努力成为第三种人!
VI. 源码及数据
后面将陆续公开~