Python简介和入门 基础介绍

1.Python前世今生
1.1.Python历史
Python的创始人: Guido van Rossum;之所以选中Python(大蟒蛇的意思)作为该编程语言的名字,是因为他是一个叫Monty Python的喜剧团体的爱好者。
诞生于1989年。作者前身也是C++程序员,之前也参加设计了一种叫ABC的教学语言,就Guido本人看来,ABC 这种语言非常优美和强大,是专门为非专业程序员设计的。但是ABC语言并没有成功,究其原因,Guido 认为是其非开放造成的(相对封闭的开发语言、扩展性、推广性相对不太成功。)。Guido 决心在Python 中避免这一错误。同时,他还想实现在ABC 中闪现过但未曾实现的东西。

图片来自网络
- 1991年,第一个Python编译器诞生。它是用C语言实现的,小编整理了一些Python学习资料,有需要的朋友可以点击免费领取并能够调用C语言的库文件。从一出生,Python已经具有了:类,函数,异常处理,包含表和词典在内的核心数据类型,以及模块为基础的拓展系统。
- Granddaddy of Python web frameworks, Zope 1 was released in 1999
- Python 1.0 - January 1994 增加了 lambda, map, filter and reduce.
- Python 2.0 - October 16, 2000,加入了内存回收机制,构成了现在Python语言框架的基础
- Python 2.4 - November 30, 2004, 同年目前最流行的WEB框架Django 诞生
- Python 2.5 - September 19, 2006
- Python 2.6 - October 1, 2008
- Python 3.0 - December 3, 2008
- Python 3.1 - June 27, 2009
- Python 2.7 - July 3, 2010
- In November 2014, it was announced that Python 2.7 would be supported until 2020, and reaffirmed that there would be no 2.8 release as users were expected to move to Python 3.4+ as soon as possible
- Python 3.2 - February 20, 2011
- Python 3.3 - September 29, 2012
- Python 3.4 - March 16, 2014
- Python 3.5 - September 13, 2015
1.2.热门排行
最新的TIOBE排行榜,Python赶超PHP占据第四。

图片来自网络
由上图可见,Python整体呈上升趋势,反映出Python应用越来越广泛并且也逐渐得到业内的认可!

图片来自网络
IEEE Spectrum (电气和电子工程师协会) 2017 编程语言 Top 10
http://spectrum.ieee.org/static/interactive-the-top-programming-languages-2017
- Python 的排名从去年开始就在持续上升,并跃至第一。但排在前四名的语言 Python、
- C、Java 和 C++ ,其实都保持着非常接近的流行度。

图片来自网络
图片来自网络
1.3.Python应用领域
- 云计算
云计算最火的语言, 典型应用OpenStack
- WEB开发
python相比php\ruby的模块化设计,非常便于功能扩展;多年来形成了大量优秀的web开发框架,并且在不断迭代;如目前优秀的全栈的django、框架flask,都继承了python简单、明确的风格,开发效率高、易维护,与自动化运维结合性好,python已经成为自动化运维平台领域的事实标准;众多大型网站均为Python开发,Youtube, Dropbox, 豆瓣。
- 人工智能
基于大数据分析和深度学习而发展出来的人工智能本质上已经无法离开python的支持,目前世界优秀的人工智能学习框架如Google的TransorFlow 、FaceBook的PyTorch以及开源社区的神经网络库Karas等是用python实现的,甚至微软的CNTK(认知工具包)也完全支持Python,而且微软的Vscode都已经把Python作为第一级语言进行支持。
- 系统运维
Python在与操作系统结合以及管理中非常密切,目前所有linux发行版中都带有python,且对于linux中相关的管理功能都有大量的模块可以使用,例如目前主流的自动化配置管理工具:SaltStack Ansible(目前是RedHat的)。目前在几乎所有互联网公司,自动化运维的标配就是python+Django/flask,另外,在虚拟化管理方面已经是事实标准的openstack就是python实现的,所以Python是所有运维人员的必备技能。
- 金融
量化交易,金融分析,在金融工程领域,Python不但在用,且用的最多,而且重要性逐年提高。原因:作为动态语言的Python,语言结构清晰简单,库丰富,成熟稳定,科学计算和统计分析都很牛逼,生产效率远远高于c,c++,java,尤其擅长策略回测
- 大数据
Python相对于其它解释性语言最大的特点是其庞大而活跃的科学计算生态,在数据分析、交互、可视化方面有相当完善和优秀的库(python数据分析栈:Numpy Pandas Scipy Matplotlip Ipython), 并且还形成了自己独特的面向科学计算的Python发行版Anaconda,而且这几年一直在快速进化和完善,对传统的数据分析语言如R MATLAB SAS Stata形成了非常强的替代性。
- 图形GUI
PyQT, WxPython,TkInter
1.4.Python行业应用
- CIA:美国中情局网站就是用Python开发的
- NASA:美国航天局(NASA)1994年起把python作为主要开发语言(使用Python进行数据分析和运算)
- Google:Google App Engine 、code.google.com 、Google earth 、谷歌爬虫、Google广告等项目都在大量使用Python开发
- Facebook:大量的基础库均通过Python实现的
- YouTube:世界上最大的视频网站YouTube就是用Python开发的
- Dropbox:美国最大的在线云存储网站,全部用Python实现,每天网站处理10亿个文件的上传和下载
- Instagram:美国最大的图片分享社交网站,每天超过3千万张照片被分享,全部用python开发
- Redhat:世界上最流行的Linux发行版本中的yum包管理工具就是用python开发的
- 豆瓣:公司几乎所有的业务均是通过Python开发的
- 知乎:国内最大的问答社区,通过Python开发(国外Quora)
2.编程语言简介和特点
编程语言主要从以下几个角度为进行分类,小编整理了一些Python学习资料,有需要的朋友可以点击免费领取编译型和解释型、静态语言和动态语言、强类型定义语言和弱类型定义语言,每个分类代表什么意思呢,我们一起来看一下。
2.1.编译和解释型语言的区别
CPU不能直接认识并执行我们写的语句,它只能认识机器语言(CPU指令集;二进制的形式);因此我们开发语言的Virtual Machine要将识别的开发语言转换成机器语言让CPU去执行;那么就有两种以下两种方式:
- 编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;
- 解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,所以运行速度是不如编译后的程序运行的快的.
编译型 解释型 混合型 C Java Script Java C++ Python C# GO Ruby N/A Swift PHP N/A Ojbect-C Perl N/A 2.2.编译和解释型优缺点
编译型
- 优点:编译器一般会有预编译的过程对代码进行优化。因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高。可以脱离语言环境独立运行。
- 缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件。
解释型
- 优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
- 缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。
2.3.静态和动态语言
通常我们所说的动态语言、静态语言是指动态类型语言和静态类型语言。
- 动态类型语言:
动态类型语言是指在运行期间才去做数据类型检查的语言,也就是说,在用动态类型的语言编程时,永远也不用给任何变量指定数据类型,该语言会在你第一次赋值给变量时,在内部将数据类型记录下来。Python和Ruby就是一种典型的动态类型语言,其他的各种脚本语言如VBScript也多少属于动态类型语言。
- 静态类型语言:
静态类型语言与动态类型语言刚好相反,它的数据类型是在编译其间检查的,也就是说在写程序时要声明所有变量的数据类型,C/C++是静态类型语言的典型代表,其他的静态类型语言还有C#、JAVA等。
2.4.强类型和弱类型定义语言
强类型定义语言在速度上可能略逊色于弱类型定义语言,但是强类型定义语言带来的严谨性能够有效的避免许多错误。另外,“这门语言是不是动态语言”与“这门语言是否类型安全”之间是完全没有联系的!
例如:
- Python是动态语言,是强类型定义语言(类型安全的语言); VBScript是动态语言,是弱类型定义语言(类型不安全的语言);
- JAVA是静态语言,是强类型定义语言(类型安全的语言)。
- 强类型定义语言:
强制数据类型定义的语言。也就是说,一旦一个变量被指定了某个数据类型,如果不经过强制转换,那么它就永远是这个数据类型了。举个例子:如果你定义了一个整型变量a,那么程序根本不可能将a当作字符串类型处理。强类型定义语言是类型安全的语言。
- 弱类型定义语言:
数据类型可以被忽略的语言。它与强类型定义语言相反, 一个变量可以赋不同数据类型的值。
通过上面这些介绍,我们可以得出,python是一门动态解释性的强类型定义语言。
3.What is Python?
3.1.Python哲学
Python开发者的哲学是“用一种方法,最好是只有一种方法来做一件事”。在设计Python语言时,如果面临多种选择,Python开发者一般会拒绝花俏的语法,而选择明确没有或者很少有歧义的语法。小编整理了一些Python学习资料,有需要的朋友可以点击免费领取这些准则被称为“Python格言”。在Python解释器内运行import this可以获得完整的列表。
>>> import this The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. ...... ......
- 优雅
语法非常的简短干练,没有一点多余的语法结构。
- 明确
python对格式进行强制的限制;将格式整齐划一,就感觉在写诗一样优雅美丽;
- 简单
在python的设计哲学中:要实现任何一件事情,都应该有一种并且我们认为是最好的一种方式去实现。没有像Perl语言那样花哨,(魔法语言),几乎就是不去调试,你不知道这段代码的逻辑。(几乎5个Perl开发,写出一个功能,就有5种写法出来。不利于团队协作)
3.2.Python优缺点
优点
- 简单易学
特别适合初学者学Python,不但入门容易,而且将来深入下去,可以编写那些非常非常复杂的程序。
- 开发效率高
Python有非常强大的第三方库,基本上你想通过计算机实现任何功能,Python官方库里都有相应的模块进行支持,直接下载调用后,在基础库的基础上再进行开发,大大降低开发周期,避免重复造轮子。
- 高级语言
当你用Python语言编写程序的时候,你无需考虑诸如如何管理你的程序使用的内存一类的底层细节
- 可移植性
由于它的开源本质,Python已经被移植在许多平台上(经过改动使它能够工 作在不同平台上)。如果你小心地避免使用依赖于系统的特性,那么你的所有Python程序无需修改就几乎可以在市场上所有的系统平台上运行
- 可扩展性
如果你需要你的一段关键代码运行得更快或者希望某些算法不公开,你可以把你的部分程序用C或C++编写,然后在你的Python程序中使用它们。
- 可嵌入性
你可以把Python嵌入你的C/C++程序,从而向你的程序用户提供脚本功能。
缺点
- 速度慢
Python 的运行速度相比C语言确实慢很多,跟JAVA相比也要慢一些,因此这也是很多所谓的大牛不屑于使用Python的主要原因,但其实这里所指的运行速度慢在大多数情况下用户是无法直接感知到的,必须借助测试工具才能体现出来,比如你用C运一个程序花了0.01s,用Python是0.1s,这样C语言直接比Python快了10倍,算是非常夸张了,但是你是无法直接通过肉眼感知的,因为一个正常人所能感知的时间最小单位是0.15-0.4s左右,哈哈。其实在大多数情况下Python已经完全可以满足你对程序速度的要求,除非你要写对速度要求极高的搜索引擎等,这种情况下,当然还是建议你用C去实现的。
- 代码不能加密
因为PYTHON是解释性语言,它的源码都是以名文形式存放的,不过我不认为这算是一个缺点,如果你的项目要求源代码必须是加密的,那你一开始就不应该用Python来去实现。
- 多线程问题
这是Python被人诟病最多的一个缺点,GIL即全局解释器锁(Global Interpreter Lock),是计算机程序设计语言解释器用于同步线程的工具,使得任何时刻仅有一个线程在执行,Python的线程是操作系统的原生线程。在Linux上为pthread,在Windows上为Win thread,完全由操作系统调度线程的执行。一个python解释器进程内有一条主线程,以及多条用户程序的执行线程。即使在多核CPU平台上,由于GIL的存在,所以禁止多线程的并行执行。
3.3.Python解释器
当我们编写Python代码时,我们得到的是一个包含Python代码的以.py为扩展名的文本文件。要运行代码,就需要Python解释器去执行.py文件。
由于整个Python语言从规范到解释器都是开源的,所以理论上,只要水平够高,任何人都可以编写Python解释器来执行Python代码(当然难度很大)。事实上,确实存在多种Python解释器。
- CPython
当我们从Python官方网站下载并安装好Python 2.7后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用C语言开发的,所以叫CPython。在命令行下运行python就是启动CPython解释器。
CPython是使用最广的Python解释器。教程的所有代码也都在CPython下执行。
- IPython
IPython是基于CPython之上的一个交互式解释器,也就是说,IPython只是在交互方式上有所增强,但是执行Python代码的功能和CPython是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了IE。
CPython用>>>作为提示符,而IPython用In [序号]:作为提示符。
- PyPy
PyPy是另一个Python解释器,它的目标是执行速度。PyPy采用JIT技术,对Python代码进行动态编译(注意不是解释),所以可以显著提高Python代码的执行速度。
绝大部分Python代码都可以在PyPy下运行,但是PyPy和CPython有一些是不同的,这就导致相同的Python代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到PyPy下执行,就需要了解PyPy和CPython的不同点。
- Jython
Jython是运行在Java平台上的Python解释器,可以直接把Python代码编译成Java字节码执行。
- IronPython
IronPython和Jython类似,只不过IronPython是运行在微软.Net平台上的Python解释器,可以直接把Python代码编译成.Net的字节码。
4.Python2 or 3?
What are the differences?
In summary : Python 2.x is legacy, Python 3.x is the present and future of the language
https://wiki.python.org/moin/Python2orPython3
Python 3.0 was released in 2008. The final 2.x version 2.7 release came out in mid-2010, with a statement of extended support for this end-of-life release. The 2.x branch will see no new major releases after that. 3.x is under active development and has already seen over five years of stable releases, including version 3.3 in 2012, 3.4 in 2014, 3.5 in 2015, and 3.6 in 2016. This means that all recent standard library improvements, for example, are only available by default in Python 3.x.
Guido van Rossum (the original creator of the Python language) decided to clean up Python 2.x properly, with less regard for backwards compatibility than is the case for new releases in the 2.x range. The most drastic improvement is the better Unicode support (with all text strings being Unicode by default) as well as saner bytes/Unicode separation.
Besides, several aspects of the core language (such as print and exec being statements, integers using floor division) have been adjusted to be easier for newcomers to learn and to be more consistent with the rest of the language, and old cruft has been removed (for example, all classes are now new-style, "range()" returns a memory efficient iterable, not a list as in 2.x).
4.1.性能
Py3.0运行 pystone benchmark的速度比Py2.5慢30%。Guido认Py3.0有极大的优化空间,在字符串和整形操作上可以取得很好的优化结果。
- Py3.1性能比Py2.5慢15%,还有很大的提升空间。
- 现在Py3.x已经比Py2.x运行速度要快很多了。
4.2.编码
Py3.x: ALL IS UNICODE NOW
4.3.语法
- PRINT IS A FUNCTION
The statement has been replaced with a print() function, with keyword arguments to replace most of the special syntax of the old statement (PEP 3105). Examples:
2.X: print "The answer is", 2*2
3.X: print("The answer is", 2*2)
2.X: print x, # 使用逗号结尾禁止换行
3.X: print(x, end=" ") # 使用空格代替换行
2.X: print # 输出新行
3.X: print() # 输出新行
2.X: print >>sys.stderr, "fatal error"
3.X: print("fatal error", file=sys.stderr)
2.X: print (x, y) # 输出repr((x, y))
3.X: print((x, y)) # 不同于print(x, y)!
4.4.Rename module
Old Name New Name _winreg winreg ConfigParser configparser copy_reg copyreg Queue queue SocketServer socketserver markupbase _markupbase repr reprlib test.test_support test.support 5.Python安装
官方网站:https://www.python.org/downloads
官方文档:https://docs.python.org/2.7/
5.1.windows
- 默认安装路径:C:\python27
- 配置环境变量
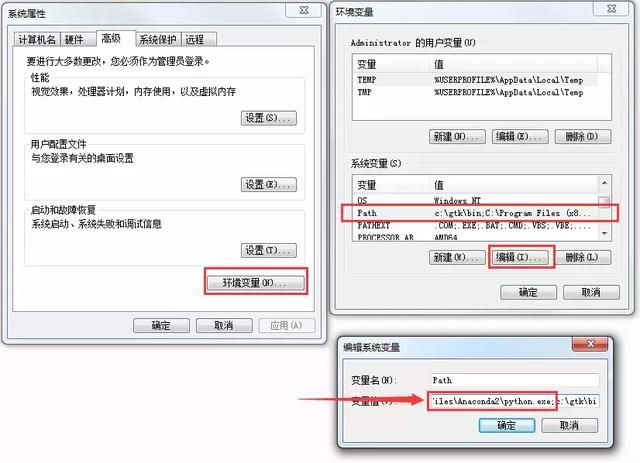
图片来自网络
5.2.Linux、Mac
linux mac平台默认就安装python,如果版本要求达不到,需要重装
- 源代码安装
# tar -zxvf Python-2.7.13-source.tgz
# cd Python-2.7.13
# ./configure --prefix=/${PYTHON_HOME}/python2.7.13
# make
# make install
#调整系统环境变量为python2.7.13
# vi /etc/profile
export PATH=/${PYTHON_HOME}/python2.7.13/bin:$PATH
6.初识Python
6.1.标志性开篇:hello world程序
据传说每一个程序员的第一个程序:Hello World!,从此他们就走上了一条不归路...
6.1.1.解释器执行
$ python
Python 2.7.10 (default, Jun 1 2017, 11:18:18)
[GCC 4.4.7 20120313 (Red Hat 4.4.7-18)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> print('Hello World!')
Hello World!
6.1.2.文件执行
除了直接调用python自带的交互器运行代码,,还可以把程序写在文件里;linux 下创建一个文件叫hello.py,并输入
print("Hello World!")
然后执行命令:python hello.py ,输出
$ python hello_world.py Hello World!
指定解释器
上一步中执行 python hello.py 时,明确的指出 hello.py 脚本由 python 解释器来执行。
如果想要类似于执行shell脚本一样执行python脚本,例: ./hello.py ,那么就需要在 hello.py 文件的头部指定解释器,如下(执行之前记得授权):
$ cat hello_world.py
#!/bin/env python
print("Hello World!")
$ chmod +x hello_world.py
$ ./hello_world.py
Hello World!
如此一来,执行: ./hello.py 即可。
7.开发规范
PEP8英文:http://jython.cn/dev/peps/pep-0008/
PEP8中文:https://python.freelycode.com/contribution/detail/47
7.1.编程风格
7.1.1.缩进统一
- 抒写代码必须顶头写
- 隶属关系的代码必须强制格式缩进
7.1.1.1.以下代码,是否能执行,那个先被执行?
$ vim indent.py #!/bin/env python def main(): print 'Hello World!' print 'test code!' main() $ python indent.py
- 首先来说,隶属于main()函数的代码块是哪个?
- 哪个代码块先被执行?
- 两个代码块都顶头写是否可以?
7.1.1.2.尝试以下代码是否可以?
$ vim indent.py #!/bin/env python def main(): print 'Hello World!' print 'test code!' main()
7.1.2.变量规范
- 标识符第一个字符必须是字母(大写或小写)或者一个下划线 "_"
- 标识符名称的其他部分可以有字母(大写或小写)、下划线"_"或数字(0-9)组成
- 标识符名称是大小写敏感的Myname和myname不是同一个标识符
- 有效标识符: __my_name、name23、alb2_23
- 无效标识符:2things、this is spaced out、my-name
- 变量名尽量要求有意义、能够代表某些含义
- 变量名风格种类:task_detail、taskDetail、TaskDetail
- 关键字不能声明为变量名
- ['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
>>> 3name = 123 File "", line 1 3name = 123 ^ SyntaxError: invalid syntax >>> this is = 'here!' File " ", line 1 this is = 'here!' ^ SyntaxError: invalid syntax
以上是错误的示例
8.变量赋值
计算机科学中不能完全以数学思维方式来思考问题。如变量的赋值实现就和自然科学中数学是不一样的。
以下代码中 x 和 y的结果?
$ cat evaluation.py #!/bin/env python x = 123 y = x x = 456 print 'x: ' ,x print 'y: ' ,y
赋值分析
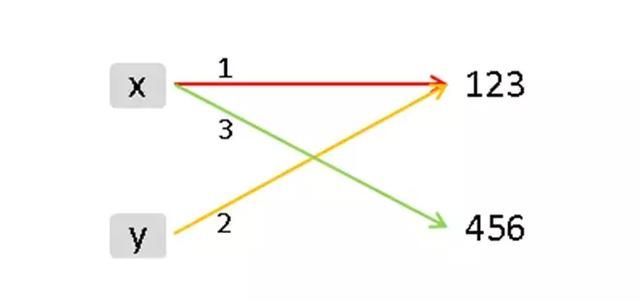
图片来自网络
- x = 2为例,python解释器干了两件事情
- 在内存中创建了一个 2 的整数
- 在内存中创建了一个名为x的变量,并把它指向2
- 代码执行分析
- 1.变量x赋值123,指向内存数据123
- 2.变量y赋值为x,即也是同时指向内存数据123
- 3.变量x赋值456,即从新讲指针指向数据456
9.字符编码
9.1.ASCII
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言,其最多只能用 8 位来表示(一个字节),即:2**8 = 256,所以,ASCII码最多只能表示 256 个符号。
2.x版本python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill)

图片来自网络
显然ASCII码无法将世界上的各种文字和符号全部表示,所以,就需要新出一种可以代表所有字符和符号的编码,即:Unicode
9.2.Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,规定虽有的字符和符号最少由 16 位来表示(2个字节),即:2 **16 = 65536,
注:此处说的的是最少2个字节,可能更多
存储数据要用两个两个字节来表示,主要用于存储中文、韩文等编码格式,但由于字母本身就可以用一个字节来表示,所以都在Unicode的编码下,对于字母型数据,会造成很大的浪费
9.3.UTF-8
UTF-8,是对Unicode编码的压缩和优化,他不再使用最少使用2个字节,而是将所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存...
为解决Unicode字母型数据造成浪费的问题,字母用一个字节表示,中文等用三个字节表示(灵活可变的长度应对不用的类型的数据)
所以,python解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),如果是如下代码的话:
# vim hello_world.py
#!/bin/env python
print('厉害了,word哥')
# python hello_world.py
File "hello_world.py", line 2
SyntaxError: Non-ASCII character '\\xe5' in file hello_world.py on line 2, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
应该显示的告诉python解释器,用什么编码来执行源代码:
# vim hello_world.py
#!/bin/env python
# _*_ coding:utf-8 _*_
print('厉害了,word哥')
10.注释
- 单行注释:
# 被注释内容
- 多行注释:
‘’‘被注释的代码块’‘’
"""被注释的代码块 """
11.用户输入
11.1.格式化打印用户的结果
要求用户输入基本信息后,格式化打印
11.1.1.通过拼接+号的方法实现格式化打印输出,该方法不是最佳的方案,因为每次拼接在内存中需要开辟一块内存空间用于存放拼接的数据,so正确的方法参考一下方法
names = raw_input('Enter your name? ')
age = str(input('Enter your age? '))
job = raw_input('Enter your job? ')
salary = raw_input('Enter your salary? ')
info = """---Personal information of """ + names + """ ---------------
names :""" + names + """
age :""" + age + """
job :""" + job + """
salary :""" + salary
print info
11.1.2.通过占位符的方式,将格式化的结果打印。
# vim raw_input.py
#!/bin/env python
#_*_ coding:utf-8 _*_
__author__ = "Bruce.Liu"
name = raw_input('Please input your name:')
age = raw_input('Age: ')
job = raw_input('Job: ')
print '''
Personal information of %s:
Name: %s
Age : %s
Job : %s
''' % (name, name, age, job)
打印结果,验证
# python raw_input.py Please input your name:Bruce.Liu Age: 27 Job: IT Personal information of Bruce.Liu: Name: Bruce.Liu Age : 27 Job : IT
11.2.3..format方法实现格式化打印
print '''
---Personal information of {_name} ---------------
names : {_name}
age : {_age}
job : {_job}
salary : {_salary}
'''.format(_name=names, _age=age, _job=job, _salary=salary )
12.Module简介
Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的Python库支持,以后的课程中会深入讲解常用到的各种库,现在,我们先来象征性的学2个简单的。
12.1.Module分类
Python有大量的模块,从而使得开发Python程序非常简洁。类库有包括三中:
- Python内部提供的模块
- 业内开源的模块
- 程序员自己开发的模块
12.2.Module实践
12.2.1.SYS Module
- 获取执行脚本的传参
$ vim sys_module.py #!/bin/env python # _*_ coding: utf-8 _*_ import sys print(sys.argv) $ python sys_module.py args1 ['sys_module.py', 'args1']
12.2.2.OS Module
- 调用操作系统命令
$ cat os_module.py
#!/bin/env python
# _*_ coding:utf-8 _*_
import os
os.system("df -h")
- 结合一下
$ cat exec_cmd.py
#!/bin/env python
# _*_ coding:utf-8 _*_
import os,sys
#print sys.argv, ''.join(sys.argv[1])
os.system(''.join(sys.argv[1:]))
$ python exec_cmd.py free
total used free shared buffers cached
Mem: 49374032 34720292 14653740 564 775392 27056956
-/+ buffers/cache: 6887944 42486088
Swap: 8388600 3104 8385496
12.2.3.Custom Module
默认的Cpython解释器,不提供tab键自动补全功能,so Now!我们加一个这种功能;让我们的学习更加简单
12.2.3.1.找到python全局环境变量目录,方便我们将来在任何一个路径下Cpython都能识别到自定义的Module
>>> import sys >>> sys.path ['', '/usr/local/python/lib/python2.7/site-packages/pip-9.0.1-py2.7.egg', '/usr/local/python/lib/python27.zip', '/usr/local/python/lib/python2.7', '/usr/local/python/lib/python2.7/plat-linux2', '/usr/local/python/lib/python2.7/lib-tk', '/usr/local/python/lib/python2.7/lib-old', '/usr/local/python/lib/python2.7/lib-dynload', '/usr/local/python/lib/python2.7/site-packages']
12.2.3.2.在Python默认搜索的路径下创建Module
$ cd /usr/local/python/lib/python2.7/site-packages
$ vim tab.py
#!/bin/env python
try:
import readline
except ImportError:
print ("Module readline not available.")
else:
import rlcompleter
readline.parse_and_bind("tab: complete")
12.2.3.3.导入该Module
$ python Python 2.7.10 (default, Jun 1 2017, 11:18:18) [GCC 4.4.7 20120313 (Red Hat 4.4.7-18)] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> import tab
sys.path会打印Python全局环境变量目录,一般都放在一个叫 Python/2.7/site-packages 目录下,这个目录在不同的OS里放的位置不一样,用 print(sys.path) 可以查看python环境变量列表。
13.pyc文件
pyc是一种二进制文件,是由py文件经过编译后,生成的文件,是一种byte code,py文件变成pyc文件后,加载的速度有所提高,而且pyc是一种跨平台的字节码,是由python的虚拟机来执行的,这个是类似于JAVA或者.NET的虚拟机的概念。pyc的内容,是跟python的版本相关的,不同版本编译后的pyc文件是不同的,2.5编译的pyc文件,2.4版本的 python是无法执行的。
13.1.解释型语言和编译型语言
计算机是不能够识别高级语言的,所以当我们运行一个高级语言程序的时候,就需要一个“翻译机”来从事把高级语言转变成计算机能读懂的机器语言的过程。这个过程分成两类,小编整理了一些Python学习资料,有需要的朋友可以点击免费领取第一种是编译,第二种是解释。
编译型语言在程序执行之前,先会通过编译器对程序执行一个编译的过程,把程序转变成机器语言。运行时就不需要翻译,而直接执行就可以了。最典型的例子就是C语言。
解释型语言就没有这个编译的过程,而是在程序运行的时候,通过解释器对程序逐行作出解释,然后直接运行,最典型的例子是Ruby。
通过以上的例子,我们可以来总结一下解释型语言和编译型语言的优缺点,因为编译型语言在程序运行之前就已经对程序做出了“翻译”,所以在运行时就少掉了“翻译”的过程,所以效率比较高。但是我们也不能一概而论,一些解释型语言也可以通过解释器的优化来在对程序做出翻译时对整个程序做出优化,从而在效率上超过编译型语言。
此外,随着Java等基于虚拟机的语言的兴起,我们又不能把语言纯粹地分成解释型和编译型这两种。
用Java来举例,Java首先是通过编译器编译成字节码文件,然后在运行时通过解释器给解释成机器文件。所以我们说Java是一种先编译后解释的语言。
13.2.Python到底是什么
其实Python和Java/C#一样,也是一门基于虚拟机的语言,我们先来从表面上简单地了解一下Python程序的运行过程吧。
当我们在命令行中输入python hello.py时,其实是激活了Python的“解释器”,告诉“解释器”:你要开始工作了。可是在“解释”之前,其实执行的第一项工作和Java一样,是编译。
熟悉Java的同学可以想一下我们在命令行中如何执行一个Java的程序:
javac hello.java java hello
只是我们在用Eclipse之类的IDE时,将这两部给融合成了一部而已。其实Python也一样,当我们执行python hello.py时,他也一样执行了这么一个过程,所以我们应该这样来描述Python,Python是一门先编译后解释的语言。
13.3.简述Python执行过程

图片来自网络
与java类似,Python将.py编译为字节码,然后通过虚拟机执行。编译过程与虚拟机执行过程均在python25.dll中。Python虚拟机比java更抽象,离底层更远。
编译过程不仅生成字节码,还要包含常量、变量、占用栈的空间等,Pyton中编译过程生成code对象PyCodeObject。将PyCodeObject写入二进制文件,即.pyc。
我们在硬盘上看到的pyc自然不必多说,而其实PyCodeObject则是Python编译器真正编译成的结果。我们先简单知道就可以了,继续向下看。
当python程序运行时,编译的结果则是保存在位于内存中的PyCodeObject中,当Python程序运行结束时,Python解释器则将PyCodeObject写回到pyc文件中。
当python程序第二次运行时,首先程序会在硬盘中寻找pyc文件,如果找到,则直接载入,否则就重复上面的过程。
所以我们应该这样来定位PyCodeObject和pyc文件,我们说pyc文件其实是PyCodeObject的一种持久化保存方式。
14.数据类型简介
Python有五个标准的数据类型:
- Numbers(数字)
- Bool(布尔值)
- String(字符串)
- List(列表)
- Tuple(元组)
- Dictionary(字典)
14.1.Number(数字)
数学复习: http://www.guokr.com/post/432219/
Python支持四种不同的数字类型:
- int(有符号整型)
- long(长整型[也可以代表八进制和十六进制])
- float(浮点型)
- complex(复数)
- bool
14.1.1.int(有符号整型)
- x64系统上,整数的位数为64位,取值范围为-2**63~2**63-1,即-9223372036854775808~9223372036854775807
>>> var1 = 1 >>> print type(var)>>> del var
14.1.2.long(长整型)
- Python的长整数没有指定位宽,即:Python没有限制长整数数值的大小,但实际上由于机器内存有限,我们使用的长整数数值不可能无限大。
- 自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数
>>> var = 2 ** 63 >>> type(var)
14.1.3.float(浮点型)

图片来自网络
- 浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
>>> var2 = 3.1415926 >>> print type(var2)
14.1.4.complex(复数)
- 复数由实数部分和虚数部分组成,一般形式为x+yj,其中的x是复数的实数部分,y是复数的虚数部分,这里的x和y都是实数。
- 注:Python中存在小数字池:-5 ~ 257
>>> aComplex = -8.333-1.47j >>> aComplex.real -8.333 >>> aComplex.imag -1.47
14.2.Bool(布尔值)
- 返回真或假
- 数据值判断Bool值时,0为False、非0为True;像list、str等数据结构时,空值表示False、有值表示Ture
>>> bool(0) False >>> bool(-1) True >>> a = [1,2,3] >>> b = [] >>> bool(a) True >>> bool(b) False
14.3.String(字符串)
python中的字符串在C语言中体现为是一个字符数组,每次创建字符串时候需要在内存中开辟一块连续的空,并且一旦需要修改字符串的话,就需要再次开辟空间,万恶的+号每出现一次就会在内从中重新开辟一块空间。
>>> sehai = "Hello " + "World"
尽量用一下方式:字符串格式化
- 左侧放着一个占位转换说明符,右侧放置格式化的值
- %d:整数型
- %f:浮点型
- %s;字符型
14.3.1.字符型占位符示例
>>> name = "Bruce.Liu" >>> print "i am is %s" % name i am is Bruce.Liu
如果有多个转换说明符时,必须元组的形势存在。否则则抛异常
>>> format = "Hello. %s. %s enough for ya?"
>>> values = ('world','Hot')
>>> print format % values
Hello. world. Hot enough for ya?
14.3.2.整数型占位符示例
- 该示例中,完全可以用%s当做占位符,但是如果输入的值发生数学运算时,最好还是%d比较好
>>> format = '100 + 250 = %d' % 350 >>> print format 100 + 250 = 350
14.3.3.浮点型占位符示例
14.3.3.1.宽度和精度
>>> print 'Pi with three decimals: %10.3f' %(3.1415926) Pi with three decimals: 3.142
14.3.3.2.对齐填充
>>> print '%010.2f' % 3.1415 0000003.14
14.3.3.3.右填充
>>> '%-10.2f' % 3.1415 '3.14 '
14.4.List(列表)
- List(列表) 是 Python 中使用最频繁的数据类型。
- 列表可以完成大多数集合类的数据结构实现。它支持字符,数字,字符串甚至可以包含列表(即嵌套)。
>>> l_res = ['HanXiang','ShenZhen','IT'] >>> l_res[0] 'HanXiang'
14.5.Tuple(元组)
- 元组是另一个数据类型,类似于List(列表)。
- 元组用"()"标识。内部元素用逗号隔开。但是元组不能二次赋值,相当于只读列表。
>>> tuple_res = ('SQL result','...')
>>> tuple_res[0]
'SQL result'
14.6.Dictionary(字典)
- 字典(dictionary)是除列表以外python之中最灵活的内置数据结构类型。列表是有序的对象结合,字典是无序的对象集合。
- 两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
- 字典用"{ }"标识。字典由索引(key)和它对应的值value组成。
>>> emp_info = {'name':'Bruce','job':'IT'}
>>> emp_info['name']
'Bruce'
15.作业
- 在windows上安装python2.7.10以上的Cpython
- 在linux上安装pyhton2.7.10以上的Cpyhton
- 安装配置好Pycharm IDE,实现在windows上开发完成后,代码自动上传至linux服务器
- 附录
- Python前世今生
- 编程语言简介和特点
- What is Python?
- Python2 or 3?
- Python安装
- 初识Python
- 开发规范
- 变量赋值
- 字符编码
- 注释
- 用户输入
- Module简介
- pyc文件
- 数据类型基础
- 作业