Hugging Face——MLM预训练掩码语言模型方法
对于许多涉及 Transformer 模型的 NLP 程序, 我们可以简单地从 Hugging Face Hub 中获取一个预训练的模型, 然后直接在你的数据上对其进行微调, 以完成手头的任务。只要用于预训练的语料库与用于微调的语料库没有太大区别, 迁移学习通常会产生很好的结果。
但是, 在某些情况下, 你需要先微调数据上的语言模型, 然后再训练特定于任务的head。
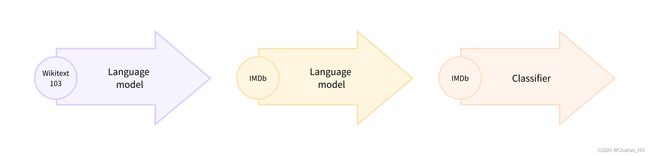
这种在域内数据上微调预训练语言模型的过程通常称为 领域适应。 它于 2018 年由 ULMFiT推广, 这是使迁移学习真正适用于 NLP 的首批神经架构之一 (基于 LSTM)。 下图显示了使用 ULMFiT 进行域自适应的示例; 在本节中, 我们将做类似的事情, 但使用的是 Transformer 而不是 LSTM!
如何训练?
加载模型
依托于Hugging Face,根据提供的API,选择AutoModelForMaskedLM用于加载模型:
from transformers import AutoModelForMaskedLM
model_checkpoint = "Hub中的仓库/模型名称"
model = AutoModelForMaskedLM.from_pretrained(model_checkpoint)
AutoModelForMaskedLM在源码中已经默认给配置好了MLM的 Head,这里以BERT为例——BertForMaskedLM
在源码中可以先锁定到forward方法中:
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
labels: Optional[torch.Tensor] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], MaskedLMOutput]:
r"""
labels (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*):
Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, ...,
config.vocab_size]` (see `input_ids` docstring) Tokens with indices set to `-100` are ignored (masked), the
loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`
"""
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
outputs = self.bert(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
encoder_hidden_states=encoder_hidden_states,
encoder_attention_mask=encoder_attention_mask,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
sequence_output = outputs[0]
prediction_scores = self.cls(sequence_output) # 这是相比于BERTModel不同的地方
代码中self.cls是这样定义的:
self.cls = BertOnlyMLMHead(config)
代码中BertOnlyMLMHead是这样定义的:
class BertOnlyMLMHead(nn.Module):
def __init__(self, config):
super().__init__()
self.predictions = BertLMPredictionHead(config)
def forward(self, sequence_output: torch.Tensor) -> torch.Tensor:
prediction_scores = self.predictions(sequence_output)
return prediction_scores
继续套娃,BertLMPredictionHead是这样定义的:
class BertLMPredictionHead(nn.Module):
def __init__(self, config):
super().__init__()
self.transform = BertPredictionHeadTransform(config)
# The output weights are the same as the input embeddings, but there is
# an output-only bias for each token.
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
self.decoder.bias = self.bias
def forward(self, hidden_states):
hidden_states = self.transform(hidden_states)
hidden_states = self.decoder(hidden_states)
return hidden_states
终于破案了, 最后就是一个线性层,并且维度大小是config.hidden_size * config.vocab_size。这也就是对整个词库做预测了,与BERT的原文对应起来
加载数据集
根据自己的任务场景的不同,选择对应的文本数据即可。
需要说明的是,在训练MLM的过程中是使用的CrossEntropy Loss,这里以Pytorch封装的交叉熵损失函数为例,其中有一个参数为ignore_index,这个参数的含义如下:
- Specifies a target value that is ignored and does not contribute to the input gradient. When
size_averageisTrue, the loss is averaged over non-ignored targets. Note thatignore_indexis only applicable when the target contains class indices.- 简单来说就是对于索引为ignore_index的target class,损失函数不予以计算,默认的ignore_index的值为**-100**。
综上只需要在打标签的时候,对于没有参与MASK的位置,选择其label为-100即可。换句话说,除了与掩码对应的标签外, 所有的标签均为 -100。
下面是两个关于构建MASK text的代码:
def create_masked_lm_probability(
tokenizer,
inputs_feature: torch.Tensor,
special_tokens_mask: Optional[torch.Tensor] = None,
mlm_probability:float=0.15,
mask_probability:float=0.8,
replace_probability:float=0.5):
"""
@param :
tokenizer: Hugging Face tokenizer
inputs_feature: (BS, length) , where the length include a [CLS] token and two [SEP] tokens that placed middle and last
-------
@Returns :
The shape of inputs is (BS, length)
The shape of labels is (BS, length)
-------
@description :
Prepare masked tokens inputs/labels for masked language modeling: 80% probability MASK, 10% probability random, 10% probability original.
---------
"""
inputs = inputs_feature.clone()
labels = inputs_feature.clone()
# We sample a few tokens in each sequence for MLM training (with probability `self.mlm_probability`)
probability_matrix = torch.full(labels.shape, mlm_probability)
if special_tokens_mask is None:
special_tokens_mask = [
tokenizer.get_special_tokens_mask(val, already_has_special_tokens=True) for val in labels.tolist()
]
special_tokens_mask = torch.tensor(special_tokens_mask, dtype=torch.bool)
else:
special_tokens_mask = special_tokens_mask.bool()
probability_matrix.masked_fill_(special_tokens_mask, value=0.0)
masked_indices = torch.bernoulli(probability_matrix).bool()
labels[~masked_indices] = -100 # We only compute loss on masked tokens(The value of 'ignore_index' is -100 in nn.CrossEntropyLoss)
# 80% of the time, we replace masked input tokens with tokenizer.mask_token ([MASK])
indices_replaced = torch.bernoulli(torch.full(labels.shape, mask_probability)).bool() & masked_indices
inputs[indices_replaced] = tokenizer.convert_tokens_to_ids(tokenizer.mask_token)
# 10% of the time, we replace masked input tokens with random word
indices_random = torch.bernoulli(torch.full(labels.shape, replace_probability)).bool() & ~indices_replaced & masked_indices
random_words = torch.randint(100+3, len(tokenizer), labels.shape, dtype=torch.long) # The All tokens befer num 100 are [unused] token in Hugging Face tokenizer
inputs[indices_random] = random_words[indices_random]
# The rest of the time (10% of the time) we keep the masked input tokens unchanged
return inputs, labels
def create_masked_lm_predictions(
tokenizer,
inputs_feature: torch.Tensor,
special_tokens_mask: Optional[torch.Tensor] = None,
mlm_probability:float=0.15,
mask_probability:float=0.8,
replace_probability:float=0.5):
"""
@param :
@param :
tokenizer: Hugging Face tokenizer
inputs_feature: (BS, length) , where the length include a [CLS] token and two [SEP] tokens that placed middle and last
-------
@Returns :
The shape of inputs is (BS, length)
The shape of labels is (BS, length)
-------
@description :
Prepare masked tokens inputs/labels for masked language modeling: 80% MASK, 10% random, 10% original.
Reference: https://github.com/google-research/bert/blob/eedf5716ce1268e56f0a50264a88cafad334ac61/create_pretraining_data.py#L342
---------
"""
labels = torch.full(inputs_feature.shape, -100) # We only compute loss on masked tokens(The value of 'ignore_index' is -100 in nn.CrossEntropyLoss)
maskToken_id = tokenizer.mask_token_id
for idx, sentence in enumerate(inputs_feature):
shuffle_idx = []
for i, token in enumerate(sentence):
if token == tokenizer.cls_token_id or token == tokenizer.sep_token_id or token == tokenizer.pad_token_id:
continue
shuffle_idx.append(i)
assert len(shuffle_idx)>0
random.shuffle(shuffle_idx)
num_to_predict = max(1, int(round(len(shuffle_idx) * mlm_probability)))
for index in shuffle_idx[:num_to_predict]:
# 80% of the time, replace with [MASK]
if random.random() < mask_probability:
labels[idx][index] = inputs_feature[idx][index]
inputs_feature[idx][index] = maskToken_id
else:
# 10% of the time, keep original
if random.random() < replace_probability:
pass
# 10% of the time, replace with random word
else:
labels[idx][index] = inputs_feature[idx][index]
inputs_feature[idx][index] = random.randint(100+3, len(tokenizer) - 1)
return inputs_feature, labels
create_masked_lm_probability是来自于SimCSE的代码来写的;而create_masked_lm_predictions是根据BERT原文改写的;
我发现两者是有一些区别的,区别在于**百分比(%)**的定义。
BERT的MLM的策略是选择15%的token来做掩码,这15%中,有80%是用[MASK]来代替,剩下的10%随机替换,10%保持不变。
在create_masked_lm_probability中,SimCSE的作者是采用了整体的15%的概率来选择的,其中80%的概率用[MASK],剩下的一样。也就是说100个token中,有15%*80%概率的token数量是被替换成[MASK]的,剩下的同理。
但是create_masked_lm_predictions中,即BERT的作者是整体长度的15%来选择的,也就是说100个token中,必然有12(100*0.15*0.8)个token是为[MASK]的,而SimCSE的作者的做法不一定为12个token为[MASK]。
以上就是两者的细微区别。我个人感觉两种方法都是可以的。
剩下的就是不断地训练Model即可;用Trainer API也可以,用手动搭建的也可以。