Yolov5训练自制数据集
一、准备
1.项目链接
https://github.com/ultralytics/yolov5
2.制作数据集
将标注好的图片放到data/images/train 和data/images/valid 文件夹下,将.xml标签统一放在data/Annotations文件夹下
使用txt_write.py生成data/ImageSets/Main下的valid.txt和train.txt
import os
def build_train_valid_list(train_txt,train_imgs_dir,valid_txt,valid_imgs_dir):
sets = [(train_txt, train_imgs_dir), (valid_txt, valid_imgs_dir)]
for s in sets:
txt, imgs_dir = s
# print(txt)
with open(txt, "a+") as f:
for img_name in os.listdir(imgs_dir):
head, back = img_name.split(".")[0], img_name.split(".")[1]
print(head)
f.write(head)
f.write("\r")
f.flush()
if __name__ == '__main__':
train_imgs_dir = "data/images/train"
valid_imgs_dir = "/data\images/valid"
train_txt = "data/ImageSets/Main/train.txt"
valid_txt = "data/ImageSets/Main/valid.txt"
build_train_valid_list(train_txt,train_imgs_dir,valid_txt,valid_imgs_dir)train.txt和valid.txt文件的数据如下(去除文件的后缀)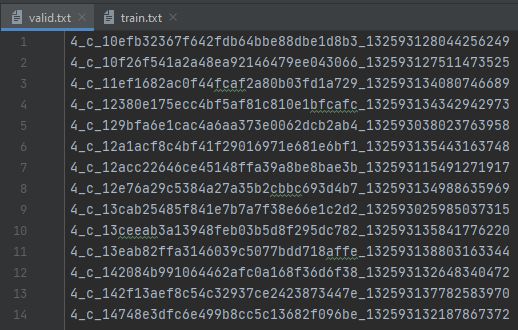
3.生成所需的txt文件
更改xml_2_txt.py文件的中训练的类别

更改xml_2_txt.py文件中的in_file的路径与out_file的路径

运行xml_2_txt.py
import xml.etree.ElementTree as ET
import os
sets = ['train', 'valid']
classes = ['tjfy','tjzp','tjpm','c','qr'] # 更改为自己训练的类别
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_set,image_id):
in_file = open(r'F:\yolov5_Test\data\Annotations/%s.xml' % (image_id)) #修改路径
out_file = open(r'F:\yolov5_Test\data\labels/{}/{}.txt' .format(image_set,image_id), 'w') #修改路径
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
for image_set in sets:
if not os.path.exists('data/labels/{}'.format(image_set)):
os.makedirs('data/labels/{}'.format(image_set))
image_ids = open('data/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
print(image_ids)
for image_id in image_ids:
convert_annotation(image_set,image_id)在data/labels/train和data/labels/valid目录下生成训练所用的txt标签文件
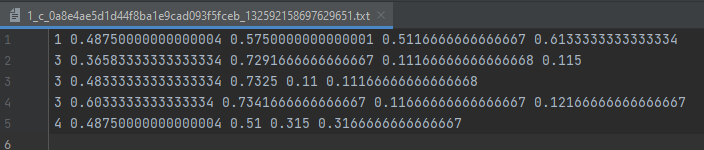
txt标签文件内容如下
4.在data/下建立自己的.yaml文件

5.修改model/文件夹下所要使用的预训练模型的yaml文件
修改yolov5s.yaml文件如下:

只需要更改类别数nc:即可
二、训练
6.修改train.py文件中的相关参数:

7.运行train.py文件
正常训练

8.使用tensorboard或者wandb工具查看实时训练状态
(1)tensorboard
打开cmd命令行输入tensorboard --logdir F:\yolov5_Test\runs\train ,其中F:\yolov5_Test\runs\train 更改为自己的路径

将返回的地址输入到浏览器中即可查看训练状态

(2)wandb

根据提示打开链接即可看到训练结果:

三、测试
9.更改detect.py中的参数
保存的训练数据在runs/train/文件夹下

例如修改detect.py中的相关参数如下

运行detect.py生成的预测图片保存在runs/detect/文件夹下
预测结果如下:

四、出现问题
1.gbk错误
gbk’codec can’t decode byte 0xae
解决方法:
在train.py中第61行修改为:
with open(opt.data,encoding="utf8") as f:在test.py中第69行修改为:
with open(data,encoding="utf8") as f:2.dll错误
Initializing libiomp5md.dll, but found libiomp5md.dll already initialized.
解决方案:在train.py的开头添加
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'3.wandb错误
api_key not configured (no-tty). Run wandb login
解决方案:
打开终端:
pip install wandb
wandb login按照提示打开链接:You can find your API key in your browser here: https://wandb.ai/authorize
登录并获取key,输入到终端: Paste an API key from your profile and hit enter:
配置成功(重新训练发现错误消失):Appending key for api.wandb.ai to your netrc file: /home/username/.netrc