【姿态估计】 深度图姿态识别应用调研
人体姿态识别
人体姿态是人体重要的生物特征之一,有很多的应用场景,如:步态分析、视频监控、增强现实、人机交互、金融、移动支付、娱乐和游戏、体育科学等。姿态识别能让计算机知道人在做什么、识别出这个人是谁。特别是在监控领域、在摄像头获取到的人脸图像分辨率过小的情况下是一个很好的解决方案,还有在目标身份识别系统中可以作为一项重要的辅助验证手段,达到减小误识别的效果。
专利相关
基于深度相机识别人体头部姿态的方法及装置
(中国科学院自动化研究所,201810232468.1)
本发明提供一种基于深度相机识别人体头部姿态的方法,包括基于深度相机的相机参数将深度相机获取的头部深度图像转化为空间点云数据;将空间点云数据所在的空间划分为多个子空间,若子空间包含的空间点云数据的个数大于预设阈值,则将子空间的中心点作为标准点云数据;计算标准点云数据与预先构建的头部模型的拟合误差,得到人体头部的姿态参数。
一种基于深度学习的人体姿态识别方法
(天津科技大学,201811177283.1)
该方法首先用Kinect V2.0深度传感器采集多个人体样本的动作姿态特征;保存其人体动作姿势的RGB数据和骨骼数据;把骨骼数据经过图像预处理后得到骨骼图像作为训练集与测试集;将训练集输入一种基于卷积神经网络(CNN)的专用于人体姿态识别领域的Posture‑CNN中,经过训练、测试调整网络结构和网络参数后得到分类结果;并将不同人体样本的动作姿态特征作为测试集输入分类网络,输出概率最大的动作即为识别结果。本发明使用卷积神经网络提高了识别准确率,降低了识别时间、运行成本低、方法简便可以应用在智能家居、安全监控、运动分析等场所。
基于深度图像和虚拟数据的驾驶人姿态识别方法
(南京理工大学,201810195342.1)
本发明公开了一种基于深度图像和虚拟数据的驾驶人姿态识别方法,驾驶人关节点检测:将驾驶人深度图像和关节点标签作为深度学习框架Caffe的输入,训练深度卷积神经网络模型;利用深度学习模型检测图像中驾驶人的关节点位置。虚拟驾驶人头部姿态数据集构建:利用三维建模软件的建模功能Modeling构建驾驶人模型;利用动画功能Animation设置驾驶人头部运动;利用渲染功能Rendering批量渲染驾驶人图像;对驾驶人图像进行头部分割处理,构建虚拟驾驶人头部姿态数据集。驾驶人头部姿态分析:利用由虚拟驾驶人头部姿态数据集构建过程获取的虚拟驾驶人头部姿态数据,采用迁移学习的方法,训练深度迁移学习模型;根据深度迁移学习模型,估计目标域图像中驾驶人头部姿态,并检测其面部特征点位置。
深度学习检测驾驶人图像中的关节点位置→构建三维模型→模型分割与状态分析→迁移学习用于检测其他图像。
[ ](javascript: alertinfo(‘http://pic.cnipr.com:8080/XmlData/fm/20180731/201810195342.1/201810195342.gif’,‘’,0)
](javascript: alertinfo(‘http://pic.cnipr.com:8080/XmlData/fm/20180731/201810195342.1/201810195342.gif’,‘’,0)
一种手部姿态识别方法及识别系统
(北京康邦科技有限公司,201710505926.X)
该方法包括:提取初步深度图像中的深度局部梯度特征数据形成手部初步姿态特征数据;手部初步姿态特征数据通过手部姿态分类器形成手部当前姿态数据;通过存储索引确定与手部当前姿态数据接近的手部标准姿态数据并对比确定与手部当前姿态对应的手部标准姿态。本发明克服了受深度图像中的深度数据空洞和噪声影响使得分类器预测结果误差较大的缺陷。通过存储索引使得挑选的若干手部标准姿态分布在预测出的手部姿态附近,进一步提高了识别过程的鲁棒性。
[ ](javascript: alertinfo(‘http://pic.cnipr.com:8080/XmlData/fm/20171103/201710505926.X/201710505926.gif’,‘’,0)
](javascript: alertinfo(‘http://pic.cnipr.com:8080/XmlData/fm/20171103/201710505926.X/201710505926.gif’,‘’,0)
一种基于深度摄像头的动作姿态捕捉系统
(武汉子序科技股份有限公司,201910596094.6)
本发明公开了一种基于深度摄像头的动作姿态捕捉系统,包括深度摄像头模块,用于获取深度图像;区域分割模块,用于对人体像素区域进行模式识别,并将人体区域从深度图像的背景区域中分割出来,解析出人体的骨骼数据。本发明追踪重建骨骼系统中各个关节点数据,并根据追踪到的骨骼数据定义体感语义,基于体感语义制定动作指令映射表,利用调用模块手势识别输入指令等,提高了增强现实系统的捕捉精度,提高了手势捕捉效率。
姿态识别方法、装置、计算机设备和存储介质
(爱菲力斯(深圳)科技有限公司,201911171902.0)
获取深度图像→对深度图像进行关键点检测,获得人体关键点集合→根据人体关键点集合,得到预设的人体不同的部位所构成的向量→根据向量,识别人体姿态,准确识别出摄像机拍摄的各个角度和位置下的人体姿态。
头部姿态识别方法及系统
(比亚迪股份有限公司,201310188582.6)
本发明提出了一种头部姿态识别方法,包括以下步骤:采集车辆驾驶室的景物的深度图;对深度图进行分割以得到驾驶员的头肩区域与背景区域;建立坐标系,并将头肩区域映射到坐标系中;根据至少两帧深度图的头肩区域在坐标系中的位置判断驾驶员的头部姿态以及头部姿态是否发生变化。根据本发明实施例的头部姿态识别方法,具有高的识别精度,且该方法操作简单,易于实现。
一种基于多深度图像特征融合的人体姿态估计方法
(浙江工业大学,201911403474.X)
一种基于深度和彩色图像特征融合的人体姿态估计方法
(浙江工业大学,201911403496.6)
通过融合深度和彩色图像信息,有效地减少了对手持物的误识别,同时提高了对光照变化的鲁棒性。本发明提供一种基于深度和彩色图像特征融合的人体姿态估计方法,有效地提高了人体姿态估计的精确度和鲁棒性。
基于人体姿态识别的体育教学辅助系统和方法
(深圳泰山体育科技股份有限公司,201710513951.2)
本发明公开了一种基于人体姿态识别的互动式体育教学辅助系统和方法,系统包括:深度摄像装置,用于获取用户动作深度图像序列和标准动作深度图像序列;普通摄像装置,用于获取标准动作示范图像序列;标准动作训练单元,用于建立标准动作模型;标准动作存储单元,用于存储标准动作模型和标准动作示范图像序列;显示终端,用于向用户显示标准动作示范图像序列;动作比较单元,用于将预定时间点或时间段的用户动作深度图像序列与对应时间点或时间段的标准动作模型比较,获取用户动作与标准动作模型的差异;提示装置,用于根据差异向显示装置输出动作评价或动作纠正提示信息。
一种针对单一深度图像的3D人体姿态估计算法
(北京工业大学,201711406248.8)
本发明公开一种基于单一深度图像的3D人体姿态估计方法。首先提出改进型特征提取办法,综合利用部位尺寸信息和距离变换信息,来指导深度梯度特征提取,可极大增强所提特征的表达能力;为解决随机森林部位分类时存在的误分类问题,提出误分类处理机制—多级随机森林整合算法来去除部位误分点,获得更为准确的部位识别结果;通过改进PDA,利用位置权重阈值处理办法,使能够利用识别的部位尺寸信息,自适应的再次去除部位中的干扰点,从而获得更为准确的主方向向量;最后利用人体部件配置关系得到姿态估计结果。本发明改善了部位分类模型的准确率,并能有效去除识别部位中的误分类干扰点,提高识别部位的准确性,最终获得更为准确的3D人体姿态估计结果。
一种基于RGBD相机的堆叠工件姿态识别及拾取方法
(同济大学,201810326638.2)
本发明涉及一种基于RGBD相机的堆叠工件姿态识别及拾取方法,包括以下步骤:1)对RGBD相机内参数进行标定;2)根据预先获得的待抓取工件的3D模型进行训练,生成用以匹配的2D模型;3)利用RGBD相机获取待识别工件的RGB图像和深度图像,获取出待抓取工件的轮廓信息;4)获取待抓取工件在图像像素坐标系中的二维位置信息以及在相机坐标系下的六自由度位姿;5)获取待抓取工件在机器人坐标系下的六自由度位姿;6)控制六轴机器人对待抓取工件进行拾取。
一种基于迁移学习和深度特征融合的行人重识别方法
(中电科大数据研究院有限公司,201910329733.2)
本发明提供了一种基于迁移学习和深度特征融合的行人重识别方法,包括以下步骤:预训练‑人体姿态矫正和分割‑特征向量‑深度特征融合‑训练模型‑测试模型‑识别结果。本发明通过利用深度卷积神经网络提取行人全局和局部特征,对两种特征进行深度融合获得最终的行人特征表征,然后在深度卷积神经网络训练过程中,采用迁移学习的方式进而获得效果更好的行人重识别网络模型,最终使得行人重识别网络模型提取的特征具有更强的分辨能力,从而达到提升行人重识别准确率的目的。
基于深度摄像机的人群聚集监控识别系统
(北京航天长峰科技工业集团有限公司,201611001982.1)
一种基于深度摄像机的人群聚集监控识别系统,主要包括(1)视频操作模块:包括实时视频预览、视频轮巡预案、历史视频检索、摄像机控制和视频导出功能;(2)深度应用模块:提供人员聚集异常风险的实时动态姿态检测功能;(3)系统功能模块:提供必要的包括报警事件信息检索、系统设备运行状态监测、设备配置和用户权限管理以及日志管理等系统功能;(4)数据存储模块:系统设置专门的中心数据库进行各类数据的存储,包括必要的业务数据、下载的图像数据、报警导出视频、系统信息数据。
一种篮球动作模型重建和防守的指导系统及方法
(华南理工大学,201710362557.3)
本发明公开的一种篮球动作模型重建和防守的指导系统,包括完成篮球动作信息提取的Kinect深度传感器、深度学习模块,以及篮球动作姿态重建模块;其中深度学习模块,通过深度学习对篮球动作进行分类,并将一系列图片中的篮球动作骨骼坐标点所对应的深度值、Kinect深度传感器中的相机坐标系的坐标值保存;篮球动作姿态重建模块,根据保存的骨骼关节点的三维坐标,对一个完整的篮球动作进行重建;在运动员训练时进行相应的指导。本发明结合深度学习技术,实现基本篮球动作的识别和统计。
一种智能手机坐姿监督与报警系统及方法
(四川长虹电器股份有限公司,201811320448.6)
本发明公开了一种智能手机坐姿监督与报警系统,包括标准姿态录入系统、实时姿态检测系统和报警记录系统;标准姿态录入系统包括标准姿态图像采集组件、眼镜空间范围判定组件,实时姿态检测系统包括实际姿态图像采集组件、眼镜空间位置判定组件,报警记录系统包括报警组件。本发明的系统应用于智能手机上,以深度学习神经网络为核心,以使用者佩戴的眼镜为识别目标,来计算出使用者头部空间位置,进而判断使用者当前眼睛与书本或者电脑的距离是否足够,从而间接的判断使用者坐姿是否端正。
一种基于Kinect的手势遮挡检测方法及系统
(济南大学,201910094427.5)
本发明提供了一种基于Kinect的手势遮挡检测方法及系统,包括:S1、利用Kinect分别获取深度图像以及彩色图像;S2、将深度图像二值化,并与彩色图像进行与运算,得到只有人手区域的彩色图像;S3、统计最大连通区域与肤色区域的比值判断是否存在手势被遮挡;S4、计算获取存在遮挡或不存在遮挡时的预测手势姿态。本发明通过Kinect获取手势的深度图像及其对应的彩色图像,通过图像与运算将彩色手势分割出来,然后用统计最大连通区域与肤色区域的比值判断是否存在手势被遮挡的情况,并通过手势估计算法预测出手势姿态,从而解决由于遮挡问题导致的手势无法识别的问题,实现提高手势识别准确率。
疲劳驾驶预警方法和疲劳驾驶预警装置
(南京华捷艾米软件科技有限公司,201910215505.2)
本发明公开了一种疲劳驾驶预警方法及装置。包括:步骤S1、实时获取驾驶人员的深度图像数据和彩色图像数据;步骤S2、基于所述彩色图像数据,识别所述驾驶人员的人脸关键信息;步骤S3、基于所述深度图像数据,识别所述驾驶人员的身体姿态信息;步骤S4、根据所述人脸关键信息和所述身体姿态信息,确定所述驾驶人员是否存在疲劳驾驶。本发明的疲劳驾驶预警方法和装置,通过结合彩色图像数据和深度图像数据,可以极大提高车载疲劳预警系统的准确性,从而能够有效保证驾驶人员的安全,避免安全隐患的发生。
用于自然人机交互的多姿态指尖跟踪方法
(电子科技大学,201610070474.2)
本发明公开了一种用于自然人机交互的多姿态指尖跟踪方法,包括以下步骤:S1:采用Kinect2获取RGBD数据,包括深度信息和彩色信息;S2:对手部区域进行检测:通过颜色空间的转换,把色彩转换到对亮度反应不明显的空间进而检测肤色区域,然后通过人脸检测算法检测出人脸,从而排除人脸区域得到手部区域,并求出手部的中心点;S3:通过深度信息,并且结合HOG特征与SVM分类器对特定手势进行识别、检测;S4:通过前几帧指尖的位置,再结合手部识别出来的区域进行一个当前跟踪窗口的预测,然后通过基于深度的指尖检测和基于形态的指尖检测两种模式对指尖进行检测、跟踪。本发明主要处理运动下的、各种姿态下的单一指尖的检测与跟踪,并且需要保证较高的精度和较好的实时性。
基于视觉实现手势识别的系统和方法
(北京邮电大学,201910865437.4)
基于视觉实现手势识别的系统,包括如下模块:手部检测模块、手部姿态估计模块和手部姿态估计模块;基于视觉实现手势识别的方法,包括下列操作步骤:(1)将对齐的RGB图片输入到手部检测模块中,得到手的边界框;(2)手部姿态估计模块截取深度图中对应的手的部分,得到手部关键关节点的3D坐标;(3)将所述手部关键关节点的3D坐标输入到手势识别模块,得到数字手势编码;(4)根据数字手势编码,对手势进行相似度度量,从而实现手势识别;本发明的系统和方法具有良好的准确率、实时性和鲁棒性。
一种人体姿态检测方法及装置
(北京格灵深瞳信息技术有限公司,201510454385.3)
本发明提供了一种人体姿态检测方法及装置,包括:接收含有人体的第一深度图像;将所述第一深度图像转化为三维云模型;根据预先得到的人体姿态气泡模型和所述三维云模型进行优化拟合;其中,所述预先得到的人体姿态气泡模型是根据预先检测到的人体骨架关节点得到的;根据所述优化拟合结果得到所述第一深度图像中人体骨架关节点坐标值;根据所述第一深度图像中人体骨架关节点坐标值得到所述人体的姿态。
利用深度摄像头对车辆或行人进行识别的检测装置及方法
(上海美迪索科电子科技有限公司,201610378475.3)
本发明公开的利用深度摄像头对车辆或行人进行识别的检测装置,包括:分布在停车场各个路口处的深度摄像头,深度摄像头获取当前场景中各像素点的深度距离信息,并对深度距离信息进行处理形成深度图像;分别与每一深度摄像头连接的深度图像的控制处理单元,控制处理单元遍历每一帧深度图像中的全部像素点,并对每一帧深度图像进行处理形成与其相对应的深度直方图,判断深度直方图在预计距离范围内是否出现波峰,若判断出现波峰,则对该帧深度图像进行区域分割并进行边缘检测,根据目标特征点的分类和姿态检测方法识别车辆或行人。本发明识别的三维特征更多,识别准确度更高,基本不受环境影响,在夜间及阴雨天气的情况下也可以正常工作。
原理:
人体动作姿态识别是由计算机在初始数据中检测出动作信息,即运动目标检测过程。人体动作姿态的识别方法可分为三类:基于统计的方法、基于模板的方法和基于语法的方法。其中基于统计的方法将图像序列中的每个静态姿势或运动状态作为一个状态节点,这些状态节点之间由给定的概率联系起来;基于模板的方法是将图像序列转换成一组静态形状模型,然后在识别过程中用于输入图像序列提取的特征与在训练阶段预先存储的动作行为模板进行相似度比较以识别人体行为;基于语法的方法是对一段持续时间内场景内容的分析过程。
数据集
深度数据集:
ITOP数据集:ITOP是Albert Haque[13]采集的关于人体姿态深度图的数据集,该数据集提供了关于人体姿态正面视角和俯视视角的深度图像。该数据集提供了 39795 张训练的深度图像,每个图像对应一组二维坐标和三维坐标。ITOP 数据集是以 h5 的文件格式保存,包含了大小为 240 × 320 的深度图像数据、二维人体关节点坐标和三维人体关节点坐标。
图像处理方法:
图像处理主要是为了消除图片中由于外界环境变化导致的光照、噪音、振动以及图像模糊等问题,提高图像的检测精度.较有代表性的图像处理方法有参考白、同态滤波、均值滤波、中值滤波、数学形态学方法、直方图均衡化、图像平滑和锐化等。
图像二值化:图像像二值化含义是使图像上的每个像素点的灰度值变为 0 或
255。从人的视觉角度来看,也就是整幅图像变成只有黑色和白色。这个最重要的目
的是为了使图像的进一步处理更为方便,图像更加简单,减少数据量的同时,目标
的整体和局部特征还可以保留。
**归一化:**这里主要是将图片的格式和大小进行统一,方便后续将数据传入神
经网络时,能够统一操作。
均值滤波所采用的主要方法为邻域平均法,就是在使用移动的矩形方框的时候,将方框所圈住的区域中所有的像素进行平均运算再替换到原图像的每个像素点。但这种方式带来的缺陷也是显而易见的,它容易模糊图像的细节信息,尽管也能去掉部分噪声信息。
高斯滤波:高斯滤波器常用来去除高斯噪声,由于自然界的噪声随机性很强,但是根据数学理论上的推导可以将这些无分布规律的噪声看成是一种类似高斯噪声的噪声,因此,使用高斯滤波去噪声比较常用。
**中值滤波:**中值滤波基本理论与均值噪声类似,这里只是使用像素值得中值点带代替其他的像素点,但是该方法确比均值滤波有更大优势,可以减少椒盐噪声和脉冲噪声,对高频信息的保留也更为全面,主要是由于它会过滤掉一块区域中数值特别大的像素点,这种点在含有椒盐噪声和脉冲噪声的图像中,被认为噪声的可能性很大,所以能得到较好的结果。

特征检测方法:
归一化RGB肤色检测模型是通过计算RGB通道像素关系范围而得到,对人姿态的特征区域描述效果较好,不会出现较多的干扰点,但对细部描绘效果一般;
YCrCb肤色检测将色度与光度分离,通过色度检测肤色,虽然现实中改变光照,色度也会相应地产生改变,但仍在一定程度上可降低光度的影响。YCrCb模型方法对驾驶人姿态的细部描绘较好,能准确检测出驾驶人眼睛、耳朵、手指等微观区域,但是对类皮肤区域的去干扰能力较差。
2D人体骨骼检测:

3D人体骨骼检测:
方法一:2D骨骼关键点+三为人体重建
首先使用2D人体骨骼关键点检测的方法检测出2D的人体骨骼关键点后,再使用3D重建的方式,将2D的关键点信息转到3D的空间中,输出的就是3维人体骨骼关键点信息。
方法二:RGBD数据

2015年之前的方法都是回归出精确的关节点坐标(x, y),采用这种方法不好的原因是人体运动灵活,模型可扩展性较差。过去的方法主要存在三方面的问题:(1)遮挡问题,这个问题是最难的,也是必须要解决的。(2)速度过慢。(3)仅仅有二维的姿态是不够的,目前也有这一类的研究,关于直接从2d到3d的姿态进行直接估计。这一点是未来发展的趋势。
2016年提出的 CPM 方法具有很强的鲁棒性,之后的很多方法是基于此改进的。CPM 的贡献在于使用顺序化的卷积架构来表达空间信息和纹理信息。网络分为多个阶段,每一个阶段都有监督训练的部分。前面的阶段使用原始图片作为输入,后面阶段使用之前阶段的特征图作为输入,主要是为了融合空间信息,纹理信息和中心约束。另外,对同一个卷积架构同时使用多个尺度处理输入的特征和响应,既能保证精度,又考虑了各部件之间的远近距离关系:
模型的基本框架如上图,此项目使用的神经网络为7个stage的CPMs 结构。第一个stage的输入为原始图片,经过五个卷积层然后接上两个卷积核大小为11的卷积层,这两个11的卷积层效果类似于全连接层。Stage1的推测信息是局部的因为感受野比较小。第二个stage的输入也是原始图片,但是在卷积层的中段,加入了一个串联结构,来融合三部分的信息,包括stage1的响应图,stage2的阶段性卷积结果和高斯模板的中心约束。Stage3不再使用原始图像作为输入,而是从第二阶段的中途取出一个特征图作为输入,同样使用stage2的三种信息进行融合。后面的stage与stage3相同,并且一共有7个stage。
Openpose-realtime 2D human pose estimation(自下而上)
本文提出了一种有效的多人姿态估计办法open pose。提出了第一个自下而上的关联分数表示,通过(PAFs)、一组二维向量场,编码四肢在图像域上的位置和方向,这种方法准确率高、计算量小。open pose准确率高、实时性好,运行效果不受图像中人的个数的影响。
highlights:
①证明只有PAFs的优化有助于系统的性能和准确性。(之前的工作认为PAFs和body part location estimation共同作用才能促进系统优化)
②提出第一个组合body 和foot的detector(基于一个内部注释的脚部数据集,已开源)
③本文提出的组合检测器不仅减少了推理时间而且保持了每个部件的准确性
④发布了openpose这一开源系统
Human pose estimation存在的挑战;
first:用于检测的图片中的人的数量是未知的且无规律的
second:人与人之间的相互作用和重叠造成关节之间的关联困难
third:在实时运行时,我画面中的人的数量会变化。这就造成了实时性的困难。
自上而下方法的缺点:
常见的方法是执行 person detector,再对检测到的人进行单人姿态估计。这种自上而下的方法虽然很好理解但是却受检测效果的影响。如果画面内的人体出现遮挡、重合等无法检测的情况,则不会向下执行(缺点1)。此外运行时间与图像中的人数成正比(缺点2)。
自下而上方法的发展历程:
以为自上而下的方法有以上缺点,所以自下而上的方法就变的很有吸引力。
最初的自底向上方法效率不高,因为最终解析需要昂贵的全局推断,每个图像的处理需要几分钟的时间。
(一)Single Person Pose Estimation
传统的关节式人体姿态估计方法是通过对人体各部位的局部观测以及它们之间的空间相关性进行推断。关节姿势的空间模型要么基于树结构的图形模型,这些模型参数化地编码了运动链上相邻部件之间的空间关系,要么基于非树模型它通过附加的边来增强树结构,以捕捉遮挡、对称性和远程关系。(这里不懂(((φ(◎ロ◎;)φ))))
为了获得可靠的body parts局部观测值,卷积神经网络(CNNs)得到了广泛的应用,并显著提高了body pose estimation 的精度。
(二)Multi-Person Pose Estimation
对于多人姿态估计,大多数方法都采用了自上而下的策略。首先检测到人,然后在每个检测区域独立估计每个人的姿势。虽然这种自上而下的方法简单,但过分依赖于前期的检测结果,而且对于人与人之间的遮挡和依赖无法做出很好的判断。
正是以为自上而下的方法有这些缺点,一些方法开始考虑如何人与人之间的依赖性问题。有研究扩展了图像结构,将一组相互作用的人和深度排序考虑在内,但仍然需要一个人检测器来初始化检测假设。提出了一种自底向上的方法,联合标记零件检测候选零件,并将它们与个人关联,从检测零件的空间偏移量中回归成对得分。该方法不依赖于人的检测,但是在全连通图上求解整数线性规划是一个NP难问题,因此单个图像的平均处理时间约为小时。
在早期的研究[3]中,我们提出了部分相似域(PAF),它是由一组流场组成的表示,它对不同数量的人体各部分之间的非结构化成对关系进行编码。可以在不需要额外的训练步骤的情况下有效地从PAFs中获得成对的数值。这些数值足以让贪婪的解析获得高质量的结果,并具有实时性,以便进行多人估计。
论文行文结构:
3.1和3.2:证明了PAF精化对于最大化精度是至关重要的,而身体部位预测精化则不是那么重要。增加了网络深度,但删除了身体部位的细化阶段。
4.2:提出了一个注释脚部数据集,其中包含已公开发布的15K人脚实例。
5.2和5.3:这种改进的网络使速度和精度分别提高了约200%和7%。
5.3:与Mask R-CNN和Alpha Pose的运行进行比较,显示了该自下而上方法的计算优势。
5.5:明可以训练具有身体和脚关键点的组合模型,在保持其准确性的同时保持仅身体模型的速度。
5.6:通过将其应用于车辆关键点估计任务,证明了该方法的通用性。
论文内容:

算法输入:w*h的color image
算法输出:color image每个人的解剖关键点的二维位置
首先,前馈网络预测body parts locations 的一组2D置信图S(图2b)和一组2D vector fieldL(PAFs),这个PAFs编码了body parts之间的关联度(图2c)。通过贪婪推理(图2d)解析置信图和PAFs,输出图像中所有人的2d关键点。

以上是论文的网络框架。
3.1 网络结构
网络的结构其实是很简单的,分为两大块。第一块蓝色部分用于产生输入图片的PAFs,(叫做Lt).图片特征F加上这个Lt成为了第二部分的输入,第二部分橙色部分输出置信图S。其中粉色部分为3层3*3卷积块,每个3×3的卷积之间串联,如虚线框里所示。
3.2 同时检测和关联之PAF和置信图
论文网络的输入是图片特征映射F,这个F由CNN分析原始图像(由VGG-19的前10层初始化并进行微调),生成一组输入到第一级的特征映射。在这个阶段,网络生成一组部件关联字段(PAF)。
![]()
在上一节我们说过,L是什么,这里的L1是CNN在stage1阶段预测出的关联字段PAF(因为网络是不断迭代的,所以会有好多个stage,论文上说有T个)。在随后的每个 stage 中,将前一阶段的预测与原始图像特征F相连接并用于生成精确的预测。公式如下:
![]()
在该部分,PAFs的最大阶数为Tp。
在TP迭代之后,从最新的PAF预测开始,重复置信图检测过程。也就是说,open pose的两大组成是一前一后进行的?
在得出较为准确的PAFs之后才进行置信图的预测。下面开始执行这一部分:

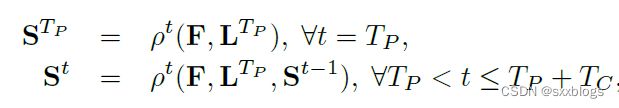
ρt是CNN预测置信图过程,Tc表示置信图迭代最大阶数。
那么为什么open pose要把网络图设置成前后进行的呢?(我的猜测)
论文中提到,之前的工作是在每一stage都把PAFs和置信图进行细化,而在本论文中是先得出较为精确的PAFs再进行置信图的预测(计算量小了一半)。论文作者在第5.2节经验性地观察到,改进的亲和力场的预测(这里的亲和力场是PAFs吧)会直接改善了置信图结果,而反之则不成立。直观地说,如果有精确的PAF通道输出,身体部位的位置就可以猜出来了。然而,如果我们看到一堆没有其他信息的身体部位,我们就不能把它们解析成不同的人。
置信图结果是在最新和最精确的PAF预测的基础上进行预测的
同时检测和关联之损失函数
这时我们再来回顾一下本论文的网络结构,在每一个分支的尾部都加了一个损失函数。使用的损失函数是我们很熟悉的L2损失函数。是的,在两个分支都是使用的L2。

为了引导网络迭代地预测第一个分支中身体部位的PAF和第二个分支中的置信图,在每个阶段的末尾应用了一个损失函数。
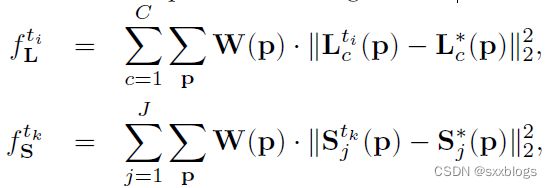
其中![]() 是PAF的groundtruth,
是PAF的groundtruth,![]() 是置信图夫人ground truth。当像素P缺少注释时,W是一个二进制掩码,W(p)=0。
是置信图夫人ground truth。当像素P缺少注释时,W是一个二进制掩码,W(p)=0。
mask是用来避免在训练中惩罚真正的积极预测。每个阶段的中间监督通过定期补充梯度来解决梯度消失问题。
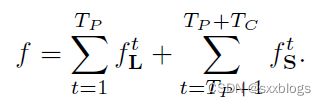
3.3 Part Detection的置信图
为了在训练期间评估上面公式中的fS,我们从带注释的2D关键点生成基础真相置信图S*。每个置信图都是一个二维表示,即某个特定的身体部位可以定位在任何给定的像素中。理想情况下,如果一个人出现在图像中,如果对应的部分可见,则每个置信图中应该存在一个峰值;如果图像中有多个人,则每个人k对应每个可见部分j对应一个峰值。Sj,k为每个人k生成的个体置信图。Xj,k是图像中人物k的身体j 部分的真实位置。![]() 控制了峰值的传播。
控制了峰值的传播。

网络预测的地面真实度置信图是个体置信度图通过max算子的集合
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CtYzZx3z-1653460556255)(C:\Users\sxj96\AppData\Roaming\Typora\typora-user-images\1599640294230.png)]](http://img.e-com-net.com/image/info8/74f42d5268754696aad5715f16e89669.jpg)
取置信图的最大值,而不是平均值,这样附近峰值的精度仍然是不同的,如右图所示。在测试时,我们预测置信图,并通过执行非最大值抑制来获得候选身体部位。
3.4 部件关联PAFs
这部分我认为是本篇论文最值得好好研读的地方,毕竟自下而上的方法最核心便是人体物理的设计。
这一part来看看PAF是怎么计算的。

给定一组检测到的身体部位(如图5a中的红蓝点所示),我们如何将它们组合起来,形成未知数量的人的全身姿势?我们需要对每对身体部位检测的关联度进行置信度度量,即给一个公式用来衡量它们是否属于同一个人。测量关联的一种可能方法是检测肢体上每对零件之间的附加中点,并检查候选零件检测之间的关联度,如图5b所示,当人们聚集在一起,因为他们倾向于这样做,这些中点很可能支持错误的联想(如图5b中的绿线所示)。这种错误的关联产生于两个方面的限制:(1)它只编码每个肢体的位置,而不是方向;(2)它将肢体的支撑区域缩小到一个点。
以上的方法有问题?没有关系!本文的PAFs解决了以上限制。它们保存了四肢支撑区域的位置和方向信息(如图5c所示)。 每个PAF是每个肢体的2D向量场,如图1d所示。对于属于特定肢体的区域中的每个像素,2D向量编码从肢体的一部分指向另一部分的方向。每种类型的肢体都有一个相应的PAF连接其两个相关的身体部分。

如下图所示的图片,![]() 是手臂关节位置的真实位置。j1和j2是人题k的手臂关节部位。如果点p位于手臂上,
是手臂关节位置的真实位置。j1和j2是人题k的手臂关节部位。如果点p位于手臂上,![]() 是从j1指向j2的单位向量。对于其他的点向量值为零。
是从j1指向j2的单位向量。对于其他的点向量值为零。

Single Person Pose Estimation参考文献
[7] P. F. Felzenszwalb and D. P. Huttenlocher, “Pictorial structures for object recognition,” in IJCV, 2005.
[8] D. Ramanan, D. A. Forsyth, and A. Zisserman, “Strike a Pose: Tracking people by finding stylized poses,” in CVPR, 2005.
[9] M. Andriluka, S. Roth, and B. Schiele, “Monocular 3D pose estimation and tracking by detection,” in CVPR, 2010.
[10] ——, “Pictorial structures revisited: People detection and articulated pose estimation,” in CVPR, 2009.
[11] L. Pishchulin, M. Andriluka, P. Gehler, and B. Schiele, “Poselet conditioned pictorial structures,” in CVPR, 2013.
[12] Y. Yang and D. Ramanan, “Articulated human detection with flexible mixtures of parts,” in TPAMI, 2013.
[13] S. Johnson and M. Everingham, “Clustered pose and nonlinear appearance models for human pose estimation,” in BMVC, 2010.
[14] Y. Wang and G. Mori, “Multiple tree models for occlusion and spatial constraints in human pose estimation,” in ECCV, 2008.
[15] L. Sigal and M. J. Black, “Measure locally, reason globally: Occlusion-sensitive articulated pose estimation,” in CVPR, 2006.
[16] X. Lan and D. P. Huttenlocher, “Beyond trees: Common-factor models for 2d human pose recovery,” in ICCV, 2005.
[17] L. Karlinsky and S. Ullman, “Using linking features in learning non-parametric part models,” in ECCV, 2012.
[18] M. Dantone, J. Gall, C. Leistner, and L. Van Gool, “Human pose estimation using body parts dependent joint regressors,” in CVPR,2013.
[19] A. Newell, K. Yang, and J. Deng, “Stacked hourglass networks for human pose estimation,” in ECCV, 2016.
[20] S.-E. Wei, V. Ramakrishna, T. Kanade, and Y. Sheikh, “Convolutional pose machines,” in CVPR, 2016.
[21] W. Ouyang, X. Chu, and X. Wang, “Multi-source deep learning for human pose estimation,” in CVPR, 2014.
[22] J. Tompson, R. Goroshin, A. Jain, Y. LeCun, and C. Bregler, “Efficient object localization using convolutional networks,” in CVPR, 2015.
[23] J. J. Tompson, A. Jain, Y. LeCun, and C. Bregler, “Joint training of a convolutional network and a graphical model for human pose estimation,” in NIPS, 2014.
[24] X. Chen and A. Yuille, “Articulated pose estimation by a graphical model with image dependent pairwise relations,” in NIPS, 2014.
[25] A. Toshev and C. Szegedy, “Deeppose: Human pose estimation via deep neural networks,” in CVPR, 2014.
[26] V. Belagiannis and A. Zisserman, “Recurrent human pose estimation,” in IEEE FG, 2017.
[27] A. Bulat and G. Tzimiropoulos, “Human pose estimation via convolutional part heatmap regression,” in ECCV, 2016.
[28] X. Chu, W. Yang, W. Ouyang, C. Ma, A. L. Yuille, and X. Wang, “Multi-context attention for human pose estimation,” in CVPR, 2017.
[29] W. Yang, S. Li, W. Ouyang, H. Li, and X. Wang, “Learning feature pyramids for human pose estimation,” in ICCV, 2017.
[30] Y. Chen, C. Shen, X.-S. Wei, L. Liu, and J. Yang, “Adversarial posenet: A structure-aware convolutional network for human pose
estimation,” in ICCV, 2017.
[31] W. Tang, P. Yu, and Y. Wu, “Deeply learned compositional models for human pose estimation,” in ECCV, 2018.
[32] L. Ke, M.-C. Chang, H. Qi, and S. Lyu, “Multi-scale structureaware network for human pose estimation,” in ECCV, 2018.
[33] T. Pfister, J. Charles, and A. Zisserman, “Flowing convnets for human pose estimation in videos,” in ICCV, 2015.
[34] V. Ramakrishna, D. Munoz, M. Hebert, J. A. Bagnell, and Y. Sheikh, “Pose machines: Articulated pose estimation via inference machines,” in ECCV, 2014.
[35] S. Hochreiter, Y. Bengio, and P. Frasconi, “Gradient flow in recurrent nets: the difficulty of learning long-term dependencies,” in Field Guide to Dynamical Recurrent Networks, J. Kolen and S. Kremer, Eds. IEEE Press, 2001.
[36] X. Glorot and Y. Bengio, “Understanding the difficulty of training deep feedforward neural networks,” in AISTATS, 2010.
Multi-Person Pose Estimation参考文献
L. Pishchulin, A. Jain, M. Andriluka, T. Thorm¨ahlen, and B. Schiele, “Articulated people detection and pose estimation: Reshaping the future,” in CVPR, 2012.
[39] G. Gkioxari, B. Hariharan, R. Girshick, and J. Malik, “Using kposelets for detecting people and localizing their keypoints,” in CVPR, 2014.
[40] M. Sun and S. Savarese, “Articulated part-based model for joint object detection and pose estimation,” in ICCV, 2011.
[41] U. Iqbal and J. Gall, “Multi-person pose estimation with local jointto- person associations,” in ECCV Workshop, 2016.
[42] G. Papandreou, T. Zhu, N. Kanazawa, A. Toshev, J. Tompson, C. Bregler, and K. Murphy, “Towards accurate multi-person pose estimation in the wild,” in CVPR, 2017.
[43] Y. Chen, Z. Wang, Y. Peng, Z. Zhang, G. Yu, and J. Sun, “Cascaded pyramid network for multi person pose estimation,” in CVPR, 2018.
[44] B. Xiao, H. Wu, and Y. Wei, “Simple baselines for human pose estimation and tracking,” in ECCV, 2018.
[45] M. Eichner and V. Ferrari, “We are family: Joint pose estimation of multiple persons,” in ECCV, 2010.
[46] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in CVPR,2016.
[47] E. Insafutdinov, M. Andriluka, L. Pishchulin, S. Tang, E. Levinkov, B. Andres, and B. Schiele, “Arttrack: Articulated multi-person tracking in the wild,” in CVPR, 2017.
[48] A. Newell, Z. Huang, and J. Deng, “Associative embedding: Endto-end learning for joint detection and grouping,” in NIPS, 2017.
[49] G. Papandreou, T. Zhu, L.-C. Chen, S. Gidaris, J. Tompson, andK. Murphy, “Personlab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding
model,” in ECCV, 2018
[50] M. Kocabas, S. Karagoz, and E. Akbas, “MultiPoseNet: Fast multiperson pose estimation using pose residual network,” in ECCV, 2018.
[51] X. Nie, J. Feng, J. Xing, and S. Yan, “Pose partition networks for multi-person pose estimation,” in ECCV, 2018…