AI初学笔记10 卷积神经网络
AI初学笔记10 卷积神经网络
文章目录
- AI初学笔记10 卷积神经网络
- 一、CNN原理说明
- 二、CNN网络结构及参数
- 三、程序实现
-
- 1. 加载数据
- 2. 定义类
- 3. 优化器及训练过程
- 总结
一、CNN原理说明
在处理图像问题中,图像的每一个像素值都与周边的像素值存在一定的联系,而使用全连接网络的话,则会损失掉这种空间特征,导致最终准确率下降。
为了提取出这种图像问题中的空间特征,采用如下图所示的卷积神经网络。下图中的输入input中每个数值表示黑白照片中该像素点的亮度值,下图的卷积核Kernel中有9个权重,卷积核在输入中进行累加,最终得到的加和211放到输出的首位,然后将卷积核在输入图中进行平移,再得到第二个输出值,依此类推,最终可以获得3*3的输出。
输出图长宽的计算方法为:K-N+1,其中K为输入的长宽,N为卷积和的长宽,如下图的计算为:5 - 3 + 1 = 3
彩色图片情况略有不同,会有RGB三个通道。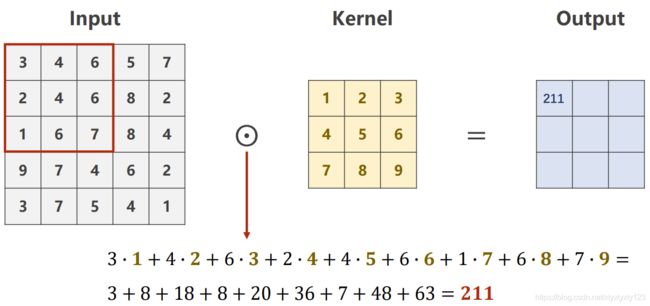
二、CNN网络结构及参数
经过第一个卷积层后,通道数由1变化为10,这是因为有10个卷积核,每个卷积核进行一轮特征提取就形成10个通道,卷积层的输出通道数由卷积核个数决定。
长宽的变化由公式K-N+1得到,batch大小由人为设定。
池化层不改变通道,只是将4个像素点变成一个,最大池化就是取最大值留下,均值池化就是取4个像素点的均值留下。池化的目的是减少降维参数。
网络最后要加入全连接层,由于最终目的是进行分类,所以要分成多少类,最后的输出参数就是多少。
全连接层的输入参数有多少个需要计算一下,就是上一层卷积神经网络输出的参数数量,简单的办法可以使用print打印卷积层的shape,就可以得到输出参数数量了。
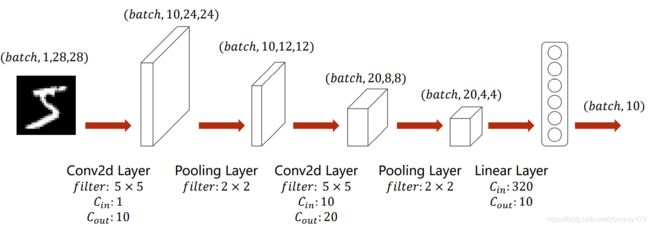
三、程序实现
1. 加载数据
与上节相同,不做说明。
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import numpy as np
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307, ), (0.3081, ))])
train_dataset = datasets.MNIST(root='D:\DEEPLEARING\data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='D:\DEEPLEARING\data', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
2. 定义类
使用函数就可以直接调用卷积层,如torch.nn.Conv2d(1, 10, kernel_size=5)中1表示输入通道数,10表示输出通道数,5为卷积核长宽。
这里全连接层输入的参数数量需要计算,当然还有偷懒的办法,就是先注释掉代码中的self.fc = torch.nn.Linear(320, 10)和x = self.fc(x),用print(x.shape)打印x的形状,可以得到torch.Size([64, 20, 4, 4])的结果,表示batch为64,通道20,长宽为4,则需要输入全连接层的参数为2044 = 320。
最后的代码表示把参数转移使用gpu进行运算,提前要安装cuda。
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5)
self.pooling = torch.nn.MaxPool2d(2)
self.fc = torch.nn.Linear(320, 10)
def forward(self, x):
# Flatten data from (n, 1, 28, 28) to (n, 784)
batch_size = x.size(0)
x = F.relu(self.pooling(self.conv1(x)))
x = F.relu(self.pooling(self.conv2(x)))
print(x.shape)
x = x.view(batch_size, -1) # flatten
x = self.fc(x)
return x
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
3. 优化器及训练过程
与上节相同,不做说明。
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
# forward + backward + update
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy on test set: %d %%' % (100 * correct / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
总结
卷积神经网络在视觉领域的应用非常广泛,并且近几年诸如通道注意力等方面的研究可以进一步提升网络能力,有待日后进一步学习。