YoloX 阅读笔记
YoloX 阅读笔记
- 摘要
- Introduction
- YOLOX
-
- 主干网
- FPN
- head
- 更强的数据增强
- loss
摘要
We switch the YOLO detector to an anchor-free manner and conduct other advanced detection techniques, i.e., a decoupled head and the leading label assignment strategy SimOTA to achieve state-of-the-art results across a large scale range of models
从这段话上可以看出来,作者做的两个主要贡献,分别是1)将yolo系列从给予anchor的方法又拉回了anchor free的方法;2)训练的时候采取了一种新的叫做SimOTA的类别分配策略。后面就是作者说yolox比其他算法好多少。
Introduction
They extract the most advanced detection technologies available at the time (e.g., anchors [26] for YOLOv2 [24], Residual Net [9] for YOLOv3 [25]) and optimize the implementation for best practice.
论文引言首先说明了以往的yolo算法引入了当时很先进的策略,比如yolov2引入了anchor机制,yolov3引入了残差网络等等。
Nevertheless, over the past two years, the major advances in object detection academia have focused on anchor-free detectors [29, 40, 14], advanced label assignment strategies [37, 36, 12, 41, 22, 4], and end-to-end (NMS-free) detectors [2, 32, 39]. These have not been integrated into YOLO families yet,
但是近两年,目标检测领域已经将目光转向 anchor-free 的方法,更先进的标签分配策略,NMS-free的方法,但是在yolo系列里,还没有引入这些机制。
That’s what brings us here, delivering those recent advancements to YOLO series with experienced optimization. Considering YOLOv4 and YOLOv5 may be a little over-optimized for the anchor-based pipeline, we choose YOLOv3 [25] as our start point (we set YOLOv3-SPP as the default YOLOv3). Indeed, YOLOv3 is still one of the most widely used detectors in the industry due to the limited computation resources and the insufficient software support in various practical applications.
考虑到yolov3依旧在工业界应用最广泛,并且yolov4和yolov5在anchor-based 的基础上过度优化了,作者仍然把yolov3作为起点。在引言的最后介绍的是yolox的优越性。
YOLOX
这一章介绍的是yolox的改进策略
主干网
Our baseline adopts the architecture of DarkNet53 backbone and an SPP layer, referred to YOLOv3-SPP in some papers
从论文中可以看出,论文仍然采用DarkNet53作为主干网,结合代码,讲一下该部分,首先用了Focus结构,这种结构就是将原始输入通道为3的rgb图像扩展为通道数为12,并且将原来宽高为wh的特征缩小为w/2h/2,输入图像2*2的网格化采样。
然后,将Focus的输出经过5层Conv 和 CSPLayer的组合,CSPLayer又是由Bottleneck组成的残差结构, Bottleneck是由BaseConv组成的小残差结构,BaseConv是由Conv2d、BatchNorm2d、SiLU组成的基本结构。其中最后一层的Conv 和 CSPLayer的组合还包括了SPPBottleneck,SPPBottleneck与Bottleneck的差别在于通道上叠加了不同MaxPool2d的结果。
FPN
采用三个特征层构建,三个特征层的shape分别为feat1=(80,80,256)、feat2=(40,40,512)、feat3=(20,20,1024),首先进行上采样加CSPLayer 与前一层特征叠加。之后依次下采样得到输出的三个特征层。
head
In object detection, the conflict between classification and regression tasks is a well-known problem [27, 34]. Thus the decoupled head for classification and localization is widely used in the most of one-stage and two-stage detectors
作者提到分类和回归两个任务相互干扰是众所周知的,因此在这里把两部分分开。
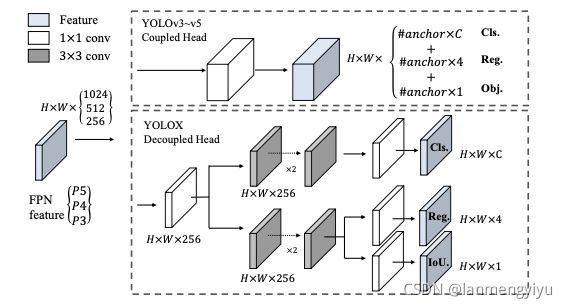
每一个特征层,我们可以获得三个预测结果尺寸分别为:Cls(h,w,num_classes),Reg(h,w,4), Iou(h,w,1)
更强的数据增强
We add Mosaic and MixUp into our augmentation strategies to boost YOLOX’s performance.
数据增强的方法中,作者加入了Mosaic 和 MixUp
Mosaic数据增强方法是YOLOV4论文中提出来的,主要思想是将四张图片进行随机裁剪,再拼接到一张图上作为训练数据。
Mixup:将随机的两张样本按比例混合,分类的结果按比例分配;
loss
在这里作者主要提出了SimOTA方法。直白点说就是不同目标设定不同的正样本数量。
因此,SimOTA的过程总结如下:
1、计算每个真实框和当前特征点预测框的重合程度。
2、计算将重合度最高的十个预测框与真实框的IOU加起来求得每个真实框的k,也就代表每个真实框有k个特征点与之对应。
3、计算每个真实框和当前特征点预测框的种类预测准确度。
4、判断真实框的中心是否落在了特征点的一定半径内。
5、计算Cost代价矩阵。
6、将Cost最低的k个点作为该真实框的正样本。
YoloX的损失由三个部分组成:
1、Reg部分,可知道每个真实框对应的特征点,获取到每个框对应的特征点后,取出该特征点的预测框,利用真实框和预测框计算IOU损失,作为Reg部分的Loss组成。
2、Obj部分,可知道每个真实框对应的特征点,所有真实框对应的特征点都是正样本,剩余的特征点均为负样本,根据正负样本和特征点的是否包含物体的预测结果计算交叉熵损失,作为Obj部分的Loss组成。
3、Cls部分,可知道每个真实框对应的特征点,获取到每个框对应的特征点后,取出该特征点的种类预测结果,根据真实框的种类和特征点的种类预测结果计算交叉熵损失,作为Cls部分的Loss组成。
引用链接: 睿智的目标检测53——Pytorch搭建YoloX目标检测平台.
引用链接: YOLOX: Exceeding YOLO Series in 2021.