pytorch-faster-rcnn 代码实践
转载请注明出处!
目标检测在CV里面占很大一席之地了,而目标检测当红网络肯定少不了RCNN家族。在自己的数据集上使用了Faster RCNN,效果确实不错。
理解Faster RCNN还需要相应地看Fast RCNN和RCNN,因为有的公式在前2篇出现过的会略过,就不太明白。
ok进入正题~
1 Faster RCNN论文详解
Faster RCNN网络就是:
1) 卷积网络去掉全连接层的Feature Map;
2) Feature Map——>RPN生成region proposal;
3) region proposal+Feature Map——>ROI pooling 生成proposal feature maps;
4) proposal feature maps经过全连接层后分类+bounding box regression获得最终的检测框的精确定位以及类别。
这可能会有疑问(1)为什么要生成Feature Map而不是直接输入原始图像?(2) RPN是什么,生成的region proposal和proposal feature maps有什么区别? (3)为什么还要再经过bounding box regression?
问题(1),回想曾经行人检测是hog+SVM,选定一些窗口,通过滑窗来提取区域,并提取区域的HOG特征,输入到SVM判断是否行人.而Faster RCNN就是利用神经网络提特征.
1.1 RPN(region proposal network)
RPN的作用是生成region proposal,受到空间金字塔的启发。再回到行人检测的问题。人因为远近在图像中表现大小不一样,如果用同一个(w,h)的窗口去滑动,结果可能会漏掉小的人。所以,之后人们会用多个(w,h)的窗口去检测,并且选取响应最大的那个(w,h)。多个(w,h)具体多少个?具体w和h是多少?RPN确定了具体多少个,具体w和h是多少。

RPN取代了滑窗的形式(也可以理解为窗口的步长是1个像素吧),借鉴了FCN的思想,变成了pixel-2pixel预测,只不过FCN对于每个像素输出是N个类别的概率值,而RPN输出的就是region proposal。上述说RPN确定了具体多少个窗口和具体w和h是多少。这个窗口呢,他们叫Anchors。文献中这个Anchors的数量k=9,分别是3种尺寸size、w和h比分别为{1:1 1:2 2:1}。顺便说一句,不管你输入的图像大小是多少,最后输入进网络都会reshape为统一尺寸,比如800x600。
所以RPN就相当于,用9个窗口,步长为1个像素地去检测行人。每个像素呢,会有9个判断(同时进行,所以很节约时间),以它为中心的9个anchors最有可能存在的位置(每个点初始化的9个anchors是一样的,经过学习,每个点的9个anchors位置都会改变)。
RPN它不仅输出了region proposal,还要分个类,不过是二分类,背景还是目标。也就是它额外加了个预测的分支。
比如使用VGG网络后最后一层卷积层的输出是256个224x224的feature maps,输入RPN后变成了 6*k个224x224的通道。(region proposal是4k,分类是2k,因为anchors需要4个变量表示,左上角x、y和w,h,分类需要2个输出,分别是是背景的概率和是目标的概率)
再看看reg和cls不要想复杂了,这两个是并行的,reg使用的是bounding box回归,cls就是二分类!结合图和代码,可以看一下reg和cls具体如何操作的。

feature_maps --> 3x3 卷积+relu 后,
输入到cls:
-->1x1卷积+relu-->reshape -->softmax-->reshpe-->output (label prediction)
第一个reshape :[batch,channels,w,h]-->[batch,2,w*channels/2,h]。这里channels等于2(bg/fg) * 9 (anchors)
第二个reshape:[batch,channels,w,h]-->[batch,18,w*channels/18,h]。
为什么要reshape:要预测的话,输入channels表示你要预测的类别有channels个,比如二分类,输入到softmax里面必须channels等于2。所以要把channels = 2*9变成 2.
再看看bounding box reg,feature_maps --> 3x3 卷积后,
输入到reg:
-->1x1卷积+relu-->bounding box reg->output (region proposals)
1.2 bounding box regression
写在前面:BB回归是特征图的函数,而不是位置的函数!即通过前面的卷积提取特征,将这些特征与偏移量(表示anchor到GT的所要经历的表示平移+缩放的4个参数)的映射关系就是BB回归要学习的东西。
这个问题在RCNN文章中详细介绍了。比如图中,绿色的框框是groundtruth,而红色的框框为rpn中某个anchor。如何让anchor逼近groundtruth呢?
平移+缩放!

假设红色的框框是A,用左上角坐标和长、宽描述,则A={Ax, Ay, Aw, Ah},绿色的groundtruth是G,G={Gx, Gy, Gw, Gh}。要找到一种映射F,是的F(A)=G',而G'尽量等于G。
1 平移:
G'x = Ax + △x G'y = Ay + △y
2 缩放
G'w = Aw *△w G'h = G'h*△h
△x、△y、△w 和△h可以用A的函数来表示(因为要学习这四个变量,所以必须要写成A的函数形式)
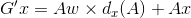
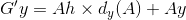
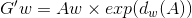
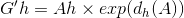
要学习的就是 这四个变换dx,dy,dw和dh。
为什么有个exp,这是为了让缩放因子大于0。
由于输入RPN的是feature map,在feature map每个像素都有k个anchor,这k个anchor会有相应的4对变换d(dx,dy,dw和dh),每个anchor 都有相应的偏移量作为标准:
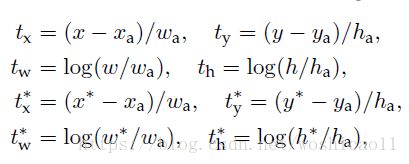
x,y,w,h是预测的框框,xa,ya,wa,ha是第i个像素的某个anchor,x*,y*,w*和h*是groundtruth的框框。t实际中就是d,而偏移量d是feature map的特征向量的函数:
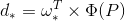
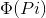 是feature maps第i个像素的第k个anchor,则:k_ancho_w*k_ancho_h*channels的值。如下图:
是feature maps第i个像素的第k个anchor,则:k_ancho_w*k_ancho_h*channels的值。如下图:
纠正:在RPN阶段,
(解释一下为什么是特征向量而不是坐标,因为特征向量是高级的语义信息,它可能包含坐标,也可能包含像素值和梯度等等,这都是需要学习后才能确定的,如果直接是坐标,这就属于低级的信息了,那也就不需要用VGG网络提取特征,直接输入原始图像就好了)
最终损失函数表示形式是:
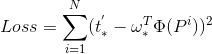
feature maps经过3x3卷积后,分别输入到cls和reg中,得到的rpn_cls_prob和rpn_bbox_pred,将这二者还有im_info输入到RPN_proposal。(im_info解释:https://blog.csdn.net/hejin_some/article/details/80743635)
1.3 RPN_proposal
#为每个位置i产生一个以i为中心的anchor A
#在像素 i 中 预测的bbox偏移量 应用在每个anchor中
#剪辑 预测框 到图像
#删除高度或宽度 小于 阈值的预测框
#根据score对所有的(proposal,score)进行排序
#在NMS之前 提取前 top pre_nms_topN的proposals (NMS:nonmaximum suppression)
#对其余提案应用阈值为0.7的NMS
#NMS之后,采取 after_nms_topN 个 proposals
#返回最靠前的proposals( - > RoIs top,得分排名靠前)
通过RPN_proposal后,还需要使用Fast RCNN。
1.4 Fast RCNN: ROI pooling+分类回归
Fast RCNN:ROI pooling+(分类/回归)。
为什么需要ROI pooling?我们知道,分类在全连接层后接一个softmax,但是是需要大小一样的。前面的rpn阶段输入的是整张feature map,而这里输入的是目标ROI的feature maps,如:
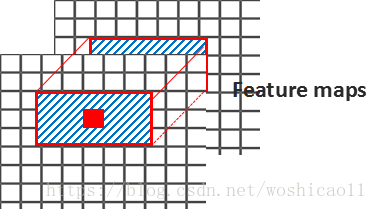
ROI 和anchor的区别,anchor是统一的一定size和ratio的矩形,ROI是anchor学习的偏移量所得。这一过程是:
anchor学习了4个偏移量,anchor根据4个偏移量得到的是原始的图像对应的位置,称为bounding box(如512x512resize到600x600,则对应的是这个600x600的),bounding box经过缩小变为feature maps上的ROI。
但RPN后,根据偏移量,会把这些anchors按偏移量缩放,这就不能保证每个ROI都一样了。所以ROI pooling的作用有2个:
第一就是提取ROI的特征;
第二个就是,将每个不同大小的ROI映射出相同大小size_fix的H和W, 如(7*7*channels)。方便接下来的cls 和reg。
1.5 Sharing Features for RPN and Fast R-CNN
原文中是说,RPN和Fast R-CNN独立训练的话那二者将会以不同的方式调节参数,所以需要将RPN和fast R-CNN联合起来,共同学习。
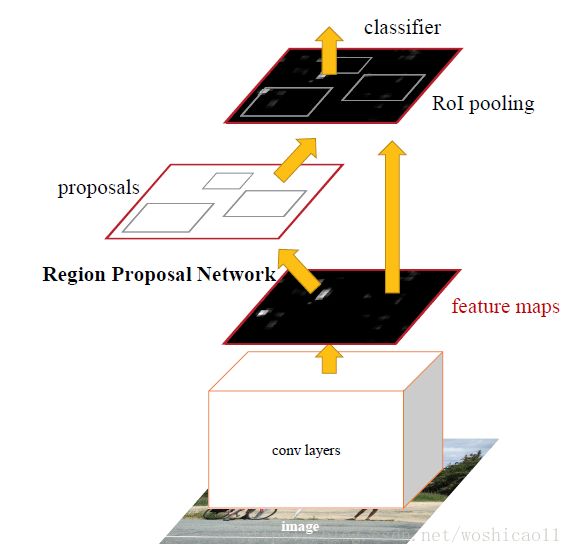
他采取的方案是交替训练——4-Step Alternating Training:
第一步:用pre-trained 的用来提取特征的model(如VGG等)初始化RPN网络,然后训练RPN,在训练后,model以及RPN会被更新。
第二步:用pre-trained 的model(和第一步一样)初始化Fast-rcnn。然后使用训练过的RPN来计算proposal,再将proposal给予Fast-rcnn网络,接着训练Fast-rcnn。训练完以后,model以及Fast-rcnn会被更新(RPN没有参与训练所以不变)。
这有个疑问,我没想明白,我觉得这个时候,Fast-rcnn和RPN是共享了的,因为RPN的结果用来训练了Fast rcnn,但是文中说At this point the two networks do not share convolutional layers.可是这一步明明是:we train a separate detection network by Fast R-CNN using the proposals generated by the step-1 RPN.
这个博主给了我解答https://blog.csdn.net/weixin_40449426/article/details/78141635 我混淆了 共享卷积的概念:model始终保持和上一步Fast-rcnn中model一致,所以就称之为着共享。
分享是美德,对我有启发的尽量po上,感谢博主的分享~~~~
第三步:使用第二步训练完成的model来初始化RPN网络,第二次训练RPN网络。但是这次要把model锁定,训练过程中,model始终保持不变,而RPN的会被改变。
第四步:仍然保持第三步的model不变,初始化Fast-rcnn,第二次训练Fast-rcnn网络。其实就是对其unique进行finetune,训练完毕,得到一个文中所说的unified network。
我觉得Faster RCNN就介绍到这,可能还需要补一些Fast rcnn,因为有个roi pooling,后续加上把~~
后面到重头戏了,用自己的数据训练网络,我使用的是pytorch,配置有点繁琐,所以第二步说一下如何配置以及最可能遇到的坑!
2 Pytorch 搭建 Faster RCNN系列——Linux环境
环境介绍:
Pytorch
GPU: l英伟达 1070 8G
CUDA:9.0(8.0也可以)
传输门: https://github.com/jwyang/faster-rcnn.pytorch/
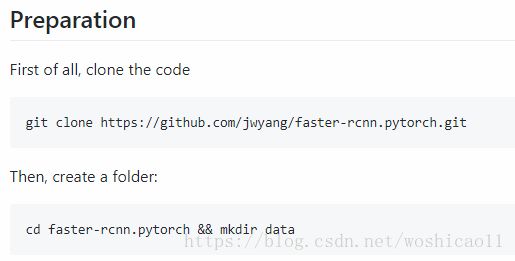
改一下这个,比如我的是1070系列,则改成 sm_61

我觉得这个时候很多人都会遇到问题,我花了半天解决~~避免大家入坑,
RuntimeError: cuda runtime error (8) : invalid device function at /pytorch/torch/lib/THC/THCTensorCopy.cu:204
问题解决方案:
https://github.com/jwyang/faster-rcnn.pytorch/issues/110
然后就是运行例题了~~嗯,这个就略过了,bug这些东西真的看人品~~
下面进入我们的训练自己的数据的环节了.
3 Faster RCNN训练自己的数据集
3.1 准备自己的数据集
介绍一下为自己的数据,为的数据已经分割了.比如一幅图像中有3个杯子,则处理原始图像,还有3张每个杯子的分割图.
第一步是制作成txt:
xxxxx1.jpg xmin1 ymin1 xmax1 ymax1
xxxxx1.jpg xmin2 ymin2 xmax2 ymax2
第二步是将txt变成xml.
尊重他人劳动成果,传输门:
https://github.com/ChaoPei/create-pascal-voc-dataset
3.2 训练自己的网络
首先可以下载别人训练好的模型,我下载的是VGG提特征的那个.resnet效果会好一点.
上述链接有训练好的模型:https://github.com/jwyang/faster-rcnn.pytorch
Pretrained Model
We used two pretrained models in our experiments, VGG and ResNet101. You can download these two models from:
-
VGG16: Dropbox, VT Server
-
ResNet101: Dropbox, VT Server
点击VT Server.
介绍一下如何改参数把,以及调整网络:
-
def parse_args():
-
"""
-
Parse input arguments
-
"""
-
parser = argparse.ArgumentParser(description=
'Train a Fast R-CNN network')
-
parser.add_argument(
'--dataset', dest=
'dataset',
-
help=
'training dataset',
-
default=
'pascal_voc', type=str) #可不改动
-
parser.add_argument(
'--net', dest=
'net',
-
help=
'vgg16, res101', #我使用的是VGG,所以把default改了
-
default=
'vgg16', type=str)
-
parser.add_argument(
'--start_epoch', dest=
'start_epoch',
-
help=
'starting epoch',
-
default=
1, type=int) #训练的时候epoch从哪开始
-
parser.add_argument(
'--epochs', dest=
'max_epochs',
-
help=
'number of epochs to train',
-
default=
100, type=int) #迭代多少次
-
parser.add_argument(
'--disp_interval', dest=
'disp_interval',
-
help=
'number of iterations to display',
-
default=
10, type=int) #在一个迭代中,间隔多少个batch显示
-
parser.add_argument(
'--checkpoint_interval', dest=
'checkpoint_interval',
-
help=
'number of iterations to display',
-
default=
20, type=int) #每多少个迭代显示
-
-
parser.add_argument(
'--save_dir', dest=
'save_dir',
-
help=
'directory to save models', default=
"/home/faster-rcnn.pytorch/models",
-
type=str)
-
parser.add_argument(
'--nw', dest=
'num_workers',
-
help=
'number of worker to load data',
-
default=
0, type=int) #加载数据要多少个worker
-
parser.add_argument(
'--cuda', dest=
'cuda',
-
help=
'whether use CUDA',default=
True,
-
action=
'store_true') #是否使用cuda
-
parser.add_argument(
'--ls', dest=
'large_scale',
-
help=
'whether use large imag scale',
-
action=
'store_true') #学习率
-
parser.add_argument(
'--mGPUs', dest=
'mGPUs',
-
help=
'whether use multiple GPUs',
-
action=
'store_true') #是否使用cuda
-
parser.add_argument(
'--bs', dest=
'batch_size',
-
help=
'batch_size',
-
default=
4, type=int)
-
parser.add_argument(
'--cag', dest=
'class_agnostic',
-
help=
'whether perform class_agnostic bbox regression',
-
action=
'store_true') #是否执行类无关的bbox回归
-
-
# config optimization
-
parser.add_argument(
'--o', dest=
'optimizer',
-
help=
'training optimizer',
-
default=
"sgd", type=str)
#优化算法
-
parser.add_argument(
'--lr', dest=
'lr',
-
help=
'starting learning rate',
-
default=
0.001, type=float) #初始学习率
-
parser.add_argument(
'--lr_decay_step', dest=
'lr_decay_step',
-
help=
'step to do learning rate decay, unit is epoch',
-
default=
5, type=int)
-
parser.add_argument(
'--lr_decay_gamma', dest=
'lr_decay_gamma',
-
help=
'learning rate decay ratio',
-
default=
0.1, type=float) #学习率下降率
-
-
# set training session
-
parser.add_argument(
'--s', dest=
'session',
-
help=
'training session',
-
default=
1, type=int) #训练会话,针对多gpu
-
-
# resume trained model #使用训练好的模型
-
parser.add_argument(
'--r', dest=
'resume',
-
help=
'resume checkpoint or not',
-
default=
False, type=bool)
-
parser.add_argument(
'--checksession', dest=
'checksession',
-
help=
'checksession to load model',
-
default=
1, type=int)
-
parser.add_argument(
'--checkepoch', dest=
'checkepoch',
-
help=
'checkepoch to load model',
-
default=
1, type=int)
-
parser.add_argument(
'--checkpoint', dest=
'checkpoint',
-
help=
'checkpoint to load model',
-
default=
0, type=int)
-
# log and diaplay
-
parser.add_argument(
'--use_tfboard', dest=
'use_tfboard',
-
help=
'whether use tensorflow tensorboard',
-
default=
False, type=bool)
-
-
args = parser.parse_args()
-
return args
题外话:介绍一下argparse:arguments parser参数解析器.有时需要在终端执行python文件的时候,我们需要传入参数,所以会有个argparse来传参数.
但如果本地可以直接执行,会定义个:
-
if __name__ ==
'__main__':
-
args = parse_args()
这个时候,应该如何修改或赋值上面定义的参数呢?
-
if __name__ ==
'__main__':
-
args = parse_args()
-
args.class_agnostic =
True
这个时候直接训练就可以了.训练的适合有可能出现loss会出现NaN还是-1来着,这是因为,在制作xmin ymin xmax和ymax有的是-1.python 默认是0开始,而有的坐标从1开始,具体自己谷歌吧吼吼

3.3 测试和计算mAP
我运行的是demo.py并且稍微改了一下使得能够测mAP,test_net.py有比较多的bug,这个一调试电脑就死机.放在我的
github帐号上把,需要的自取.
https://github.com/ShourenWang/Faster-RCNN-pytorch
恩,如有疑惑之处,欢迎留言~