损失函数
损失函数(loss function)是用来估量你模型的预测值f(x)与真实值Y的不一致程度,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。损失函数是经验风险函数的核心部分,也是结构风险函数重要组成部分。模型的结构风险函数包括了经验风险项和正则项,通常可以表示成如下式子:

其中,前面的均值函数表示的是经验风险函数,L代表的是损失函数,后面的Φ是正则化项(regularizer)或者叫惩罚项(penalty term),它可以是L1,也可以是L2,或者其他的正则函数。整个式子表示的意思是找到使目标函数最小时的θ值。下面主要列出几种常见的损失函数。
首先区别一下目标函数、损失函数、代价函数:
Loss Function 是定义在单个样本上的,算的是一个样本的误差。
Cost Function 是定义在整个训练集上的,是所有样本误差的平均,也就是损失函数的平均。
Object Function(目标函数 )定义为:Cost Function + 正则化项。
在有些情况不严格区分这三者。
一.平方损失函数(最小二乘法, Ordinary Least Squares )
最小二乘法是线性回归的一种,最小二乘法(OLS)将问题转化成了一个凸优化问题。在线性回归中,它假设样本和噪声都服从高斯分布(为什么假设成高斯分布呢?其实这里隐藏了一个小知识点,就是中心极限定理),最后通过极大似然估计(MLE)可以推导出最小二乘式子。最小二乘的基本原则是:最优拟合直线应该是使各点到回归直线的距离和最小的直线,即平方和最小。换言之,OLS是基于距离的,而这个距离就是我们用的最多的欧几里得距离。为什么它会选择使用欧式距离作为误差度量呢(即Mean squared error, MSE),主要有以下几个原因:
- 简单,计算方便;
- 欧氏距离是一种很好的相似性度量标准;
- 在不同的表示域变换后特征性质不变。
平方损失(Square loss)的标准形式如下:
![]()
当样本个数为n时,此时的损失函数变为:

Y-f(X)表示的是残差,整个式子表示的是残差的平方和,而我们的目的就是最小化这个目标函数值(注:该式子未加入正则项),也就是最小化残差的平方和(residual sum of squares,RSS)。
而在实际应用中,通常会使用均方差(MSE)作为一项衡量指标,公式如下:

上面提到了线性回归,这里额外补充一句,我们通常说的线性有两种情况,一种是因变量y是自变量x的线性函数,一种是因变量y是参数α的线性函数。在机器学习中,通常指的都是后一种情况。
具体到深度学习领域,MSE 的缺陷在于,当它和 Sigmoid 激活函数一起出现时,可能会出现学习速度缓慢(收敛变慢)的情况。与之类似的其它损失函数还有均方对数误差(Mean Squared Logarithmic Error)、L_2 损失函数、L_1 损失函数、平均绝对误差(Mean Absolute Error)、平均绝对百分比误差(Mean Absolute Percentage Error)等。
拓展:
以上平方损失也叫L2损失,下面比较一下L1损失,L2损失和smooth L1损失。

对于大多数CNN网络,我们一般是使用L2-loss而不是L1-loss,因为L2-loss的收敛速度要比L1-loss要快得多。
对于边框预测回归问题,通常也可以选择平方损失函数(L2损失),但L2范数的缺点是当存在离群点(outliers)的时候,这些点会占loss的主要组成部分。比如说真实值为1,预测10次,有一次预测值为1000,其余次的预测值为1左右,显然loss值主要由1000主宰。所以FastRCNN采用稍微缓和一点绝对损失函数(smooth L1损失),它是随着误差线性增长,而不是平方增长。
注意:smooth L1和L1-loss函数的区别在于,L1-loss在0点处导数不唯一,可能影响收敛。smooth L1的解决办法是在0点附近使用平方函数使得它更加平滑。
根据fast rcnn的说法,"...... L1 loss that is less sensitive to outliers than the L2 loss used in R-CNN and SPPnet." 也就是smooth L1 loss让loss对于离群点更加鲁棒,即:相比于L2损失函数,其对离群点、异常值(outlier)不敏感,梯度变化相对更小,训练时不容易跑飞。
损失函数对x的导数分别为:
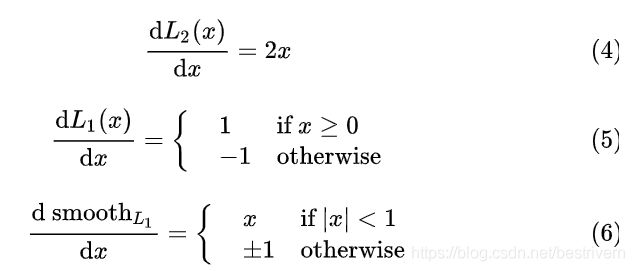
所以faster rcnn和ssd用smooth L1 loss,可以从两方面限制梯度:
- 当预测框与 ground truth 差别过大时,梯度值不至于过大;
- 当预测框与 ground truth 差别很小时,梯度值足够小。
观察 (4),当x增大时L2损失对x的导数也增大。这就导致训练初期,预测值与 groud truth 差异过于大时,损失函数对预测值的梯度十分大,训练不稳定。
根据方程 (5),L1对x的导数为常数。这就导致训练后期,预测值与 ground truth 差异很小时,L1损失对预测值的导数的绝对值仍然为 1,而 learning rate 如果不变,损失函数将在稳定值附近波动,难以继续收敛以达到更高精度。
最后观察 (6),smooth L1在x较小时,对x的梯度也会变小,而在x很大时,对x的梯度的绝对值达到上限 1,也不会太大以至于破坏网络参数。smooth L1完美地避开了L1和L2损失的缺陷。其函数图像如下:


由图中可以看出,它在远离坐标原点处,图像和L1 loss 很接近,而在坐标原点附近,转折十分平滑,不像L1 loss 有个尖角,因此叫做 smooth L1 loss。
二.LogLoss对数损失函数(逻辑回归,交叉熵损失)
有些人可能觉得逻辑回归的损失函数就是平方损失,其实并不是。平方损失函数可以通过线性回归在假设样本是高斯分布的条件下推导得到,而逻辑回归得到的并不是平方损失。在逻辑回归的推导中,它假设样本服从伯努利分布(0-1分布),然后求得满足该分布的似然函数,接着取对数求极值等等。而逻辑回归并没有求似然函数的极值,而是把极大化当做是一种思想,进而推导出它的经验风险函数为:最小化负的似然函数(即max F(y, f(x)) —> min -F(y, f(x)))。从损失函数的视角来看,它就成了log损失函数了。
log损失函数的标准形式:
![]()
刚刚说到,取对数是为了方便计算极大似然估计,因为在MLE(最大似然估计)中,直接求导比较困难,所以通常都是先取对数再求导找极值点。损失函数L(Y, P(Y|X))表达的是样本X在分类Y的情况下,使概率P(Y|X)达到最大值(换言之,就是利用已知的样本分布,找到最有可能(即最大概率)导致这种分布的参数值;或者说什么样的参数才能使我们观测到目前这组数据的概率最大)。因为log函数是单调递增的,所以logP(Y|X)也会达到最大值,因此在前面加上负号之后,最大化P(Y|X)就等价于最小化L了。
逻辑回归最后得到的目标式子如下:
对于二分类:
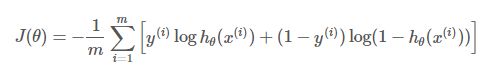
![]()
对于多分类:

注意:softmax使用的即为交叉熵损失函数,binary_cossentropy为二分类交叉熵损失,categorical_crossentropy为多分类交叉熵损失,当使用多分类交叉熵损失函数时,标签应该为多分类模式,即使用one-hot编码的向量。
对于softmax:
其作用机理如下,一般接在fc层之后,对于fc的输出做一个softmax的处理,得到所有类别的输出概率。

softmax函数如下:

那么softmax loss如下:
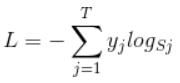
首先L是损失。Sj是softmax的输出向量S的第j个值,表示的是这个样本属于第j个类别的概率。yj前面有个求和符号,j的范围也是1到类别数T,因此y是一个1*T的向量,里面的T个值,而且只有1个值是1,其他T-1个值都是0。那么哪个位置的值是1呢?答案是真实标签对应的位置的那个值是1,其他都是0。所以这个公式其实有一个更简单的形式:
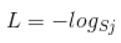
当然此时要限定j是指向当前样本的真实标签。
corss entropy是交叉熵的意思,它的公式如下:
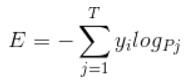
是不是觉得和softmax loss的公式很像。当cross entropy的输入P是softmax的输出时,cross entropy等于softmax loss。Pj是输入的概率向量P的第j个值,所以如果你的概率是通过softmax公式得到的,那么cross entropy就是softmax loss。即为如下公式所示,这里分母中的yi代表当前样本的真实类别所对应的那一个类别的softmax输出值的索引。
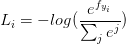
在pytorch中,
torch.nn torch.nn.functional (F) CrossEntropyLoss cross_entropy LogSoftmax log_softmax NLLLoss nll_loss 交叉熵的计算公式为:
其中p表示真实值,在这个公式中是one-hot形式;q是预测值,在这里假设已经是经过softmax后的结果了。
仔细观察可以知道,因为p的元素不是0就是1,而且又是乘法,所以很自然地我们如果知道1所对应的index,那么就不用做其他无意义的运算了(因为显然0乘以任何数结果为0)。所以在pytorch代码中target不是以one-hot形式表示的,而是直接用scalar表示。所以交叉熵的公式(m表示真实类别)可变形为:
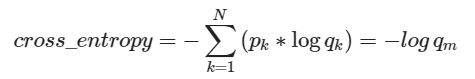
仔细看看,是不是就是等同于log_softmax和nll_loss两个步骤。
所以Pytorch中的F.cross_entropy会自动调用log_softmax和nll_loss来计算交叉熵,其计算方式如下:
代码示例:
>>> input = torch.randn(3, 5, requires_grad=True)
>>> target = torch.randint(5, (3,), dtype=torch.int64)
>>> loss = F.cross_entropy(input, target)
>>> loss.backward()
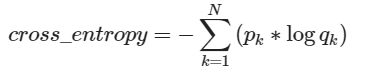

三.指数损失函数(Adaboost)
学过Adaboost算法的人都知道,它是前向分步加法算法的特例,是一个加和模型,损失函数就是指数函数。在Adaboost中,经过m此迭代之后,可以得到fm(x):
![]()
Adaboost每次迭代时的目的是为了找到最小化下列式子时的参数α 和G:
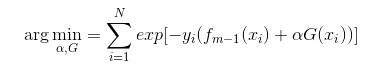
而指数损失函数(exp-loss)的标准形式如下

可以看出,Adaboost的目标式子就是指数损失,在给定n个样本的情况下,Adaboost的损失函数为:
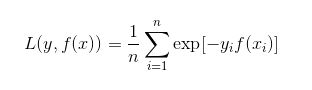
四.Hinge损失函数(SVM)
在机器学习算法中,hinge损失函数和SVM是息息相关的。在线性支持向量机中,最优化问题可以等价于下列式子:

下面来对式子做个变形,令:
![]()
于是,原式就变成了:

如若取λ=1/(2C),式子就可以表示成:
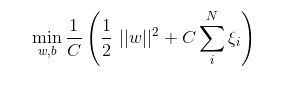
可以看出,该式子与下式非常相似:
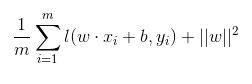
前半部分中的 l 就是hinge损失函数,而后面相当于L2正则项。
Hinge 损失函数的标准形式
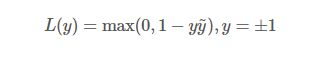
可以看出,当|y|>=1时,L(y)=0。
补充一下:在libsvm中一共有4中核函数可以选择,对应的是-t参数分别是:
- 0-线性核;
- 1-多项式核;
- 2-RBF核;
- 3-sigmoid核。
在实际应用中,一方面,预测值y并不总是属于[-1,1],也可能属于其他的取值范围;另一方面,很多时候我们希望训练的是两个元素之间的相似关系,而非样本的类别得分。所以下面的公式可能会更加常用:
L( y, y′) = max( 0, margin – (y–y′) )
= max( 0, margin + (y′–y) )
= max( 0, margin + y′ – y)
其中,y是正确预测的得分,y′是错误预测的得分,两者的差值可用来表示两种预测结果的相似关系,margin是一个由自己指定的安全系数。我们希望正确预测的得分高于错误预测的得分,且高出一个边界值 margin,换句话说,y越高越好,y′ 越低越好,(y–y′)越大越好,(y′–y)越小越好,但二者得分之差最多为margin就足够了,差距更大并不会有任何奖励。这样设计的目的在于,对单个样本正确分类只要有margin的把握就足够了,更大的把握则不必要,过分注重单个样本的分类效果反而有可能使整体的分类效果变坏。分类器应该更加专注于整体的分类误差。
举个栗子,假设有3个类cat、car、frog:
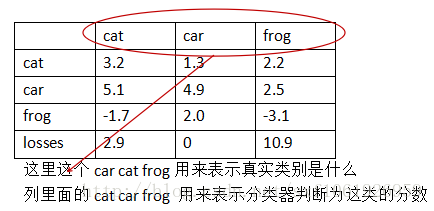
第一列表示样本真实类别为cat,分类器判断样本为cat的分数为3.2,判断为car的分数为5.1,判断为frog的分数为 -1.7。那这里的 hinge loss 怎么计算呢?

这里是让其他两类的分数去减去真实类别的分数,这相当于计算其他类与真实类之间的误差。因为我们希望错误类别的评分低于正确类别的评分,所以这个误差值越小越好。另外,还使用了一个边界值margin,取值为1,为了使训练出的分类器有更大的把握进行正确分类。
有多种 hinge loss 的变化形式,比如,Crammerand Singer提出的一种针对线性分类器的损失函数:

Weston and Watkins提出了一种相似定义,只不过用相加取代了求最大值:
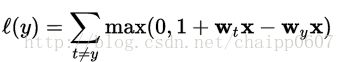
五.center loss
center loss的原理主要是在softmax loss的基础上,通过对训练集的每个类别在特征空间分别维护一个类中心,在训练过程,增加样本经过网络映射后在特征空间与类中心的距离约束,从而兼顾了类内聚合与类间分离。
同样是作为训练阶段的辅助loss,center loss相对于contrastive和triplet loss的优点显然省去了复杂并且含糊的样本对构造过程,只需要在特征输出层中引入即可,看下图:

另一个角度上说,center loss采取的是在训练过程中用空间换取时间的策略。
先看看center loss的公式LC。cyi表示第yi个类别的特征中心,xi表示全连接层之前的特征。后面会讲到实际使用的时候,m表示mini-batch的大小。因此这个公式就是希望一个batch中的每个样本的feature离feature 的中心的距离的平方和要越小越好,也就是类内距离要越小越好。这就是center loss。
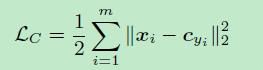
关于LC的梯度和cyi的更新公式如下:

这个公式里面有个条件表达式如下式,这里当condition满足的时候,下面这个式子等于1,当不满足的时候,下面这个式子等于0.
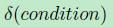
因此上面关于cyi的更新的公式中,当yi(表示yi类别)和cj的类别j不一样的时候,cj是不需要更新的,只有当yi和j一样才需要更新。
作者文中用的损失L的包含softmax loss和center loss,用参数南木达(打不出这个特殊字符)控制二者的比重,如下式所示。这里的m表示mini-batch的包含的样本数量,n表示类别数。
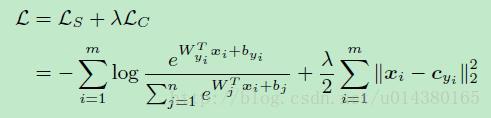
具体的算法描述可以看下面的Algorithm1:

def center_loss(features, label, alfa, nrof_classes):
"""Center loss based on the paper "A Discriminative Feature Learning Approach for Deep Face Recognition"
(http://ydwen.github.io/papers/WenECCV16.pdf)
https://blog.csdn.net/u014380165/article/details/76946339
"""
nrof_features = features.get_shape()[1]
#训练过程中,需要保存当前所有类中心的全连接预测特征centers, 每个batch的计算都要先读取已经保存的centers
centers = tf.get_variable('centers', [nrof_classes, nrof_features], dtype=tf.float32,
initializer=tf.constant_initializer(0), trainable=False)
label = tf.reshape(label, [-1])
centers_batch = tf.gather(centers, label)#获取当前batch对应的类中心特征
diff = (1 - alfa) * (centers_batch - features)#计算当前的类中心与特征的差异,用于Cj的的梯度更新,这里facenet的作者做了一个 1-alfa操作,比较奇怪,和原论文不同
centers = tf.scatter_sub(centers, label, diff)#更新梯度Cj,对于上图中步骤6,tensorflow会将该变量centers保留下来,用于计算下一个batch的centerloss
loss = tf.reduce_mean(tf.square(features - centers_batch))#计算当前的centerloss 对应于Lc
return loss, centers六.focal loss
1. 总述
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。
2. 损失函数形式
Focal loss是在交叉熵损失函数基础上进行的修改,首先回顾二分类交叉上损失:

 是经过激活函数的输出,所以在0-1之间。可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。那么Focal loss是怎么改进的呢?
是经过激活函数的输出,所以在0-1之间。可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。那么Focal loss是怎么改进的呢?


首先在原有的基础上加了一个因子,其中gamma>0使得减少易分类样本的损失。使得更关注于困难的、错分的样本。
例如gamma为2,对于正类样本而言,预测结果为0.95肯定是简单样本,所以(1-0.95)的gamma次方就会很小,这时损失函数值就变得更小。而预测概率为0.3的样本其损失相对很大。对于负类样本而言同样,预测0.1的结果应当远比预测0.7的样本损失值要小得多。对于预测概率为0.5时,损失只减少了0.25倍,所以更加关注于这种难以区分的样本。这样减少了简单样本的影响,大量预测概率很小的样本叠加起来后的效应才可能比较有效。
此外,加入平衡因子alpha,用来平衡正负样本本身的比例不均:文中alpha取0.25,即正样本要比负样本占比小,这是因为负例易分。

只添加alpha虽然可以平衡正负样本的重要性,但是无法解决简单与困难样本的问题。
gamma调节简单样本权重降低的速率,当gamma为0时即为交叉熵损失函数,当gamma增加时,调整因子的影响也在增加。实验发现gamma为2是最优。
3. 总结
作者认为one-stage和two-stage的表现差异主要原因是大量前景背景类别不平衡导致。作者设计了一个简单密集型网络RetinaNet来训练在保证速度的同时达到了精度最优。在双阶段算法中,在候选框阶段,通过得分和nms筛选过滤掉了大量的负样本,然后在分类回归阶段又固定了正负样本比例,或者通过OHEM在线困难挖掘使得前景和背景相对平衡。而one-stage阶段需要产生约100k的候选位置,虽然有类似的采样,但是训练仍然被大量负样本所主导。