深度学习中模型的构造(基于pytorch)
1.环境配置及要求
- pandas
- pytorch
- d2l包
2.什么是MODULE类
Module类是nn模块里提供的一个模型构造类,是所有神经网络模块的基类,我们可以继承它来定义我们想要的模型。我们将继承Module类构造多层感知机,定义的MLP类重载了Module类的__init__函数和forward函数.它们分别用于创建模型参数和定义前向计算。前向计算也就是正向传播。

import torch
from torch import nn
class MLP(nn.Module):
#声明带有模型参数的层,这里声明了两个全连接层
def __init__(self, **kwargs):
#调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Linear(784, 256) # 隐藏层
self.act = nn.ReLU()
self.output = nn.Linear(256, 10) # 输出层
# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出
def forward(self, x):
a = self.act(self.hidden(x))
return self.output(a)
我们可以实例化MLP类得到模型变量net.下面的代码初始化net并传入输入数据X做一次前向计算。其中,net(X)会调用MLP继承自Module类的__call__函数,这个函数将调用MLP类定义的forward函数来完成前向计算。

X=torch.rand(2,784)
net=MLP()
print(net)
net(X)
这里解释代码,生成随机数例子,两行784列,然后将MLP()实例化为net,输出net查看属性,再将X作为参数传入查看结果。
这里并没有将Module类命名为Layer层或者Module(模型),该类是一个可供自由组建的部件。它的子类既可以是一个层(如pytorch提供的Linear类),又可以是一个模型(如这里定义的MLP类),或者是模型的一个部分。
2.1 Sequential类
当模型的前向计算为简单串联各个层的计算时,Sequential类可以通过更加简单的方式定义模型,它可以接受一个子模块的有序字典或者一系列子模块作为参数来逐一添加Module的实例,而模型的前向计算就是将这些实例按添加的顺序注意计算。

class MySequential(nn.Module):
from collections import OrderedDict
def __init__(self,*args):
super(MySequential,self).__init__()
if len(args) == 1 and isinstance(args[0],OrderedDict):
#如果传入的是一个OrderedDict
for key, module in args[0].items():
self.add_module(key,module)
#add_module方法会将module添加进self._modules(一个OrderedDict)
else: #传入的是一些Module
for idx,module in enumerate(args):
self.add_module(str(idx),module)
def forward(self,input):
for module in self._modules.values():
input=module(input)
return input
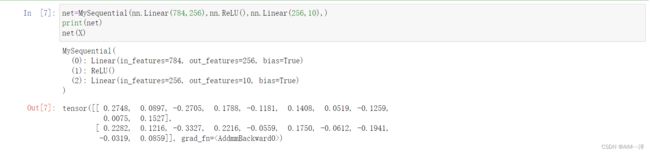
net=MySequential(nn.Linear(784,256),nn.ReLU(),nn.Linear(256,10),)
print(net)
net(X)
2.2ModuleList类
这个类是接收一个子模块的列表作为输入,然后也可以类似List那样进行append和extend操作:

net = nn.ModuleList([nn.Linear(784,256),nn.ReLU()])
net.append(nn.Linear(256,10))#类似list的append操作
print(net[-1]) #类似list的索访问
print(net)
2.3构造复杂的模型
上述的这些类可以使模型构造更加简单,且不需要定义forward函数,但直接继承Module类可以极大地拓展模型构造的灵活性
在这个网络中,我们通过get_constant函数创建训练中不被迭代的参数,即常数参数。在前向参数中,除了使用创建的常数参数外,我们还使用Tensor的函数和python的控制流,并多次调用相同的层。

class FancyMLP(nn.Module):
def __init__(self,**kwargs):
super(FancyMLP,self).__init__(**kwargs)
self.rand_weight=torch.rand((20,20),requires_grad=False)#不可训练参数(常数参数)
self.linear=nn.Linear(20,20)
def forward(self,x):
x=self.linear(x)#使用创建的常数参数,以及nn.functional中的relu函数和mm函数
x=nn.functional.relu(torch.mm(x,self.rand_weight.data)+1)
#复用全连接层,等价于两个全连接层共享参数
x=self.linear(x)
#控制流,这里我们需要调用item函数来返回标量进行比较
while x.norm().item() > 1:
x/=2
if x.norm().item()<0.8:
x*=10
return x.sum()
这个FancyMLP模型中,使用了常数权重rand_weight,做了矩阵乘法操作(torch.mm)并重复使用了相同的Linear层。

X=torch.rand(2,20)
net=FancyMLP()
print(net)
net(X)
因为FancyMLP和Sequential类都是Module类的子类,所以我们可以嵌套调用它们。
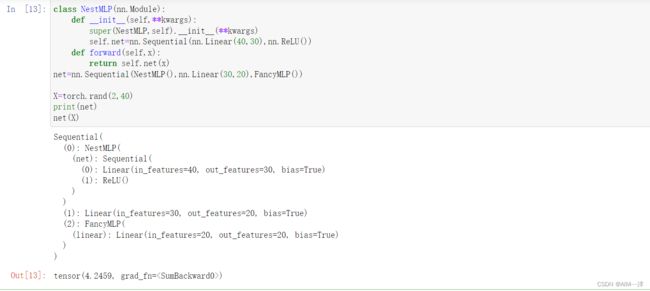
class NestMLP(nn.Module):
def __init__(self,**kwargs):
super(NestMLP,self).__init__(**kwargs)
self.net=nn.Sequential(nn.Linear(40,30),nn.ReLU())
def forward(self,x):
return self.net(x)
net=nn.Sequential(NestMLP(),nn.Linear(30,20),FancyMLP())
X=torch.rand(2,40)
print(net)
net(X)
3.总结可以通过继承 Module 类来构造模型。
- 可以通过继承Module类来构造模型
- Sequential 、 ModuleList 、 ModuleDict 类都继承⾃自 Module 类。
- 虽然 Sequential 等类可以使模型构造更更加简单,但直接继承 Module 类可以极⼤大地拓拓展模型构
造的灵活性。