RNN
RNN
1.1传统网络的局限性
在前馈神经网络中,信息的传递是单向的,这种限制虽然使得网络变得更容易学习,但在一定程度上也减弱了神经网络模型的能力。
在生物神经网络中,神经元之间的连接关系要复杂的多。前馈神经网络可以看着是一个复杂的函数,每次输入都是独立的,即网络的输出只依赖于当前的输入。
但是在很多现实任务中,网络的输入不仅和当前时刻的输入相关,也和其过去一段时间的输出相关。
比如一个有限状态自动机,其下一个时刻的状态(输出)不仅仅和当前输入相关,也和当前状态(上一个时刻的输出)相关。
此外,前馈网络难以处理时序数据,比如视频、语音、文本等。
时序数据的长度一般是不固定的,而前馈神经网络要求输入和输出的维数都是固定的,不能任意改变。
因此,当处理这一类和时序相关的问题时,就需要一种能力更强的模型。
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络。在循环神经网络中,神经元不但可以接受其它神经元的信息,也可以接受自身的信息,形成具有环路的网络结构。
和前馈神经网络相比,循环神经网络更加符合生物神经网络的结构。
循环神经网络已经被广泛应用在语音识别、语言模型以及自然语言生成等任务上。
循环神经网络的参数学习可以通过随时间反向传播算法来学习。
随时间反向传播算法即按照时间的逆序将错误信息一步步地往前传递。
当输入序列比较长时,会存在梯度爆炸和消失问题,也称为长期依赖问题。
为了解决这个问题,人们对循环神经网络进行了很多的改进,其中最有效的改进方式引入门控机制。
1.2 RNN
循环神经网络通过使用带自反馈的神经元,能够处理任意长度的时序数据。
给定一个输入序列 x 1 : T = ( x 1 , x 2 , . . . , x t , . . , x T ) x_{1:T} = (x_1, x_2,..., x_t,.., x_T ) x1:T=(x1,x2,...,xt,..,xT),循环神经网络通过下面
公式更新带反馈边的隐藏层的活性值 h t h_t ht:
h t = f ( h t − 1 , x t ) h _t = f(h_{t-1},x_t) ht=f(ht−1,xt)
假设在时刻t时,网络的输入为 x t x_t xt,隐藏层状态(即隐藏层神经元活性值)
为 h t h_t ht 不仅和当前时刻的输入 x t x_t xt 相关,也和上一个时刻的隐藏层状态 h t − 1 h_{t−1} ht−1 相关。
z t = U h t − 1 + W x t + b z_t = Uh_{t-1} + Wx_t +b zt=Uht−1+Wxt+b
h t = f ( z t ) h_t = f(z_t) ht=f(zt)
或 h t = f ( U h t − 1 + W x t + b ) h_t = f(Uh_{t-1} + Wx_t +b) ht=f(Uht−1+Wxt+b)
其中 z t z_t zt 为隐藏层的净输入, f ( x ) f(x) f(x)是非线性激活函数,通常为Logistic函数或Tanh
函数, U U U为状态-状态权重矩阵,W 为状态-输入权重矩阵,b为偏置。
如果我们把每个时刻的状态都看作是前馈神经网络的一层的话,循环神经
网络可以看作是在时间维度上权值共享的神经网络。

1.3 反向传播
BPTT
定义误差项 σ t , k = ∂ L t ∂ z k \sigma_{t,k} = \frac { \partial L_t}{ \partial z_k} σt,k=∂zk∂Lt
为第 t 时刻的损失对第 k 时刻隐藏神经层的净输入 z k z_k zk 的导数,则 的导数,则
σ t , k = ∂ L t ∂ z k = ∂ h k ∂ z k ∂ z k + 1 ∂ h k ∂ L t ∂ z k + 1 = d i a g ( f ′ ( z k ) ) U T σ t , k + 1 \sigma_{t,k} = \frac { \partial L_t}{ \partial z_k}\\ =\frac { \partial h_k}{ \partial z_k} \frac { \partial z_k+1}{ \partial h_k}\frac { \partial L_t}{ \partial z_k+1}\\ = diag(f'(z_k)) U^T \sigma_{t,k+1} σt,k=∂zk∂Lt=∂zk∂hk∂hk∂zk+1∂zk+1∂Lt=diag(f′(zk))UTσt,k+1
整个序列的损失函数L关于参数U的梯度
∂ L ∂ U = ∑ t = 1 T ∑ k = 1 t σ t , k h k − 1 T \frac { \partial L}{ \partial U}= \sum_{t =1 } ^T \sum_{k =1}^t \sigma_{t,k} h_{k-1}^T ∂U∂L=t=1∑Tk=1∑tσt,khk−1T
L关于权重W 和偏置b的梯度为
∂ L ∂ W = ∑ t = 1 T ∑ k = 1 t σ t , k x k T \frac { \partial L}{ \partial W}= \sum_{t =1 } ^T \sum_{k =1}^t \sigma_{t,k} x_{k}^T ∂W∂L=t=1∑Tk=1∑tσt,kxkT
∂ L ∂ b = ∑ t = 1 T ∑ k = 1 t σ t , k \frac { \partial L}{ \partial b}= \sum_{t =1 } ^T \sum_{k =1}^t \sigma_{t,k} ∂b∂L=t=1∑Tk=1∑tσt,k
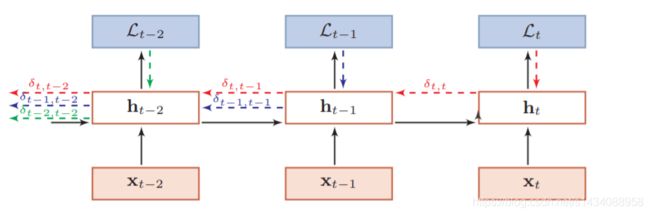
问题与改进
σ t , k = d i a g ( f ′ ( z k ) ) U T σ t , k + 1 \sigma_{t,k}= diag(f'(z_k)) U^T \sigma_{t,k+1} σt,k=diag(f′(zk))UTσt,k+1
当 d i a g ( f ′ ( z k ) ) U T > 1 diag(f'(z_k)) U^T > 1 diag(f′(zk))UT>1 如果时间间隔t − k 过大, σ t , k \sigma_{t,k} σt,k 会趋向于 无穷,产生梯度爆炸问题
当 d i a g ( f ′ ( z k ) ) U T < 1 diag(f'(z_k)) U^T < 1 diag(f′(zk))UT<1 如果时间间隔t − k 过大, σ t , k \sigma_{t,k} σt,k 会趋向于 0,产生梯度消失问题
虽然简单循环网络理论上可以建立长时间间隔的状态之间的依赖关系,但是由于梯度爆炸或消失问题,实际上只能学习到短期的依赖关系。
这样,如果t时刻的输出 y t y_t yt依赖于t−k时刻的输入 x t − k x_{t−k} xt−k,当间隔k比较大时,简单神经网络很
难建模这种长距离的依赖关系,称为长期依赖问题。
改进:
梯度爆炸 :一般而言,循环网络的梯度爆炸问题比较容易解决,一般通过权重衰减或梯度截断来避免。
梯度消失 : 引入门控机制来进一步改进模型
改进的循环神经网络
2.1 LSTM
LSTM网络引入一个新的内部状态(internal state) c t c_t ct 专门进行
线性的循环信息传递,同时(非线性)输出信息给隐藏层的外部状态 h t h_t ht。
c t = f t ⨀ c t − 1 + i t ⨀ c t ′ c_t = f_t \bigodot c_{t-1} + i_t \bigodot c'_t ct=ft⨀ct−1+it⨀ct′
h t = o t ⨀ t a n h ( c t ) h_t = o_t \bigodot tanh(c_t) ht=ot⨀tanh(ct)
其中 f t , i t f_t,i_t ft,it 和 o t o_t ot 为三个门(gate)来控制信息传递的路径;⊙为向量元素乘积;
c t − 1 c_{t−1} ct−1 为上一时刻的记忆单元; c t ′ c'_t ct′ 是通过非线性函数得到候选状态
在数字电路中,门(Gate)为一个二值变量{0, 1},0代表关闭状态,不许
任何信息通过;1代表开放状态,允许所有信息通过。LSTM网络中的“门”是
一种“软”门,取值在(0, 1)之间,表示以一定的比例运行信息通过。LSTM网
络中三个门的作用为
• 遗忘门 f t f_t ft 控制上一个时刻的内部状态 c t − 1 c_{t−1} ct−1 需要遗忘多少信息。
• 输入门 i t i_t it 控制当前时刻的候选状态 c t ′ c'_t ct′ 有多少信息需要保存。
• 输出门 o t o_t ot控制当前时刻的内部状态 c t c_t ct有多少信息需要输出给外部状态 h t h_t ht。
当 f t = 0 , i t = 1 f_t = 0, i_t = 1 ft=0,it=1时,记忆单元将历史信息清空,并将候选状态向量 c t ′ c'_t ct′ 写入。
但此时记忆单元 c t c_t ct 依然和上一时刻的历史信息相关。
当 f t = 1 , i t = 0 f_t = 1, i_t = 0 ft=1,it=0时,记忆单元将复制上一时刻的内容,不写入新的信息。
三个门的计算方式为:
i t = σ ( W i x t + U i h t − 1 + b i ) i_t = \sigma(W_ix_t + U_ih_{t-1} +b_i) it=σ(Wixt+Uiht−1+bi)
f t = σ ( W f x t + U f h t − 1 + b f ) f_t = \sigma(W_fx_t + U_fh_{t-1} +b_f) ft=σ(Wfxt+Ufht−1+bf)
o t = σ ( W o x t + U o h t − 1 + b o ) o_t = \sigma(W_ox_t + U_oh_{t-1} +b_o) ot=σ(Woxt+Uoht−1+bo)
其中 σ ( x ) \sigma(x) σ(x)为Logistic函数,其输出区间为(0, 1), x t x_t xt 为当前时刻的输入, h t − 1 h_{t−1} ht−1 为
上一时刻的外部状态。
下图给出了 LSTM 网络的循环单元结构,其计算过程为:
(1)首先利用上一时刻的外部状态 h t − 1 h_{t−1} ht−1 和当前时刻的输入 x t x_t xt,计算出三个门,以及候选状态
c t ′ c'_t ct′;
(2)结合遗忘门 f t f_t ft 和输入门 i t i_t it 来更新记忆单元 c t c_t ct;
(3)结合输出门 o t o_t ot,将内部状态的信息传递给外部状态 h t h_t ht。

循环神经网络中的隐状态h存储了历史信息,可以看作是一种记忆(Memory)。
在简单循环网络中,隐状态每个时刻都会被重写,因此可以看作是一种短期记忆(Short-Term Memory)。
在神经网络中,长期记忆(Long-Term Memory)可以看作是网络参数,隐含了从训练数据中学到的经验,并更新周期要远远慢
于短期记忆。
而在LSTM网络中,记忆单元c可以在某个时刻捕捉到某个关键信息,并有能力将此关键信息保存一定的时间间隔。
记忆单元c中保存信息的生命周期要长于短期记忆h,但又远远短于长期记忆,因此称为长的短期记忆(Long Short-Term Memory)。
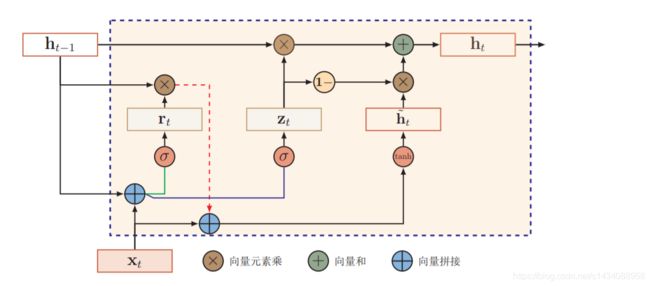
2.2 GRU
门控循环单元(Gated Recurrent Unit,GRU)网络 [Cho et al., 2014, Chung
et al., 2014]是一种比LSTM网络更加简单的循环神经网络。
和 LSTM 不同,GRU 不引入额外的记忆单元,
GRU 是引入一个更新门(UpdateGate)来控制当前状态需要从历史状态中保留多少信息(不经过非线性变换),
以及需要从候选状态中接受多少新信息。
h t = z t ⨀ h t − 1 + ( 1 − z t ) ⨀ h t ′ h_t = z_t \bigodot h_{t-1} +(1-z_t) \bigodot h'_t ht=zt⨀ht−1+(1−zt)⨀ht′
其中 z t ∈ [ 0 , 1 ] z_t \in [0, 1] zt∈[0,1]为更新门
z t = σ ( W z x t + U z h t − 1 + b z ) z_t = \sigma(W_zx_t + U_zh_{t-1} +b_z) zt=σ(Wzxt+Uzht−1+bz)
h t ′ = t a n h ( W h x t + U h ( r t ⨀ h t − 1 ) + b h ) h'_t = tanh(W_hx_t + U_h(r_t \bigodot h_{t-1}) +b_h) ht′=tanh(Whxt+Uh(rt⨀ht−1)+bh)
r t = σ ( W r x t + U r h t − 1 + b r ) r_t = \sigma(W_rx_t + U_rh_{t-1} +b_r) rt=σ(Wrxt+Urht−1+br)
其中 h t ′ h'_t ht′ 表示当前时刻的候选状态, 这里使用tanh激活函数是由于其导数有比较大的值域,
缓解梯度消失问题。
r t ∈ [ 0 , 1 ] r_t \in [0, 1] rt∈[0,1]为重置门(Reset Gate),用来控制候选状态 h t ′ h'_t ht′ 的计算是否依赖上一时刻的状态 h t − 1 h_{t−1} ht−1。
可以看出,当 z t = 0 , r = 1 z_t = 0, r = 1 zt=0,r=1 时,GRU 网络退化为简单循环网络;
若 z t = 0 , r = 0 z_t =0, r = 0 zt=0,r=0时,当前状态 h t h_t ht 只和当前输入 x t x_t xt 相关,和历史状态 h t − 1 h_{t−1} ht−1 无关。
当 z t = 1 z_t = 1 zt=1时,当前状态 h t = h t − 1 h_t = h_{t−1} ht=ht−1 等于上一时刻状态 h t − 1 h_{t−1} ht−1 ,和当前输入 x t x_t xt 无关
2.3 Bi-RNN
在有些任务中,一个时刻的输出不但和过去时刻的信息有关,也和后续时刻的信息有关。
比如给定一个句子,其中一个词的词性由它的上下文决定,即包含左右两边的信息。
因此,在这些任务中,我们可以增加一个按照时间的逆序来传递信息的网络层,来增强网络的能力。
双向循环神经网络(Bidirectional Recurrent Neural Network,Bi-RNN)由
两层循环神经网络组成,它们的输入相同,只是信息传递的方向不同。
假设第1层按时间顺序,第2层按时间逆序,在时刻t时的隐状态定义为 h t 1 , h t 2 h_t^1,h_t^2 ht1,ht2
h t 1 = f ( W 1 x t + U 1 ( h t − 1 1 ) + b 1 ) h^1_t = f(W^1x_t + U^1(h^1_{t-1}) +b^1) ht1=f(W1xt+U1(ht−11)+b1)
h t 2 = f ( W 2 x t + U 2 ( h t + 1 2 ) + b 2 ) h^2_t = f(W^2x_t + U^2(h^2_{t+1}) +b^2) ht2=f(W2xt+U2(ht+12)+b2)
h t = h t 1 + h t 2 h_t = h_t^1 + h_t^2 ht=ht1+ht2
其中 + 为 向量拼接

2.4 RecNN
递归神经网络(Recursive Neural Network,RecNN)是循环神经网络在有
向无循环图上的扩展 [Pollack, 1990]。递归神经网络的一般结构为树状的层次
结构,如下图所示。

参考 :
[1]: https://nndl.github.io/