2022年3月30日快手广告算法面试题
1、手写交叉熵公式
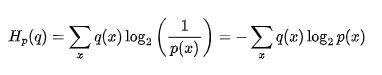
2、为什么用交叉熵不用均方误差
1、均方误差作为损失函数,这时所构造出来的损失函数是非凸的,不容易求解,容易得到其局部最优解;而交叉熵的损失函数是凸函数;
2、均方误差作为损失函数,求导后,梯度与sigmoid的导数有关,会导致训练慢;而交叉熵的损失函数求导后,梯度就是一个差值,误差大的话更新的就快,误差小的话就更新的慢点。
3、说一下Adam优化的优化方式
Adam算法即自适应时刻估计方法(Adaptive Moment Estimation),能计算每个参数的自适应学习率。这个方法不仅存储了AdaDelta先前平方梯度的指数衰减平均值,而且保持了先前梯度M(t)的指数衰减平均值,这一点与动量类似。
Adam实际上就是将Momentum和RMSprop集合在一起,把一阶动量和二阶动量都使用起来了。
4、DQN是On-policy还是off-policy?有什么区别
off-policy的方法将收集数据作为RL算法中单独的一个任务,它准备两个策略:行为策略(behavior policy)与目标策略(target policy)。行为策略是专门负责学习数据的获取,具有一定的随机性,总是有一定的概率选出潜在的最优动作。而目标策略借助行为策略收集到的样本以及策略提升方法提升自身性能,并最终成为最优策略。Off-policy是一种灵活的方式,如果能找到一个“聪明的”行为策略,总是能为算法提供最合适的样本,那么算法的效率将会得到提升。on-policy 里面只有一种策略,它既为目标策略又为行为策略。
5、value based和policy based算法的区别
1. 生成policy上的差异:一个随机,一个确定
Value-Base 中的 action-value估计值最终会收敛到对应的true values(通常是不同的有限数,可以转化为0到1之间的概率),因此通常会获得一个确定的策略(deterministic policy)
Policy-Based不会收敛到一个确定性的值,另外他们会趋向于生成optimal stochastic policy。如果optimal policy是deterministic的,那么optimal action对应的性能函数将远大于suboptimal actions对应的性能函数,性能函数的大小代表了概率的大小
随即策略的优点:
在很多问题中的最优策略是随机策略(stochastic policy)。(如石头剪刀布游戏,如果确定的策略对应着总出石头,随机策略对应随机出石头、剪刀或布,那么随机策略更容易获胜)
2. 一个连续,一个离散
Value-Base,对于连续动作空间问题,虽然可以将动作空间离散化处理,但离散间距的选取不易确定。过大的离散间距会导致算法取不到最优action,会在这附近徘徊,过小的离散间距会使得action的维度增大,会和高维度动作空间一样导致维度灾难,影响算法的速度。
Policy-Based适用于连续的动作空间,在连续的动作空间中,可以不用计算每个动作的概率,而是通过Gaussian distribution (正态分布)选择action。
3. 在Value-Base中,value function 的微小变化对策略的影响很大,可能直接决定了这个action是否被选取而Policy-Based避免了此缺点
6、归一化[-1,1]和归一化到[0,1]对后面的网络计算有什么影响吗
一般会归一化到[-1,1],因为大部分网络是偏好零对称输入的,神经网路中使用激活函数一般都是ReLU,如果ReLU的输入都是正数,那么它其实就是一个恒等函数,有没有它都一个样,ReLU就失去了意义。如果ReLU的输入都是负数的话,会出现“死区”,即神经元输出都是0,为了避免这个问题,需要令ReLU的输入尽量正负平衡,比如在ReLU前加一个BN。
7、Leetcode16题——三数之和
思路:排序 + 双指针
本题的难点在于如何去除重复解。
1、判断:如果len(nums) < 3 ,直接返回空
2、使用sort( )方法进行排序
3、遍历排序后的数组
若nums[i] > 0,后面不可能有三个数加和等于0,直接返回结果即可。
对于重复元素,跳过,避免出现重复解。
令左指针 left = i + 1,右指针 right = n - 1,当left < right,执行循环,三种情况:1、当满足三数之和为0时,需要判断左界和右界是否和下一位重复,进行去重,并更新左右指针;2、如果和大于0,右指针左移;3、如果小于0,左指针右移。
代码如下:
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
n = len(nums)
res = []
if n < 3:
return []
nums.sort()
for i in range(n):
if nums[i] > 0:
return res
if i > 0 and nums[i] == nums[i -1]:
continue
left = i + 1
right = n -1
while left < right:
if nums[i] + nums[left] + nums[right] == 0:
res.append([nums[i],nums[left],nums[right]])
while left < right and nums[left] == nums[left + 1]:
left += 1
while left < right and nums[right] == nums[right - 1]:
right -= 1
left += 1
right -= 1
elif nums[i] + nums[left] + nums[right] < 0:
left += 1
else:
right -= 1
return res
时间复杂度:O(n^2)
空间复杂度:O(1)
8、Leetcode122题——买卖股票的最佳时机
思路:动态规划
代码参考:
class Solution(object):
def maxProfit(self, prices):
"""
:type prices: List[int]
:rtype: int
"""
m = len(prices)
dp0 = 0
dp1 = -prices[0]
for i in range(1, m):
dp0 = max(dp0, dp1 + prices[i])
dp1 = max(dp0 - prices[i], dp1)
return dp0