2022/9/26-9/30 周报
周报内容:
1.精读论文两篇
2.复现论文
3.基础知识学习
4.下周工作计划
学习产出:
论文一:ChangeChip: A Reference-Based Unsupervised Change Detection for PCB Defect Detection(IEEE 2021)
https://github.com/Scientific-Computing-Lab-NRCN/ChangeChip
算法:
1.预处理阶段:
成像设置:在相同的成像环境中捕获两个输入图像,并保持成像条件尽可能相同。
(1)Deep Extreme Cut (DEXTR):进行pcb提取,以忽略背景,或者如果仅需要比较pcb的一部分,甚至提取特定成分。
(2)Image Registration(图像配准):我们使用基于特征的配准,基于提取特征点以及描述符并将其匹配,然后使用相应的对来计算转换矩阵,该转换矩阵将目标图像转换为与参考图像相同的方向和位置。为了提取和描述pcb中的特征点,我们使用比例不变特征变换 (SIFT) [22] 算法。然后,通过为一个图像中的每个特征点找到另一个图像中的特征点之间的最佳匹配 (这使欧几里得距离最小化),对进行匹配。因为匹配的数量可能超过了定义适当变换所需的最小值,并且它们可能不遵循单个线性模型,所以迭代方法RANSAC [24] 用于变换矩阵的稳健估计。
(3)减少光照变化
2.PCA-Kmeans Change Detection:
使用pca-kmeans变化检测算法的变体,该算法使用描述符,该描述符为每个像素提取一组特征,这些特征描述该像素是否是从一个图像到另一个图像的 “更改”。通过PCA将每组特征 (即描述符) 简化到较小的维度,然后使用Kmeans将所有这些简化的特征聚集到变化程度的类别中。类的数量n是我们应用程序的一个参数,通常设置在10左右,并且可能因系统而异,以实现优化的结果。
3.后处理阶段: 使用MSE启发式算法进行类分析
使用均方误差 (MSE) 度量:根据MSE分数对类别进行排序,每个类别根据其索引的顺序从蓝色接收颜色。具有最小MSE分数的类别,MSE得分最高的班级为红色。将颜色分配给类会产生有意义的热图,该热图指示变化的强度。使用具有噪声的应用程序的基于密度的空间聚类 (DBSCAN) 算法 [25] 对MSE分数进行聚类,然后丢弃最低的MSE分数类别。DBSCAN不需要指定群集的数量。相反,它需要设置密度参数 (eps),根据我们的测试产生更好的结果。
评估:
1.CD-PCB数据集:
该数据集由20对PCB图像组成,它们之间有注释的变化。Cd-pcb包括具有各种类型的挑战性缺陷的PCB的图像。其中两对是通过射线照相技术捕获的,另外18对是在保持相同成像条件的既定环境下合成和捕获的 (尽管可以实现更好的设置 [26])。用于构建cd-pcb的捕获系统模型:

2.评价方法
我们使用eprecision和recall来评估。
3.结果
用于进行此实验的参数为h = 5 (大小为5 × 5的窗口) 和n = 16 (聚类描述符的类数)。eps = 0.02 (用于对n个MSE值进行聚类的DBSCAN的密度参数),并且对于射线照相图像,我们设置eps = 0.05,因为噪声在最低MSE得分类别附近的集中较少。
在CD-PCB数据集上的recall=0.87,eprecision=0.8,相对于整个图像,误报的数量非常小。
官方实验结果图(原数据集缺失):

4.结论、局限性和今后的工作
系统的目标是查找两个图像之间的变化,而实际上,变化可能除了缺陷之外还包括噪声。
复现:
Input image(有缺陷):

Reference image(无缺陷):

diff image:

缺点:
1.需要有对应相同的无缺陷板,局限性强
2.数据集缺失,共20对图片,但第3、6、7、8、9、10、12、15、16组缺失input、reference图像,13、14缺失reference图像。
措施:
提取剩余可用数据集
论文二、Anomaly Detection for Solder Joints Using β-VAE
介绍:
在SMD装配线中使用了自动光学检查 (AOI) 设备。将焊点缺陷检测视为异常检测问题,并采用深度生成模型,特别是 β-VAE [3],该模型可以仅从正常样本中学习。β-VAE是VAE的一种变体 [4],[5],它最大化了生成真实数据的概率,同时用可调超参数 β 平衡了似然性和Kullback-Leibler (KL) 发散项。β 项着重于学习统计上独立的潜在因子,这些潜在因子导致解纠缠的表示,其中一个潜在单元对单个生成因子的变化敏感
这项研究的主要贡献如下 :( i) 我们试图解决一个独特的焊点检查问题在不受限制的领域,因此,它不需要专门的照明,特征工程,训练中的异常样品或无错误的参考板。(ii) 我们设计了针对此问题量身定制的 β-VAE架构,并使用不同的异常评分技术对其进行了分析,并研究了 β 对焊点检查的影响。此外,我们展示了使用 β-VAE的好处,并展示了正常和异常焊料的潜在空间表示如何明显分离。(iii) 我们的模型可以使用单个架构检查集成电路 (IC) 和非IC组件焊点。
方法:
1.VAE与β-VAE
为了训练VAE,目标是找到参数 θ 和 φ,使数据点p θ(X) 的边际可能性的证据下限 (ELBO) L最大化。VAE体系结构的说明如下图所示:

β-VAE迫使学习数据的更有效的潜在表示。这提供了更高的解缠结性能。但过高 β 值会导致在通过受限的潜在通道时由于信息丢失而导致较差的重建。
2.异常评分
样本X输入到训练过的VAE的编码器中。编码器输出每个图像的均值和标准偏差的向量。应用重新参数化技巧来获得潜在向量z,该潜在向量z是从高斯分布中采样的,并且由编码器计算出均值和标准差。然后解码器从此分布重构输入图像。使用反向传播梯度来表征输入需要多少模型更新以检测异常,通过反向传播重建损耗来计算每个解码器层相对于模型参数的梯度。这种使用梯度约束来训练自动编码器并使用重建误差和梯度损失的组合作为异常分数的异常检测算法称为GradCon。
3.决策规则
计算异常得分后,使用决策规则通过与阈值进行比较来确定样本是异常还是正常 [27]。决策规则的阈值被视为超参数,并在验证集上确定。它被设置为接近在验证集上获得的异常分数的值。
实验:
1.数据集与预处理
我们的数据集(私有)有2513训练样本(正常),567验证样本(正常)和150测试一下样本 (66个异常和84个正常)。一些异常样本是从开放数据集获得的 [29]。测试一下集中的异常 (缺陷焊点) 样品包括(solder bridge, insufficient solder, excessive solder, solder flags, solder dewetting, pin holes, flux residues, missing and shifted components).焊桥,焊锡不足,焊锡过多,焊锡标志,焊锡去湿,针孔,助焊剂残留物,缺失和移位的组件。仅在测试期间提供这些样本的地面真实标签,以评估异常检测性能。对于数据预处理,我们的数据是从短边裁剪的,以保持焊点图像的完整性,并调整为64x64。然后,将数据归一化为零均值,单位方差的范围从-1到1,并将水平翻转作为随机变换应用,以避免过拟合,但不会增加数据集大小。
2.框架与超参数
该模型用ADAM优化器 [31] 训练100个时期,初始学习率为1e-2。我们采用了L2正则化来惩罚特征的高权重。选定的批次大小为64。选择 β (KL权重) 大于1,
结果:
精度、召回率和F1-score被用作评估指标。召回率显示正确检测到实际异常的比例,而精确度是这些估计正确性的比率。计算F1-score以显示根据这些指标的模型的总体准确性。所有结果至少平均运行50次。对于 β = 3,可以学到更好的解纠缠表示。实验结果如下图所示:
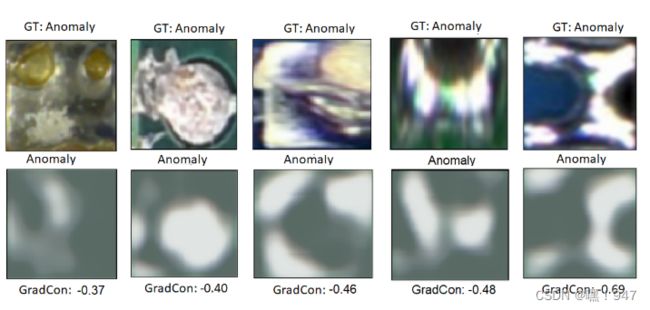
图中第一行显示带有相应ground-truth标签的原始输入图像,第二行显示重建以及预测的标签和异常得分
缺点:
数据集为私用,需自行准备数据集。
解决方案:
缺陷数据集采用百度飞桨数据集,正常样本需要联系厂家提供。
并按如下所示配置数据集:

基础知识学习:
“西瓜书”、李宏毅视频
下周工作计划:
CVPR2022新论文两篇