PyTorch日积月累_3-neural network
文章目录
-
- 神经网络工具箱 `nn.Module`
-
- 1. 简单的线性回归类
- 2. 感知机
- 3. 常用方法
- 1. 卷积层和池化层
- 2. RNN、LSTM
- 3. 损失函数
- 4. 其他类型的层
- 两种特殊Module
-
-
- `nn.Sequential`
- `nn.ModuleList`
-
- PyTorch中的优化器
-
- 1. 优化器的基本使用方法
- 2. 针对网络不同部分设置不同学习率
- 3. 在运行过程中调整学习率
- 其他
-
- 1. `nn.Module`对象和`torch.functional`的区别
-
- 区别
- 使用习惯
- 案例
- 2. 初始化策略
- 实践:搭建ResNet34
神经网络工具箱 nn.Module
1. 简单的线性回归类
一个基于nn.Module的简单线性回归类的实现
import torch
import torch.nn as nn
class LinearModel(nn.Module):
def __init__(self,in_features,out_features):
super(LinearModel,self).__init__()
self.w = nn.Parameter(torch.randn(in_features,out_features))
self.b = nn.Parameter(torch.randn(out_features))
def forward(self,x):
return x.mm(self.w)+self.b
layer = LinearModel(5,2)
x = torch.randn(1,5)
y = layer(x)
其中需要注意的几点:
- 当前模型需要继承
nn.Module,然后构造函数调用父类的构造函数,通常使用super(LinearModel,self).__init__(),而不是nn.Module.__init__() - 在网络的构造函数中,将待学习的参数封装为
nn.Parameter,默认求导; - 调用网络的实例时,可以直接采用类似
实例名(输入参数)的形式,等价于实例名.__call__(输入参数),默认调用forward和部分钩子函数,因而不推荐直接使用实例名.forward(输入参数)
2. 感知机
基于线性回归类,我们可以实现更加复杂的例子,如两层的感知机:
class Perceptron(nn.Module):
def __init__(self,in_features,hidden_features,out_features):
super().__init__()
self.layer1 = LinearModel(in_features,hidden_features)
self.layer2 = LinearModel(hidden_features,out_features)
def forward(self,x):
y = torch.sigmoid(self.layer1(x))
return self.layer2(y)
perceptron = Perceptron(5,10,2)
x = torch.randn(4,5)
y = perceptron(x)
在PyTorch中的torch.nn下给出了很多典型的神经网络层的实现,并针对CuDNN进行了优化,参考官方文档,下文进行简单的介绍。
需要注意上面两个例子的输入输出的大小,都不是单个数据,而是一个batch,对于单个数据,需要通过tensor.unsequeeze(0)拓展为batch size等于1的数据。
3. 常用方法
继承自nn.Module的子类的实例有一些常用方法:
| 方法名 | 功能 |
|---|---|
named_parameters和parameters |
获取模型参数,返回结果是生成器,可以直接传入优化器 |
train和eval |
切换训练和测试状态,dropout层和BN层在测试和训练时有所不同 |
named_buffer和buffer |
显示计算图中缓存的张量,例如BN层中的均值和标准差 |
named_children和children |
模型的子模块 |
apply |
传入函数/匿名函数,对模块类递归的调用该函数,见下文 |
apply方法应用案例:将一个神经网络中线性回归层的参数初始化为1.0
import torch
import torch.nn as nn
# 注意,torch.no_grad既可以做上下文管理器,也可以做装饰器
@torch.no_grad()
def init_weights(m):
"""将所有的线性层的参数设置为1.0"""
print(m)
if type(m) == nn.Linear:
m.weight.fill_(1.0)
print(m.weight)
net = nn.Sequential(nn.Linear(2,2),nn.Linear(2,2))
net.apply(init_weights)
##torch.nn下常用的网络层
1. 卷积层和池化层
图像相关层主要包括卷积层(Conv)、池化层(Pool)等,这些层在实际使用中可分为一维(1D)、二维(2D)、三维(3D),池化方式又分为平均池化(AvgPool)、最大值池化(MaxPool)、自适应池化(Adaptive AvgPool)等。而卷积层除了常用的前向卷积之外,还有逆卷积(Transpose Conv)。
例如,下面我们通过自定义一个锐化卷积核,并通过nn.Conv2d实现:
import torch
from torchvision import transforms
from PIL import Image
lena = Image.open('lena.png')
to_tensor = transforms.ToTensor()
lena_tensor = to_tensor(lena).unsqueeze(0) # C,H,W -> B,C,H,W
# kernel
kernel = torch.ones(3,3)/-9
kernel[1][1] = 1
# Convolution Layer
conv_layer = torch.nn.Conv2d(1,1,(3,3),1,bias=False)
conv_layer.weight.data = kernel.view(1,1,3,3)
# operation
lenax_tensor = conv_layer(lena_tensor)
# output transform
to_PILImage = transforms.ToPILImage()
lenax = to_PILImage(lenax_tensor.squeeze(0)) # B,C,H,W -> C,H,W
lenax.show() # 取决于系统默认的bmp打开方式
池化层是一种特殊的卷积层,这里我们使用平均池化,将lena图像缩小一半:
from PIL import Image
import torch
from torch import nn
from torchvision import transforms
lena = Image.open('lena.png')
pool_layer = nn.AvgPool2d(2,2)
lena_tensor = transforms.ToTensor(lena).unsqueeze(0)
# operation
lenax_tensor = pool(lena_tensor)
# output
lenax = transforms.ToPILImage(lenax_tensor.unsqueeze(0))
lenax.show()
注意上面两个例子中的tensor和PIL Image转换时的维度变化。
2. RNN、LSTM
torch.nn下封装了RNN、LSTM和DRU等神经网络模块,使用案例如下所示:
t.manual_seed(1000)
# lstm输入向量4维,隐藏层维度3,lstm单元数等于1
# lstm: input_size=4,hidden_size=3,num_layers=1
lstm = nn.LSTM(4, 3, 1)
# 初始状态:1层,batch_size=6,隐藏层维数等于3
h0 = t.randn(1, 6, 3) # (D*num_layers,N,H_out)
c0 = t.randn(1, 6, 3) # (D*num_layers,N,H_out)
# D = 2 , if bidirectional else 1
# 输入:序列长度都为2,batch_size=6,序列中每个元素占4维
# if batch_first=False, then (L,N,H_in), else (N,L,H_in)
input = t.randn(2, 6, 4)
# Inputs: input, (h_0, c_0)
out, hn = lstm(input, (h0, c0))
out
这里的多层RNN实际上是通过调用单层的RNN Cell实现的,使用案例如下所示:
t.manual_seed(1000)
input = t.randn(2, 3, 4)
# 一个LSTMCell对应的层数只能是一层
lstm = nn.LSTMCell(4, 3)
hx = t.randn(3, 3)
cx = t.randn(3, 3)
out = []
for i_ in input:
hx, cx=lstm(i_, (hx, cx))
out.append(hx)
t.stack(out)
RNN常用于NLP中,PyTorch也针对Embedding操作封装了函数:
embedding = nn.Embedding(4,5) # 将0,1,2,3代表的词语转化为5维的tensor
embedding.weight.data = torch.arange(0,20).view(4,5)
input = torch.arange(3,-1,-1).long() # 依次输出3,2,1,0对应的词向量
output = embedding(input)
3. 损失函数
t.manual_seed(1000)
# batch_size=3,计算对应每个类别的分数(只有两个类别)
score = t.randn(3, 2)
# 三个样本分别属于1,0,1类,label必须是LongTensor
label = t.Tensor([1, 0, 1]).long()
# loss与普通的layer无差异
criterion = nn.CrossEntropyLoss()
loss = criterion(score, label)
loss
注意:
nn.MSELoss()要求batch_x与batch_y的tensor都是FloatTensor类型CrossEntropyLoss()要求batch_x为Float,batch_y为LongTensor类型
4. 其他类型的层
此外,nn下面还包括其他经常用到的层,例如:
-
Linear,全连接层 -
BatchNorm,批处理归一化层,包含风格迁移中常用的Instance BatchNorm,和Tranformer中常用的layer Normalization,使用方法如下:# 4 channel,初始化标准差为4,均值为0 bn = nn.BatchNorm1d(4) # 初始化BN层的标准差和均值 bn.weight.data = t.ones(4) * 4 bn.bias.data = t.zeros(4) h = t.randn(2,4) bn_out = bn(h) # 输出处理后的BN层均值和方差 # 方差是标准差的平方,计算无偏方差分母会减1 # 使用unbiased=False 分母不减1 bn_out.mean(0), bn_out.var(0, unbiased=False) # 均值 和 有偏方差 -
激活函数,
relu = nn.ReLU(inplace=True),inplace可以节省显存,但是慎重使用inplace,只有类似于sigmoid()这种根据输出可以推算出反向传播的梯度的情况,才能使用inplace.
两种特殊Module
当前向神经网络的层数很多,需要将一些重复的模块进行打包,减少代码量,这里有两种特殊的Module可以实现这一功能,Sequential和ModuleList,前者可以直接输入参数,后者不能直接接收参数。
nn.Sequential
构造Sequential有三种方法:
# Sequential的三种写法
# 1st
net1 = nn.Sequential()
net1.add_module('conv', nn.Conv2d(3, 3, 3))
net1.add_module('batchnorm', nn.BatchNorm2d(3))
net1.add_module('activation_layer', nn.ReLU())
# 2cd
net2 = nn.Sequential(
nn.Conv2d(3, 3, 3),
nn.BatchNorm2d(3),
nn.ReLU()
)
# 3rd
from collections import OrderedDict # 有序字典
net3= nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(3, 3, 3)),
('bn1', nn.BatchNorm2d(3)),
('relu1', nn.ReLU())
]))
print('net1:', net1)
print('net2:', net2)
print('net3:', net3)
# 可根据名字或序号取出子module
net1.conv, net2[0], net3.conv1
上述三种方法中的(1)和 (3) 可以通过net.conv方便调用查看每一层,(2)只能通过序号调用查看。
nn.ModuleList
modellist = nn.ModuleList([nn.Linear(3,4), nn.ReLU(), nn.Linear(4,2)])
input = t.randn(1, 3)
for model in modellist:
input = model(input)
# 下面会报错,因为modellist没有实现forward方法
# output = modelist(input)
可见,之所以ModuleList不能直接传入参数,是因为内部没有实现forward函数。
此外,之所以不能用list代替ModuleList的原因是前者的参数不能被识别添加到网络的parameters中。
PyTorch中的优化器
PyTorch中所有优化方法的基类都是torch.optim.Optimizer
1. 优化器的基本使用方法
from torch import optim
optimizer = optim.SGD(params = net.parameters(),lr=1e-5)
optimizer.zero_grad()
input = t.randn(1,2,3,4)
output = net(input)
output.backward()
optimizer.step()
2. 针对网络不同部分设置不同学习率
optimizer = torch.optim.SGD(
[
{'params': net.features.parameters()},
{'params': net.classifier.parameters(),'lr':1e-2}
],lr = 1e-5
)
更加复杂的操作,例如只将两个全连接层设计较大的学习率,其余层的学习率较小
# 只为两个全连接层设置较大的学习率,其余层的学习率较小
special_layers = nn.ModuleList([net.classifier[0], net.classifier[3]])
special_layers_params = list(map(id, special_layers.parameters()))
base_params = filter(lambda p: id(p) not in special_layers_params,
net.parameters())
optimizer = torch.optim.SGD([
{'params': base_params},
{'params': special_layers.parameters(), 'lr': 0.01}
], lr=0.001 )
3. 在运行过程中调整学习率
两种方法:
- 比较naïve的想法,新建一个optimizer,这在torch中花销很小,但是对于Adam此类优化器会丢失动量信息,造成优化器不收敛;
- 修改
optimizer.param_groups中的学习率,不会丢失历史梯度信息,适合于Adam等涉及到momentum的优化器。
for param_group in optimizer.param_groups:
param_group['lr'] *= 0.1
其他
1. nn.Module对象和torch.functional的区别
nn中还有一个很常用的模块:nn.functional,nn中的大多数layer,在nn.functional中都有一个与之相对应的函数,例如激活函数和线性层等。
区别
nn.functional中的函数和nn.Module的主要区别在于,用nn.Module实现的layers是一个特殊的类,都是由class layer(nn.Module)定义,会自动提取可学习的参数。
而nn.functional中的函数更像是纯函数,由def function(input)定义。
使用习惯
如果模型有可学习的参数,最好用nn.Module,否则既可以使用nn.functional也可以使用nn.Module,二者在性能上没有太大差异,具体的使用取决于个人的喜好。
具体来讲:
- 如激活函数(ReLU、sigmoid、tanh),池化(MaxPool)等层由于没有可学习参数,则可以使用对应的functional函数代替;
- 对于卷积、全连接等具有可学习参数的网络建议使用
nn.Module。
特例:
- 虽然dropout操作也没有可学习操作,但**建议使用
nn.Dropout**而不是nn.functional.dropout,因为dropout在训练和测试两个阶段的行为有所差别,使用nn.Module对象能够通过model.eval操作加以区分。 - 推荐使用
nn.BatchNormal
案例
from torch.nn import functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = F.pool(F.relu(self.conv1(x)), 2)
x = F.pool(F.relu(self.conv2(x)), 2)
x = x.view(-1, 16 * 5 * 5)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
当然也可以使用nn.functional代替nn.Module对象,不过要手动将参数加入模型的参数列表中:
class MyLinear(nn.Module):
def __init__(self):
super(MyLinear, self).__init__()
self.weight = nn.Parameter(t.randn(3, 4)) # nn.functional 需要手动添加
self.bias = nn.Parameter(t.zeros(3))
def forward(self):
return F.linear(input, self.weight, self.bias)
2. 初始化策略
对于nn.Module中的初始化无需关心,但是当使用Parameter自定义参数时,torch.Tensor返回的是内存中的随机数,数值变化很大,容易造成溢出或者梯度消失,此时需要进行初始化,在PyTorch中有两种方法:
-
使用
torch.nn.init按照某种策略进行初始化nn.init.xavier_normal_(linear.weight) # 等价于 linear.weight.data.normal_(0, std) -
直接初始化
linear.weight.data.normal_(mean,std)
也可以对不同模块执行不同的初始化策略:
for name, params in net.named_parameters():
if name.find('linear') != -1:
# init linear
params[0] # weight
params[1] # bias
elif name.find('conv') != -1:
pass
elif name.find('norm') != -1:
pass
实践:搭建ResNet34
ResNet34的结构如图所示:

我们把每个shortcut的单元称作residual block
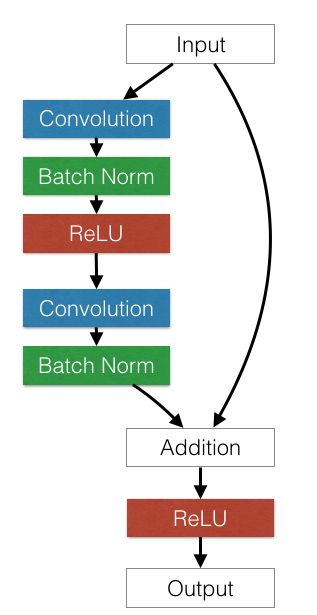
因为ResNet34拥有众多相似的残差块,所以我们使用nn.Sequential封装,对于重复模块使用子模块或者生成子模块的函数,使用nn.Module和nn.Functional结合实现。
import torch
from torch import nn
from torch.nn import functional as F
from torch.nn.modules.batchnorm import BatchNorm2d
class Residual_block(nn.Module):
def __init__(self,in_channels,out_channels,stride=1,shortcut=None):
super().__init__()
self.left = nn.Sequential(
nn.Conv2d(in_channels,out_channels,3,stride,1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels,out_channels,3,1,1),
nn.BatchNorm2d(out_channels)
)
self.right = shortcut
def forward(self,x):
out = self.left(x)
residual = x if self.right is None else self.right(x)
return F.relu(out+residual)
class ResNet34(nn.Module):
def __init__(self,num_classes=1000):
super().__init__()
self.pre = nn.Sequential(
nn.Conv2d(3,64,7,2,3,bias=False),
nn.ReLU(inplace=True),
nn.BatchNorm2d(64),
nn.MaxPool2d(3,2,1),
)
self.layer1 = self._make_layers(64,64,3)
self.layer2 = self._make_layers(64,128,4,stride=2)
self.layer3 = self._make_layers(128,256,6,stride=2)
self.layer4 = self._make_layers(256,512,3,stride=2)
self.fc = nn.Sequential(
nn.Linear(512,num_classes)
)
def _make_layers(self,in_channels,out_channels,num_layers,stride=1):
layers = nn.Sequential()
shortcut = nn.Sequential(
nn.Conv2d(in_channels,out_channels,1,stride,bias=False),
nn.BatchNorm2d(out_channels)
)
layers.add_module('type1',Residual_block(in_channels,out_channels,stride,shortcut))
for i in range(num_layers-1):
layers.add_module('type2',Residual_block(out_channels,out_channels))
return layers
def forward(self,x):
x = self.pre(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = F.max_pool2d(x,7)
x = x.view(x.size(0),-1)
return self.fc(x)
resnet34 = ResNet34()
input_data = torch.randn(1,3,224,224)
output = resnet34(input_data)