CVPR2020-PISA-目标检测prime采样新方法 | Prime Sample Attention in Object Detection
提出了新的目标检测训练采样方法,针对正负样本特性,提出了不同的排序方案
Github地址:https://github.com/open-mmlab/mmdetection.

总结来说:PISA= IoU-HLR对正样本排序 + Score-HLR对负样本排序 + CARL损失对分类回归损失关联
Abstract:
在目标检测框架中,将所有样本均等对待并以平均性能最大化为目标是一种常见的范例。在这项工作中,我们通过仔细研究不同样本如何对以mAP衡量的整体表现做出贡献的方式来重新研究此范例。我们的研究表明,每个mini-batch中的样本既不是独立的,也不是同等重要的,因此,更好的分类不一定会导致更高的mAP。出于本研究的动机,我们提出了“ Prime Samples”(主样本)的概念,这些概念在推动检测性能方面起着关键作用。我们进一步提出了一种简单而有效的采样和学习策略,称为PrIme Sample Attention(PISA),它将训练过程的重点转向为prime样本。我们的实验表明,训练检测器时,专注于Prime样本通常比Hard样本更有效。特别是,在MSCOCO数据集上,PISA的表现优于随机采样基准和难样本挖掘方案,例如OHEM和Focal loss,即使使用强大的骨架ResNeXt-101,在单级和两级检测器上也始终保持约2%的增益。
Introduction:
现有的训练采样的代表性方法包括OHEM 和Focal Loss 。其中, 前者明确选择难分样本,即具有高损失值的样本; 后者使用重塑后的损失函数对样本进行加权,从而强调了困难样本。
本文针对在训练目标检测器最重要的样本是什么? 这一问题进行了研究,目的是找到一种更有效的采样/加权区域方法。
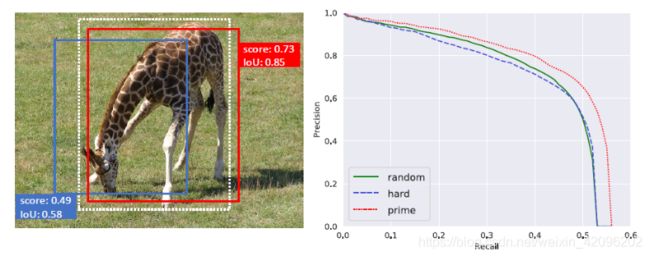
本文研究揭示了在设计采样策略时需要考虑的两个重要方面:
1)样本不应被视为独立的或同等重要的。 Region-Based目标检测器是从覆盖图像中的所有目标的大量候选目标中选择包bounding box的一小部分。 因此,对不同样本的决策彼此竞争,而不是相互独立(例如在分类任务中)。 通常,希望检测器在每个目标象周围的一个边界框上产生高分,同时确保所有感兴趣的目标都被充分覆盖,而不是尝试对所有正样本(即与对象基本重叠的样本)产生高分 。重点是,本文研究表明,关注那些与gt目标具有最高IoU的正样本是实现该目标的有效方法;
2)分类和定位的目标是相关的。 那些精确定位在gt物体周围的样本尤其重要,这一发现具有很强的含义,即分类的目的与定位的目的紧密相关。 特别是,定位良好的样本需要以高置信度进行良好分类。
受这项研究的启发,本文提出了PrIme Sample Attention(PISA),这是一种简单但有效的方法来对区域进行采样并学习目标检测器,在这里将那些在实现高检测性能中起更重要作用的样品称为prime(主要)样本。 将分层局部排序(HLR)定义为重要性指标。 具体来说,论文使用IoU-HLR对每个mini-batch中的正样本进行排序,用Score-HLR进行负样本排序。 这种排序策略将每个对象周围IoU最高的正样本和每个群集中得分最高的负样本放在排序列表的顶部,并通过简单的权重方案将训练过程的重点放在这些样本身上。此外,论文还设计了一种可识别分类的回归损失,以共同优化分类和回归分支。 特别是,这种损失将抑制那些回归损失较大的样本,从而加强对prime样本的关注。
因此本的主要贡献主要在于三个方面:
1)本文的研究使人们对什么样本对于训练目标检测器很重要有了新的认识,从而确立了prime样本的概念;
2)设计了分层局部排序(HLR)来对样本的重要性进行排名,并在此之上基于重要性的加权方案;
3)引入了一种称为分类感知回归损失的新损失,该损失可以同时优化分类和回归分支,从而进一步增强了对prime样本的关注。
Prime Samples:
A.mAP计算的启发:
揭示了两个标准,在这些标准上,正样本对于目标检测器更为重要。
1)在与gt目标重叠的所有边界框中,具有最高IoU的边界框最为重要,因为其IoU值直接影响召回率;
2)在所有针对不同目标的IoU最高的包围盒中,具有更高IoU的包围盒更为重要。
B.False Positives(FP):
FP的主要来源之一是将负样本误分类为正样本,这种误分类对精度有害,并且会降低mAP。 但是,并非所有错误分类的样本都直接影响最终结果。 在推断过程中,如果存在多个彼此严重重叠的负样本,则仅保留得分最高的样本,而其他样本将在非最大抑制(NMS)之后被丢弃。 这样,如果一个负样本接近另一个得分较高的样本,那么即使负样本的分数也可能很高,它也会变得不那么重要,因为它不会保留在最终结果中。 因此可以了解哪些负样本很重要:
1)在局部区域内的所有负样本中,得分最高的样本最为重要;
2)在所有区域中所有得分最高的样本中,得分较高的样本更为重要,因为它们是第一个降低精度的样本。
经过上述两个分析,可以发现,影响目标检测训练的正样本主要是IOU较高的这些样本,负样本则是分类得分较高的样本。
C.Hierarchical Local Rank (HLR)
主要提出了IoU分层局部排序(IoU-HLR)和分层局部得分排序(Score-HLR),分别针对mini-batch中正样本和负样本的重要性进行排序。
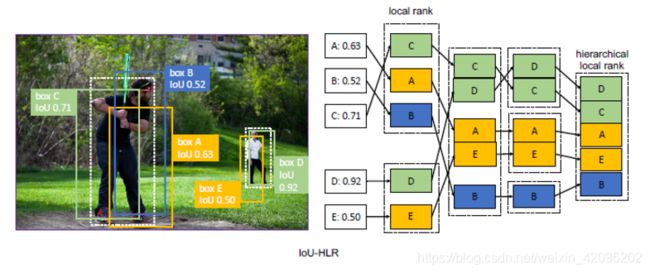
IoU-HLR:如上图所示。为了计算IoU-HLR,首先将所有样本根据其最近的gt目标划分为不同的组。接下来,使用与gt的IoU降序对每个组中的样本进行排序,并获得IoU局部排名(IoU-LR)。随后,以相同的IoU-LR采样并按降序对其进行排序。具体来说,收集并分类所有top1 IoU-LR样本,其次是top2,top3,依此类推。这两个步骤将对所有样本进行排序。

Score-HLR:以类似于IoU-HLR的方式计算负样本的Score-HLR。 与由每个gt目标自然分组的正样本不同,负样本也可能出现在背景区域,因此我们首先使用NMS将它们分组到不同的群集中。 将所有前景类别中的最高分数用作负样本的得分,然后执行与计算IoU-HLR相同的步骤。
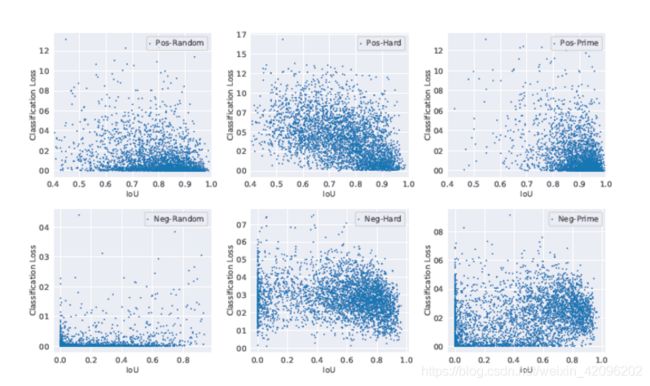
论文还对比分析了随机样本,hard样本和prime样本的分布情况以及IoU与分类损失的关系。如上图所示, 可以观察到,hard正样本倾向于具有较高的分类损失,并沿IoU轴在较大范围内分散,而prime正样本倾向于具有较高的IoU和较低的分类损失。 hard负样本往往具有较高的分类损失和较高的IoU,而prime负样本也包括一些低损失样本,并且IoU分布更为分散。 这表明这两类样本具有本质上不同的特征。
Learn Detectors via Prime Sample Attention:
由上面介绍可知,目标检测的目的是要在集合中的prime样本上实现尽可能好的性能。但是,如果论文像OHEM一样使用top IoU-HLR样本进行训练,则mAP将会显着下降。这是因为大多数prime样本都是简单样本,并且无法提供足够的梯度来优化分类器。
本文提出了PrIme Sample Attention,这是一种简单有效的采样和学习策略,它更加关注prime样本。 PISA由两个部分组成:基于重要性的样本重加权(ISR)和分类感知回归损失(CARL)。可以在训练过程偏向于prime样本,而不是均匀地对待所有样本。首先,prime样本的损失权重比其他样本大,因此分类器倾向于在这些样本上更准确。其次,分类器和回归器是通过联合目标学习的,因此相对于不重要的样本,正样本数的得分得到了提高。
A.Importance-based Sample Reweighting(ISR)
给定相同的分类器,性能分布通常与训练样本的分布相匹配。 如果部分样本在训练数据中更频繁地出现,则应该获得对这些样本的更好分类精度。 hard采样和soft采样是更改训练数据分布的两种不同方式。 hard采样从所有候选项中选择一个样本子集来训练模型,而soft采样为所有样本分配不同的权重。 hard采样可以看作是软采样的一种特殊情况,其中为每个采样分配的损失权重为0或1。
本文提出了一种名为基于重要性的样本重加权(ISR)的soft采样策略,该策略根据重要性为样本分配不同的损失权重。 ISR由正样本重加权和负样本重加权组成,分别表示为ISR-P和ISR-N。 对于正样本,采用IoU-HLR作为重要性度量;对于负样本,采用Score-HLR。具体来说:
1)排序ri映射到重要性ui,对于HLR中的每个类别中的样本个数nj和对的HLR (分层局部排序)r,使用线性函数将每个ri转换为ui,如等式1所示:
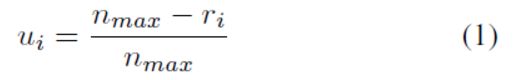
这里ui表示类别j的第i个样本的重要性值。 nmax表示所有类别上nj的最大值,这确保了在不同类别的相同排序上的样本将被分配相同的ui。
2)样本重要性ui转换为损失权重wi,采用等式2中的指数形式,其中的度数因子y表示将对prime样本给予多少优先权,并且beta是决定最小样本权重的偏差。
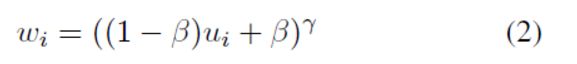
3)重写交叉熵分类损失,其中n和m是正样本和负样本的数量; s和ˆs分别表示预测分数和分类目标。 请注意,简单地增加损失权重将改变损失的总价值以及正负样本损失之间的比率,因此将w标准化为w’,以保持总损失不变。

B.Classification-Aware Regression Loss(CARL)
之前论文讨论过分类和定位具有相关联的关系。本文进一步提出使用分类感知回归损失(CARL)共同优化两个分支。 CARL可以提高prime样本的分数,同时抑制其他样本的分数。 回归质量决定了样本的重要性,我们期望分类器为重要样本输出更高的分数。 两个分支的优化应该相关而不是独立。
具体解决方案是添加可识别分类的回归损失,以便将梯度从回归分支传播到分类分支。 为此,本文提出了如式4所示的CARL。 pi表示相应的gt类别的预测概率,而di表示输出回归偏移。使用指数函数将pi转换为vi,然后根据所有样本的平均值对其进行重新缩放。 L是常用的平滑L1损失。
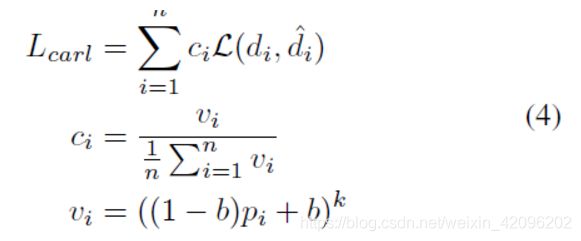
应用CARL的好处:具有更大回归损失的样本将获得较大的分类分数梯度,这意味着对分类分数的抑制作用更强。 在另一种观点中,L(di,ˆ di)反映了样本i的定位质量,因此可以看作是IoU的估计,并且还可以看作是IoU-HLR的估计。 排名靠前的样本大约具有较低的回归损失,因此分类得分的梯度较小。 使用CARL,分类分支将受到回归损失的监督。 不重要的样本的分数被大大抑制,同时加强了对prime样本的关注。
Experiments:
1.COCO:

2.VOC:
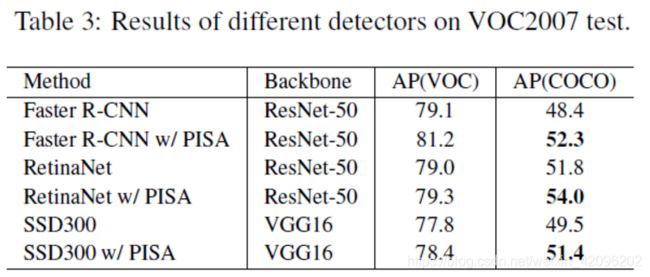
3.model effect:
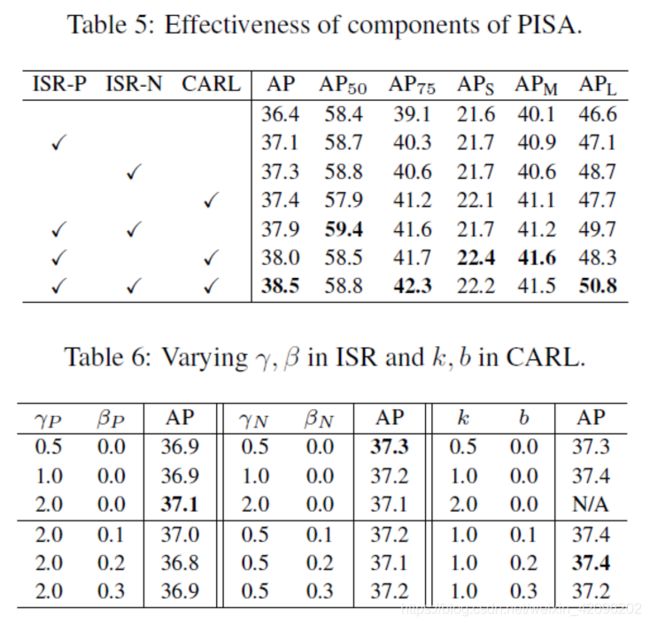
4.与现有采样方法对比:random sampling (R),hard mining (H),PISA (P)
