arXiv-2021-TrTr: Visual Tracking with Transformer 阅读笔记
论文地址:
https://arxiv.org/abs/2105.03817
代码地址:
https://github.com/tongtybj/TrTr
创新点:
本文中提出了一种新的跟踪器网络,它基于一种强大的注意力机制,称为变压器编码器-解码器架构,以获得全局和丰富的上下文相关性。
一、 动机
基于相关滤波的跟踪方法和基于孪生网络的跟踪方法都利用从模板和搜索图像中提取的特征之间的互相关运算来预测在搜索图像中每个空间位置的出现概率,用于目标定位。但由于一般的互相关操作只能获得模板中的局部小块与搜索图像之间的关系,不能执行全局成对交互,这使得难以精确跟踪具有大的外观变化、近距离干扰物或遮挡的目标对象。这项工作介绍了一种新的跟踪任务的网络架构,它利用变压器编码器-解码器架构来执行目标分类和包围盒回归。在这种称为TrTr的新跟踪器中,执行模板和搜索图像特征的自关注以及这些特征之间的交叉关注,以计算全局和丰富的上下文相关性,从而导致更准确和稳定的跟踪。
二、 主要贡献
① 介绍了用于目标视觉跟踪任务的Transformer编码器-解码器架构,其中从模板和搜索图像中提取的特征图之间的显式互相关被自我和交叉注意操作所取代,以获得全局和丰富的上下文相关性。
② 基于置信度的目标分类头和基于形状不可知锚的目标回归头是为我们的基于变换的架构开发的;同时设计了用于分类的插件式在线更新模块,以进一步提高跟踪性能。
③ 在包括VOT、OTB、UAV、NfS、LaSOT和TrackingNet在内的大规模基准数据集上进行了全面的实验,该追踪器在以实时速度运行时取得了与最先进结果相比良好的性能,这表明了Transformer架构在追踪任务中的巨大潜力。
三、 主要内容
算法架构:
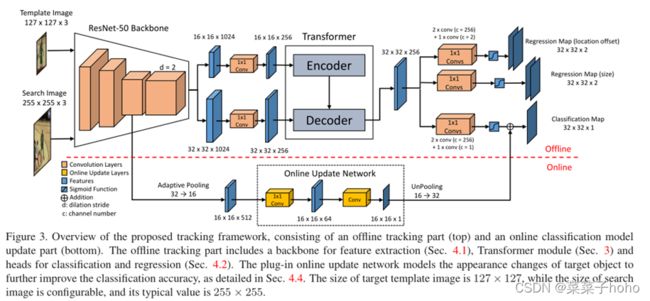
它包含两个部分:基于Transformer的离线模型和仅用于分类的在线更新模型。
3.1基于Transformer的离线模型
3.1.1特征提取
3.1.1.1 ResNet-50
将一对模板图像和搜索图像作为输入,通常搜索图像较大。然后经过修改的ResNet-50主干提取特征。其中,ResNet-50只使用前四阶段,并且在第四阶段,下采样单元的卷积步长从2修改为1,以增加特征图的空间尺寸,同时,所有的3 × 3卷积都用步长为2的扩张卷积来增加感受野。然后,来自主干的特征通过1 × 1卷积层,以将通道数从1024降低到256,为后续Transformer模块的节省计算成本。
3.1.1.2 Transformer
TrTr跟踪器中通过使用Transformer,用多头自我和编码器-解码器注意机制来代替孪生网络中的互相关操作。Transformer模型只包含一个用于编码器和解码器的层。在模型中,使用8个头用于多头注意力模块(M = 8),并将FFN隐藏层的通道维度设置为8d。
TrTr跟踪器中的Transformer架构:

具体过程解释图:
3.1.2目标定位
为了定位目标和估计形状应用不可知锚(shape-agnostic anchor)。Transformer模块的输出分别连接三个独立的头,其中一个头用于分类,另外两个用于回归。每个头部包含三个1 × 1卷积层,后跟一个Sigmoid层。分类头产生映射Y∈〖[0,1]〗(⌊H/s⌋×⌊W/s⌋×1),其中H,W是搜索图像的高度和宽度,s是输出步幅(即8)。向下取整函数决定了输出结果为32。映射Y对应离散化低分辨率下目标的出现概率。因此,为了恢复由输出步距s引起的离散化误差,有必要另外预测局部偏移O∈〖[0,1)〗(⌊H/s⌋×⌊W/s⌋×2)。该过程由用于回归的一个头来完成。那么目标对象在搜索图像中的中心点可以由下式给出:
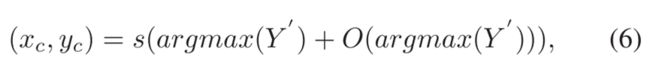
其中Y’是原始图Y与余弦窗口的组合,以抑制大位移。argmax(Y′)返回与映射Y′的顶点相对应的二维坐标。
另一个回归头用于尺寸回归,该头产生归一化的图S∈〖[0,1]〗^(⌊H/s⌋×⌊W/s⌋×2).然后,搜索图像中边界框的大小可以由下式给出:

其中∫是逐元素乘法运算。进一步应用线性插值更新策略来平滑边界框尺寸的变化。最后,从目标中心点(xc,yc)和尺寸(wbb,hbb)可以容易地计算出边界框。
3.1.3损失计算
对于真实边界框的中心p ̅,首先计算一个低分辨率p ̃=(⌊p ̅_x/s⌋,⌊p ̅_y/s⌋)。然后,我们使用高斯核Y ̅与预测图Y进行比较,其中σ_p是对象大小自适应标准偏差。

分类的训练目标是具有焦点损失的惩罚减少的逐像素逻辑回归:
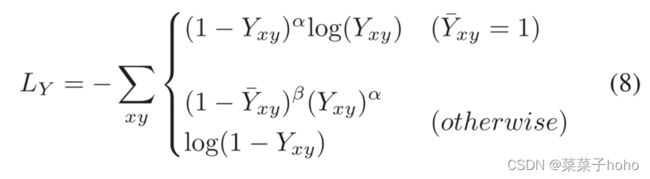
其中Yxy是映射Y在(x,y)处的值。α和β是焦损失的超参数。实验中使用α = 2和β = 4。
然后,使用L1损失来公式化偏移回归的损失函数:
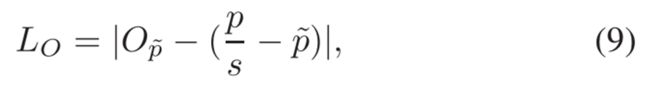
其中,O_p ̃ 是O在p ̃处的映射值。
对于真实边界框大小(w ̅_bb,h ̅_bb),也使用L1损失:

其中,S_p ̃ 是S在p ̃处的映射值,s ̃ =(w ̅_bb/W,h ̅_bb/H),是归一化后的真实边界框大小。最后,整个网络的联合培训目标可由下式给出:

其中λ1和λ2是权重超参,简单地设λ1 =λ2 = 1。
3.2仅用于分类的在线更新模型
3.2.1集成分类的在线更新
TrTr中设计了一种在线更新模型,用于独立捕捉目标物体在跟踪过程中的外观变化。如图3的底部所示,这个在线分支直接使用来自主干网络的第一个第三级的输出,并生成映射Y_online∈〖[0,1]〗^(⌊H/s⌋×⌊W/s⌋×1)。该分支由两层全卷积神经网络组成,其中第一层1 × 1卷积层将信道维数降低到64,第二层采用4 × 4内核,单输出通道。在推理过程中,应用快速共轭梯度算法来训练该在线网络。由离线分类头和在线分支估计的映射图被加权为:
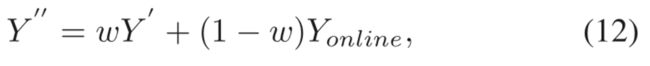
其中w表示权重超参数,在我们的实验中设置为0.6。当在线更新模型可用时,使用组合分类图Y’’而不是(6)和(7)中的Y’。
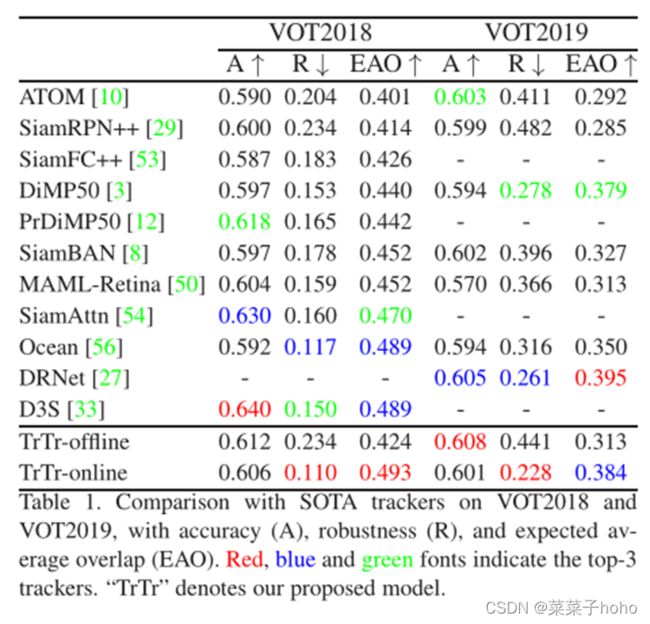
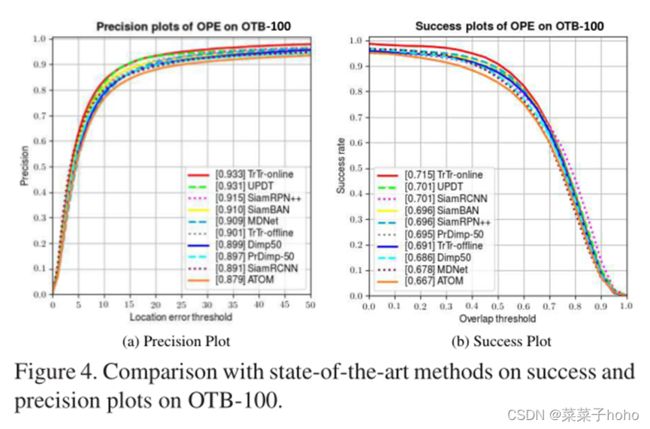
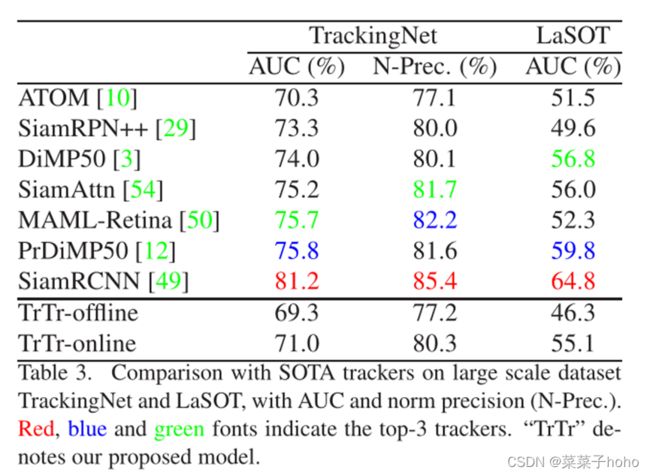
四、 实验结果
训练数据集:Youtube-BB, ImageNet VID, GOT-10k, LaSOT, COCO
评测数据集:VOT2018 & VOT2019、OTB100、UAV123、NfS、TrackingNet、LaSOT
离线模型的跟踪速度为50 FPS,如果集成在线更新模型,将降低到35 FPS。