轻量化网络——ghostnet代码讲解
背景
神经网络在移动设备上的应用还亟待解决,主要原因是现有模型又大又慢。因而,一些研究提出了模型的压缩方法,比如剪枝、量化、知识蒸馏等;还有一些则着重于高效的网络结构设计,比如MobileNet,ShuffleNet等。本文就设计了一种全新的神经网络基本单元Ghost模块,从而搭建出轻量级神经网络架构GhostNet。
在一个训练好的深度神经网络中,通常会包含丰富甚至冗余的特征图,以保证对输入数据有全面的理解。如下图所示,在ResNet-50中,将经过第一个残差块处理后的特征图拿出来,三个相似的特征图对示例用相同颜色的框注释。 该对中的一个特征图可以通过廉价操作(用扳手表示)将另一特征图变换而获得,可以认为其中一个特征图是另一个的“幻影”。因为,本文提出并非所有特征图都要用卷积操作来得到,“幻影”特征图可以用更廉价的操作来生成。
Ghost Module

如上图左边是传统卷积,右边是Ghost模块,作者认为深度卷积神经网络通常引用由大量卷积组成的卷积神经网络,导致大量的计算成本。尽管最近的工作,例如MobileNet和ShuffleNet引入了深度卷积或混洗操作,以使用较小的卷积核(浮点运算)来构建有效的CNN,其余 1x1 卷积层仍将占用大量内存和FLOPs。
代码实现
class GhostModule(nn.Module):
def __init__(self, inp, oup, kernel_size=1, ratio=2, dw_size=3, stride=1, relu=True):
super(GhostModule, self).__init__()
self.oup = oup
init_channels = math.ceil(oup / ratio)
new_channels = init_channels*(ratio-1)
self.primary_conv = nn.Sequential(
nn.Conv2d(inp, init_channels, kernel_size, stride, kernel_size//2, bias=False),
nn.BatchNorm2d(init_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
self.cheap_operation = nn.Sequential(
nn.Conv2d(init_channels, new_channels, dw_size, 1, dw_size//2, groups=init_channels, bias=False),
nn.BatchNorm2d(new_channels),
nn.ReLU(inplace=True) if relu else nn.Sequential(),
)
def forward(self, x):
x1 = self.primary_conv(x)
x2 = self.cheap_operation(x1)
out = torch.cat([x1,x2], dim=1)
return out[:,:self.oup,:,:]
通过分析代码可以看出,self.primary_conv先对输入进行1x1卷积,得到x1,x1的通道数是原来的一半,之后在进行深度可分离卷积,输出值为x2,输出通道数同样是x的通道数的一半,然后x1和x2 在通道上进行堆叠。
什么是深度可分离呢?
Ghost Bottleneck
Ghost Bottleneck:利用Ghost模块的优势,作者介绍了专门为小型CNN设计的Ghost bottleneck(G-bneck)。如下图所示,Ghost bottleneck似乎类似于ResNet中的基本残差块(Basic Residual Block),其中集成了多个卷积层和shortcut。Ghost bottleneck主要由两个堆叠的Ghost模块组成。第一个Ghost模块用作扩展层,增加了通道数。这里将输出通道数与输入通道数之比称为expansion ratio。第二个Ghost模块减少通道数,以与shortcut路径匹配。然后,使用shortcut连接这两个Ghost模块的输入和输出。这里借鉴了MobileNetV2,第二个Ghost模块之后不使用ReLU,其他层在每层之后都应用了批量归一化(BN)和ReLU非线性激活。上述Ghost bottleneck适用于stride= 1,对于stride = 2的情况,shortcut路径由下采样层和stride = 2的深度卷积(Depthwise Convolution)来实现。出于效率考虑,Ghost模块中的初始卷积是点(1x1)卷积(Pointwise Convolution)。

代码实现
class GhostNet(nn.Module):
def __init__(self, cfgs, num_classes=1000, width=1.0, dropout=0.2):
super(GhostNet, self).__init__()
# setting of inverted residual blocks
self.cfgs = cfgs
self.dropout = dropout
# building first layer
output_channel = _make_divisible(16 * width, 4)
self.conv_stem = nn.Conv2d(3, output_channel, 3, 2, 1, bias=False)
self.bn1 = nn.BatchNorm2d(output_channel)
self.act1 = nn.ReLU(inplace=True)
input_channel = output_channel
# building inverted residual blocks
stages = []
block = GhostBottleneck
for cfg in self.cfgs:
layers = []
for k, exp_size, c, se_ratio, s in cfg:
output_channel = _make_divisible(c * width, 4)
hidden_channel = _make_divisible(exp_size * width, 4)
layers.append(block(input_channel, hidden_channel, output_channel, k, s,
se_ratio=se_ratio))
input_channel = output_channel
stages.append(nn.Sequential(*layers))
output_channel = _make_divisible(exp_size * width, 4)
stages.append(nn.Sequential(ConvBnAct(input_channel, output_channel, 1)))
input_channel = output_channel
self.blocks = nn.Sequential(*stages)
# building last several layers
output_channel = 1280
self.global_pool = nn.AdaptiveAvgPool2d((1, 1))
self.conv_head = nn.Conv2d(input_channel, output_channel, 1, 1, 0, bias=True)
self.act2 = nn.ReLU(inplace=True)
self.classifier = nn.Linear(output_channel, num_classes)
def forward(self, x):
x = self.conv_stem(x)
x = self.bn1(x)
x = self.act1(x)
x = self.blocks(x)
x = self.global_pool(x)
x = self.conv_head(x)
x = self.act2(x)
x = x.view(x.size(0), -1)
if self.dropout > 0.:
x = F.dropout(x, p=self.dropout, training=self.training)
x = self.classifier(x)
return x
def ghostnet(**kwargs):
"""
Constructs a GhostNet model
"""
cfgs = [
# k, t, c, SE, s
# stage1
[[3, 16, 16, 0, 1]],
# stage2
[[3, 48, 24, 0, 2]],
[[3, 72, 24, 0, 1]],
# stage3
[[5, 72, 40, 0.25, 2]],
[[5, 120, 40, 0.25, 1]],
# stage4
[[3, 240, 80, 0, 2]],
[[3, 200, 80, 0, 1],
[3, 184, 80, 0, 1],
[3, 184, 80, 0, 1],
[3, 480, 112, 0.25, 1],
[3, 672, 112, 0.25, 1]
],
# stage5
[[5, 672, 160, 0.25, 2]],
[[5, 960, 160, 0, 1],
[5, 960, 160, 0.25, 1],
[5, 960, 160, 0, 1],
[5, 960, 160, 0.25, 1]
]
]
return GhostNet(cfgs, **kwargs)
class GhostBottleneck(nn.Module):
""" Ghost bottleneck w/ optional SE"""
def __init__(self, in_chs, mid_chs, out_chs, dw_kernel_size=3,
stride=1, act_layer=nn.ReLU, se_ratio=0.):
super(GhostBottleneck, self).__init__()
has_se = se_ratio is not None and se_ratio > 0.
self.stride = stride
# Point-wise expansion (1x1)
self.ghost1 = GhostModule(in_chs, mid_chs, relu=True)
# Depth-wise convolution
if self.stride > 1:
self.conv_dw = nn.Conv2d(mid_chs, mid_chs, dw_kernel_size, stride=stride,
padding=(dw_kernel_size-1)//2,
groups=mid_chs, bias=False)
self.bn_dw = nn.BatchNorm2d(mid_chs)
# Squeeze-and-excitation
if has_se:
self.se = SqueezeExcite(mid_chs, se_ratio=se_ratio)
else:
self.se = None
# Point-wise linear projection
self.ghost2 = GhostModule(mid_chs, out_chs, relu=False)
# shortcut
if (in_chs == out_chs and self.stride == 1):
self.shortcut = nn.Sequential()
else:
self.shortcut = nn.Sequential(
nn.Conv2d(in_chs, in_chs, dw_kernel_size, stride=stride,
padding=(dw_kernel_size-1)//2, groups=in_chs, bias=False),
nn.BatchNorm2d(in_chs),
nn.Conv2d(in_chs, out_chs, 1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_chs),
)
def forward(self, x):
residual = x
# 1st ghost bottleneck
x = self.ghost1(x)
# Depth-wise convolution
if self.stride > 1:
x = self.conv_dw(x)
x = self.bn_dw(x)
# Squeeze-and-excitation
if self.se is not None:
x = self.se(x)
# 2nd ghost bottleneck
x = self.ghost2(x)
x += self.shortcut(residual)
return x
其实引用将所有的内容说明了一切,里面的信息量很大 !
GhostNet
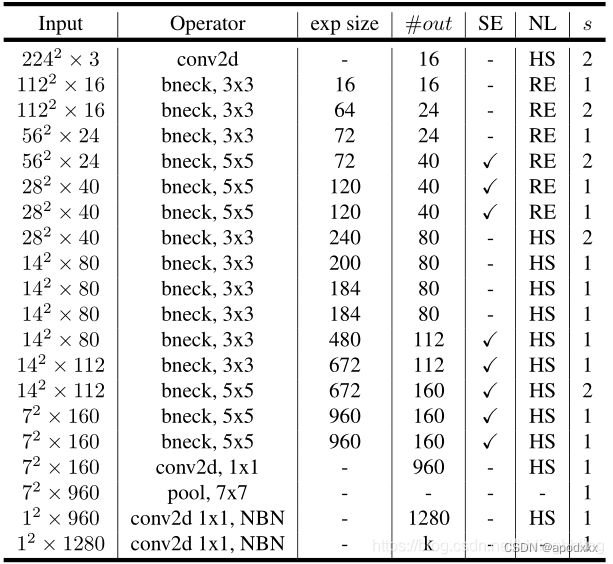
基于Ghost bottleneck,作者提出GhostNet。作者遵循MobileNetV3的基本体系结构的优势,然后使用Ghost bottleneck替换MobileNetV3中的bottleneck。GhostNet主要由一堆Ghost bottleneck组成,其中Ghost bottleneck以Ghost模块为构建基础。第一层是具有16个卷积核的标准卷积层,然后是一系列Ghost bottleneck,通道逐渐增加。这些Ghost bottleneck根据其输入特征图的大小分为不同的阶段。除了每个阶段的最后一个Ghost bottleneck是stride = 2,其他所有Ghost bottleneck都以stride = 1进行应用。最后,利用全局平均池和卷积层将特征图转换为1280维特征向量以进行最终分类。SE模块也用在了某些Ghost bottleneck中的残留层,如表1中所示。与MobileNetV3相比,这里用ReLU换掉了Hard-swish激活函数。尽管进一步的超参数调整或基于自动架构搜索的Ghost模块将进一步提高性能,但表1所提供的架构提供了一个基本设计参考。

下面是mobileNet V3网络
实验效果

总结
为了减少最新的深度神经网络的计算成本,本文提出了一种用于构建高效的神经网络结构的新型Ghost模块。Ghost模块将原始卷积层分为两部分,首先使用较少的卷积核来生成原始特征图,然后,进一步使用廉价变换操作以高效生产更多幻影特征图。在基准模型和数据集上进行的实验表明,该方法是一个即插即用的模块,能够将原始模型转换为更紧凑的模型,同时保持可比的性能。此外,在效率和准确性方面,使用提出的新模块构建的GhostNet均优于最新的轻量神经网络,如MobileNetV3。
代码地址:
论文地址
官方代码地址
模型官方讲解