paddle 学习总结与使用指南 笔记(一)
简单的一个手写字识别任务。
import paddle
import numpy as np
from paddle.vision.transforms import Normalize
# 定义图像归一化处理方法,这里的CHW指图像格式需为 [C通道数,H图像高度,W图像宽度]
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# 下载数据集并初始化 DataSet
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
# 模型组网并初始化网络
lenet = paddle.vision.models.LeNet(num_classes=10)
model = paddle.Model(lenet)
# 模型训练的配置准备,准备损失函数,优化器和评价指标
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 模型训练
model.fit(train_dataset, epochs=5, batch_size=64, verbose=1)
# 模型评估
model.evaluate(test_dataset, batch_size=64, verbose=1)
# 保存模型
model.save('./output/mnist')
# 加载模型
model.load('output/mnist')
# 从测试集中取出一张图片
img, label = test_dataset[0]
# 将图片shape从1*28*28变为1*1*28*28,增加一个batch维度,以匹配模型输入格式要求
img_batch = np.expand_dims(img.astype('float32'), axis=0)
# 执行推理并打印结果,此处predict_batch返回的是一个list,取出其中数据获得预测结果
out = model.predict_batch(img_batch)[0]
pred_label = out.argmax()
print('true label: {}, pred label: {}'.format(label[0], pred_label))
# 可视化图片
from matplotlib import pyplot as plt
plt.imshow(img[0])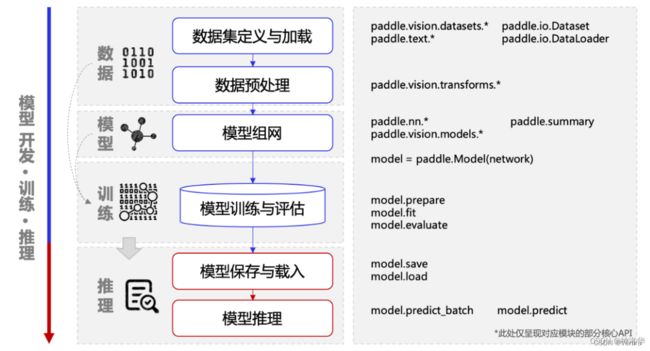
简单地说,深度学习任务一般分为以下几个核心步骤:
- 数据集定义与加载
- 模型组网
- 模型训练与评估
- 模型推理
接下来逐个步骤介绍,帮助你快速掌握使用飞桨框架实践深度学习任务的方法。
1.1 数据集定义
飞桨已经内置了一些数据集,包括:
- paddle.vision.datasets :内置了计算机视觉(Computer Vision,CV)领域常见的数据集,
- paddle.text: 内置了自然语言处理(Natural Language Processing,NLP)领域常见的数据集。
从打印结果可以看到飞桨内置了:
- CV 领域的 MNIST、FashionMNIST、Flowers、Cifar10、Cifar100、VOC2012 数据集
- NLP 领域的 Conll05st、Imdb、Imikolov、Movielens、UCIHousing、WMT14、WMT16 数据集。
可以使用代码实现
import paddle
print('计算机视觉(CV)相关数据集:', paddle.vision.datasets.__all__)
print('自然语言处理(NLP)相关数据集:', paddle.text.__all__)计算机视觉(CV)相关数据集: ['DatasetFolder', 'ImageFolder', 'MNIST', 'FashionMNIST', 'Flowers', 'Cifar10', 'Cifar100', 'VOC2012']
自然语言处理(NLP)相关数据集: ['Conll05st', 'Imdb', 'Imikolov', 'Movielens', 'UCIHousing', 'WMT14', 'WMT16', 'ViterbiDecoder', 'viterbi_decode']在本任务中,内置的 MNIST 数据集已经划分好了训练集和测试集,通过 mode 字段传入 ‘train’ 或 ‘test’ 来区分。
1.2 数据集加载
1.2.1 直接加载内置数据集
paddle内置的经典数据集可直接调用:
import paddle
from paddle.vision.transforms import Normalize
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# 下载数据集并初始化 DataSet
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
# 打印数据集里图片数量
print('{} images in train_dataset, {} images in test_dataset'.format(len(train_dataset), len(test_dataset)))60000 images in train_dataset, 10000 images in test_dataset完成数据集初始化之后,可以使用下面的代码直接对数据集进行迭代读取。
from matplotlib import pyplot as plt
for data in train_dataset:
image, label = data
print('shape of image: ',image.shape)
plt.title(str(label))
plt.imshow(image[0])
breakshape of image: (1, 28, 28) 
另外还有 paddle.vision.transforms ,提供了一些常用的图像变换操作,如对图像进行中心裁剪、水平翻转图像和对图像进行归一化等。这里在初始化 MNIST 数据集时传入了 Normalize 变换对图像进行归一化,对图像进行归一化可以加快模型训练的收敛速度。
1.2.2 自定义读取数据集
参考:数据集定义与加载、数据预处理
paddle.io.Dataset 和 paddle.io.DataLoader :自定义数据集与加载功能API
1.3 定义模型
1.3.1 内置模型
paddle.vision.models :内置了 CV 领域的一些经典模型,比如LeNe,一行代码即可完成 LeNet 的网络构建和初始化,num_classes 字段中定义分类的类别数。
1.3.2 打印模型信息
通过 paddle.summary 可方便地打印网络的基础结构和参数信息。
# 模型组网并初始化网络
lenet = paddle.vision.models.LeNet(num_classes=10)
# 可视化模型组网结构和参数
paddle.summary(lenet,(1, 1, 28, 28))
---------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===========================================================================
Conv2D-1 [[1, 1, 28, 28]] [1, 6, 28, 28] 60
ReLU-1 [[1, 6, 28, 28]] [1, 6, 28, 28] 0
MaxPool2D-1 [[1, 6, 28, 28]] [1, 6, 14, 14] 0
Conv2D-2 [[1, 6, 14, 14]] [1, 16, 10, 10] 2,416
ReLU-2 [[1, 16, 10, 10]] [1, 16, 10, 10] 0
MaxPool2D-2 [[1, 16, 10, 10]] [1, 16, 5, 5] 0
Linear-1 [[1, 400]] [1, 120] 48,120
Linear-2 [[1, 120]] [1, 84] 10,164
Linear-3 [[1, 84]] [1, 10] 850
===========================================================================
Total params: 61,610
Trainable params: 61,610
Non-trainable params: 0
---------------------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.11
Params size (MB): 0.24
Estimated Total Size (MB): 0.35
---------------------------------------------------------------------------
{'total_params': 61610, 'trainable_params': 61610}1.3.3 自定义神经网络
通过飞桨的 paddle.nn.Sequential 和 paddle.nn.Layer API 可以更灵活方便的组建自定义的神经网络,详细使用方法可参考『模型组网』章节。
1.4 模型训练与评估
参考《模型训练、评估与推理》
1.4.1 优化器、模型训练
模型训练需完成如下步骤:
-
使用 paddle.Model 封装模型。 将网络结构组合成可快速使用 飞桨高层 API 进行训练、评估、推理的实例,方便后续操作。
-
使用 paddle.Model.prepare 完成训练的配置准备工作。 包括:
- paddle.optimizer :优化器算法相关 API
- paddle.nn Loss: 损失函数相关 API
- paddle.metric :评价指标相关 API。
-
使用 paddle.Model.fit 配置循环参数并启动训练。 配置参数包括指定训练的数据源 train_dataset、训练的批大小 batch_size、训练轮数 epochs 等,执行后将自动完成模型的训练循环。
因为是分类任务,这里损失函数使用常见的 CrossEntropyLoss (交叉熵损失函数),优化器使用 Adam,评价指标使用 Accuracy 来计算模型在训练集上的精度。
# 封装模型,便于进行后续的训练、评估和推理
model = paddle.Model(lenet)
# 模型训练的配置准备,准备损失函数,优化器和评价指标
model.prepare(paddle.optimizer.Adam(parameters=model.parameters()),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy())
# 开始训练
model.fit(train_dataset, epochs=5, batch_size=64, verbose=1)输出:
The loss value printed in the log is the current step, and the metric is the average value of previous steps.
Epoch 1/5
step 938/938 [==============================] - loss: 0.0011 - acc: 0.9865 - 14ms/step
Epoch 2/5
step 938/938 [==============================] - loss: 0.0045 - acc: 0.9885 - 14ms/step
Epoch 3/5
step 938/938 [==============================] - loss: 0.0519 - acc: 0.9896 - 14ms/step
Epoch 4/5
step 938/938 [==============================] - loss: 4.1989e-05 - acc: 0.9912 - 14ms/step
Epoch 5/5
step 938/938 [==============================] - loss: 0.0671 - acc: 0.9918 - 15ms/step
1.4.2 模型评估
模型训练完成之后,调用 paddle.Model.evaluate ,来评估训练好的模型效果。
# 进行模型评估
model.evaluate(test_dataset, batch_size=64, verbose=1)
Eval begin...
step 157/157 [==============================] - loss: 5.7177e-04 - acc: 0.9859 - 6ms/step
Eval samples: 10000
{'loss': [0.00057177414], 'acc': 0.9859}1.5 模型保存、加载、推理
参考:模型保存与加载、模型训练、评估与推理
1.5.1 模型保存
调用 paddle.Model.save 保存模型:
# 保存模型,文件夹会自动创建
model.save('./output/mnist')以上代码执行后会在output目录下保存两个文件,mnist.pdopt为优化器的参数,mnist.pdparams为模型的参数。
output
├── mnist.pdopt # 优化器的参数
└── mnist.pdparams # 模型的参数每个epoch保存一次模型:
import os
data_dir='./output'
model.save(os.path.join(data_dir,'mnist_',str(epoch)))
1.5.2 加载模型并推理
可调用 paddle.Model.load 加载模型,然后即可通过 paddle.Model.predict_batch 执行推理操作:
# 加载模型
model.load('output/mnist')
# 从测试集中取出一张图片
img, label = test_dataset[0]
# 将图片shape从1*28*28变为1*1*28*28,增加一个batch维度,以匹配模型输入格式要求
img_batch = np.expand_dims(img.astype('float32'), axis=0)
# 执行推理并打印结果,此处predict_batch返回的是一个list,取出其中数据获得预测结果
out = model.predict_batch(img_batch)[0]
pred_label = out.argmax()
print('true label: {}, pred label: {}'.format(label[0], pred_label))
# 可视化图片
from matplotlib import pyplot as plt
plt.imshow(img[0])
输出:
true label: 7, pred label: 7 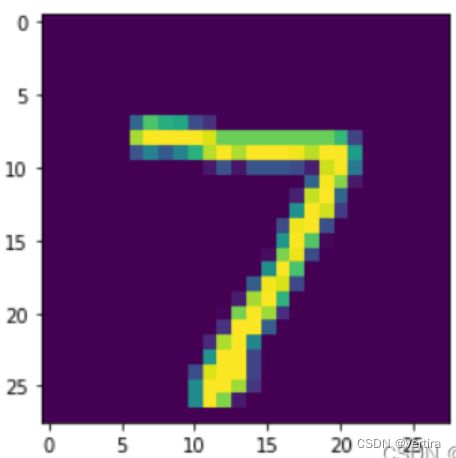
二、Tensor
参考《Tensor介绍》、 paddle.Tensor API 文档
飞桨使用张量(Tensor) 来表示神经网络中传递的数据,Tensor 可以理解为多维数组,类似于 Numpy 数组(ndarray) 的概念。在飞桨框架中,神经网络的输入、输出数据,以及网络中的参数均采用 Tensor 数据结构。
2.1 Tensor 的创建
2.1.1 指定数据创建
通过给定 Python 序列(如列表 list、元组 tuple),使用 paddle.to_tensor 创建任意维度的 Tensor:
import paddle
x=paddle.to_tensor(2)
y= paddle.to_tensor([[1.0, 2.0, 3.0],
[4.0, 5.0, 6.0]])
tensor_temp = paddle.to_tensor(np.array([1.0, 2.0]))
print(x,y)Tensor(shape=[1], dtype=int64, place=Place(cpu), stop_gradient=True,
[2])
Tensor(shape=[2, 3], dtype=float32, place=Place(cpu), stop_gradient=True,
[[1., 2., 3.],
[4., 5., 6.]])Tensor 必须形如矩形,即在任何一个维度上,元素的数量必须相等,否则会抛出异常:
ValueError:
Faild to convert input data to a regular ndarray :
- Usually this means the input data contains nested lists with different lengths.
- 可通过
paddle.tolist将 Tensor 转换为 Python 序列数据 - 可通过
Tensor.numpy方法实现将 Tensor 转换为 Numpy 数组 - 基于给定数据创建 Tensor 时,飞桨是通过拷贝方式创建,与原始数据不共享内存。
2.1.2 指定形状创建
如果要创建一个指定形状的 Tensor,可以使用 paddle.zeros、paddle.ones、paddle.full 实现:
paddle.zeros([m, n], dtype=None, name=None) # 创建数据全为 0,形状为 [m, n] 的 Tensor
paddle.ones([m, n], dtype=None) # 创建数据全为 1,形状为 [m, n] 的 Tensor
paddle.full([m, n], 10, dtype=None, name=None) # 创建数据全为 10,形状为 [m, n] 的 Tensor例如:
paddle.ones([2,3],'float32')2.1.3 指定区间创建
指定区间内创建 Tensor,可以使用paddle.arrange、 paddle.linspace 实现:
# 创建以步长step均匀分隔区间[start, end)的Tensor
paddle.arange(start, end, step,dtype=None, name=None)
# 创建以元素个数num均匀分隔区间[start, end)的Tensor
paddle.linspace(start, stop, num, dtype=None, name=None) data = paddle.linspace(0, 10, 1, 'float32') # [0.0]
data = paddle.linspace(0, 10, 2, 'float32') # [0.,10.]
data = paddle.linspace(0, 10, 5, 'float32') # [0.0, 2.5, 5.0, 7.5, 10.0]除了以上指定数据、形状、区间创建 Tensor 的方法,飞桨还支持如下类似的创建方式,如:
- paddle.empty :创建一个空 Tensor,即根据 shape 和 dtype 创建尚未初始化元素值的 Tensor
paddle.ones_like、paddle.zeros_like、paddle.full_like、paddle.empty_like:创建一个与其他 Tensor 具有相同 shape 与 dtype 的 Tensorpaddle.clone:拷贝并创建一个与其他 Tensor 完全相同的 Tensor,该API提供梯度计算。
clone_x = paddle.clone(x)- paddle.rand(shape, dtype=None, name=None):符合均匀分布的,范围在[0, 1)的Tensor
- paddle.randn(shape, dtype=None, name=None):符合标准正态分布(均值为0,标准差为1的正态随机分布)的随机Tensor
- paddle.randint(low=0, high=None, shape=[1], dtype=None, name=None):服从均匀分布的、范围在[low, high)的随机Tensor。
- 设置随机种子创建 Tensor,每次生成相同元素值的随机数 Tensor,可通过
paddle.seed和paddle.rand组合实现
2.1.4 指定图像、文本数据创建
- paddle.vision.transforms.ToTensor :直接将 PIL.Image 格式的数据转为 Tensor
- paddle.to_tensor :将图像的标签(Label,通常是Python 或 Numpy 格式的数据)转为 Tensor。
- 文本场景,需将文本数据解码为数字后,再通过
paddle.to_tensor转为 Tensor
下面以图像场景为例介绍,以下示例代码中将随机生成的图片转换为 Tensor。
import numpy as np
from PIL import Image
import paddle.vision.transforms as T
import paddle.vision.transforms.functional as F
fake_img = Image.fromarray((np.random.rand(224, 224, 3) * 255.).astype(np.uint8)) # 创建随机图片
transform = T.ToTensor()
tensor = transform(fake_img) # 使用ToTensor()将图片转换为Tensor
print(tensor)Tensor(shape=[3, 224, 224], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[[[0.78039223, 0.72941178, 0.34117648, ..., 0.76470596, 0.57647061, 0.94901967],
...,
[0.49803925, 0.72941178, 0.80392164, ..., 0.08627451, 0.97647065, 0.43137258]]])说明:实际编码时,由于飞桨数据加载的 paddle.io.DataLoader API 能够将原始 paddle.io.Dataset 定义的数据自动转换为 Tensor,所以可以不做手动转换。具体如下节介绍。
2.1.5 自动创建 Tensor
paddle.io.DataLoader能够基于原始 Dataset,返回读取 Dataset 数据的迭代器,迭代器返回的数据中的每个元素都是一个 Tensorpaddle.Model.fit、paddle.Model.predict:这一些高层API,如果传入的数据不是 Tensor,会自动转为 Tensor 再进行模型训练或推理。 因此即使没有写将数据转为 Tensor 的代码,也能正常执行,提升了编程效率和容错性。
以下示例代码中,分别打印了原始数据集的数据,和送入 DataLoader 后返回的数据,可以看到数据结构由 Python list 转为了 Tensor。
import paddle
from paddle.vision.transforms import Compose, Normalize
transform = Compose([Normalize(mean=[127.5],
std=[127.5],
data_format='CHW')])
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
print(test_dataset[0][1]) # 打印原始数据集的第一个数据的label
loader = paddle.io.DataLoader(test_dataset)
for data in enumerate(loader):
x, label = data[1]
print(label) # 打印由DataLoader返回的迭代器中的第一个数据的label
break[7] # 原始数据中label为Python list
Tensor(shape=[1, 1], dtype=int64, place=Place(gpu_pinned), stop_gradient=True,
[[7]]) # 由DataLoader转换后,label为Tensor2.2 Tensor 的属性
Tensor(shape=[3], dtype=float32, place=Place(gpu:0), stop_gradient=True,
[2., 3., 4.])从上可以看到打印 Tensor 时有 shape、dtype、place 等信息,这些都是 Tensor 的重要属性。
2.2.1 Tensor的形状、reshape
可以通过 Tensor.shape 查看一个 Tensor 的形状,以下为相关概念:
- shape:描述了 Tensor 每个维度上元素的数量。
- ndim: Tensor 的维度数量。标量维度为0,向量维度为 1,矩阵维度为2,Tensor 可以有任意数量的维度。
- axis 或者 dimension:Tensor 的轴,即某个特定的维度。
- size:Tensor 中全部元素的个数。
创建 1 个四维 Tensor ,并通过图形来直观表达以上几个概念之间的关系:
ndim_4_Tensor = paddle.ones([2, 3, 4, 5])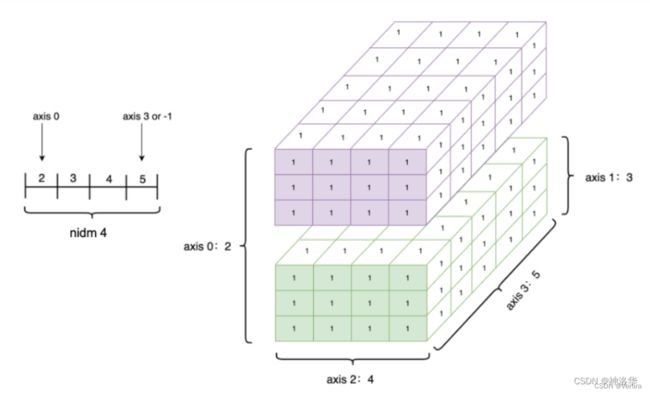
- paddle.reshape :改变 Tensor 的 shape,但并不改变 Tensor 的 size 和其中的元素数据。
- paddle.squeeze:可实现 Tensor 的降维操作,即把 Tensor 中尺寸为 1 的维度删除
- paddle.unsqueeze:可实现 Tensor 的升维操作,即向 Tensor 中某个位置插入尺寸为 1 的维度。
- paddle.flatten:将 Tensor 的数据在指定的连续维度上展平。
- transpose:对 Tensor 的数据进行重排。
x = paddle.to_tensor([1, 2, 3]).reshape([1, 3])
y = paddle.rand([5, 1, 10]).squeeze(axis=1)# shape=[5, 10]
x1=paddle.squeeze(x, axis=1)
y3= paddle.unsqueeze(y,axis=0)
z = paddle.randn([2, 3, 4])
z_transposed = paddle.transpose(z, perm=[1, 0, 2])
print(z_transposed.shape)#[3L, 2L, 4L]
2.2.2 Tensor数据类型和改变数据类型
Tensor.dtype:查看Tensor 的数据类型 dtype ,支持类型包括:bool、float16、float32、float64、uint8、int8、int16、int32、int64、complex64、complex128。paddle.cast:改变 Tensor 的 dtype:
x= paddle.to_tensor(1.0)#默认float32类型
y = paddle.cast(x, dtype='float64')#float64类型2.2.3 Tensor的设备位置(place)
Tensor.place:可指定Tensor分配的设备位置,可支持的设备位置有:CPU、GPU、固定内存等等。paddle.device.set_device:可设置全局默认的设备位置。Tensor.place的指定值优先级高于全局默认值。- 当未指定 place 时,Tensor 默认设备位置和安装的飞桨框架版本一致。如安装了 GPU 版本的飞桨,则设备位置默认为 GPU,即 Tensor 的place 默认为 paddle.CUDAPlace。
#创建CPU上的Tensor
cpu_Tensor = paddle.to_tensor(1, place=paddle.CPUPlace())
print(cpu_Tensor.place)#Place(cpu)
gpu_Tensor = paddle.to_tensor(1, place=paddle.CUDAPlace(0))
print(gpu_Tensor.place) # 显示Tensor位于GPU设备的第 0 张显卡上2.2.4 stop_gradient 和原位&非原位操作的区别
stop_gradient 表示是否停止计算梯度,默认值为 True,表示停止计算梯度。如不需要对某些参数进行训练更新,可以将参数的stop_gradient设置为True:
eg = paddle.to_tensor(1)
print("Tensor stop_gradient:", eg.stop_gradient)
eg.stop_gradient = False
print("Tensor stop_gradient:", eg.stop_gradient)paddle.reshape:非原位操作,不会修改原 Tensor,而是返回一个新的 Tensorpaddle.reshape_:原位操作,在原 Tensor 上保存操作结果,输出 Tensor 将与输入Tensor 共享数据,并且没有 Tensor 数据拷贝的过程
2.3 Tensor访问
2.3.1 索引和切片、Tensor修改
修改 Tensor 可以在单个或多个维度上通过索引或切片操作,操作会原地修改该 Tensor 的数值,且原值不会被保存。
2.3.2 数学计算、逻辑运算
飞桨还提供了丰富的 Tensor 操作的 API,包括数学运算、逻辑运算、线性代数等100余种 API,这些 API 调用有两种方法:
x = paddle.to_tensor([[1.1, 2.2], [3.3, 4.4]], dtype="float64")
y = paddle.to_tensor([[5.5, 6.6], [7.7, 8.8]], dtype="float64")
print(paddle.add(x, y), "\n") # 方法一
print(x.add(y), "\n") # 方法二数学计算
x.abs() #逐元素取绝对值
x.ceil() /x.floor() #逐元素向上/下取整
x.round() #逐元素四舍五入
x.exp() #逐元素计算自然常数为底的指数
x.log() #逐元素计算x的自然对数
x.reciprocal() #逐元素求倒数
x.square() / x.sqrt() #逐元素计算平方、平方根
x.sin()/x.cos() #逐元素计算正弦/余弦
x.max()/x.min() #指定维度上元素最大值/最小值,默认为全部维度
x.prod() #指定维度上元素累乘,默认为全部维度
x.sum() #指定维度上元素的和,默认为全部维度飞桨框架对 Python 数学运算相关的魔法函数进行了重写,例如:
x + y -> x.add(y) #逐元素相加
x - y -> x.subtract(y) #逐元素相减
x * y -> x.multiply(y) #逐元素相乘
x / y -> x.divide(y) #逐元素相除
x % y -> x.mod(y) #逐元素相除并取余
x ** y -> x.pow(y) #逐元素幂运算逻辑运算:
x.isfinite() #判断Tensor中元素是否是有限的数字,即不包括inf与nan
x.equal_all(y) #判断两个Tensor的全部元素是否相等,并返回形状为[1]的布尔类Tensor
x.equal(y) #判断两个Tensor的每个元素是否相等,并返回形状相同的布尔类Tensor
x.not_equal(y) #判断两个Tensor的每个元素是否不相等
x.allclose(y) #判断Tensor x的全部元素是否与Tensor y的全部元素接近,并返回形状为[1]的布尔类Tensor同样地,飞桨框架对 Python 逻辑比较相关的魔法函数进行了重写,以下操作与上述结果相同。
x == y -> x.equal(y) #判断两个Tensor的每个元素是否相等
x != y -> x.not_equal(y) #判断两个Tensor的每个元素是否不相等
x < y -> x.less_than(y) #判断Tensor x的元素是否小于Tensor y的对应元素
x <= y -> x.less_equal(y) #判断Tensor x的元素是否小于或等于Tensor y的对应元素
x > y -> x.greater_than(y) #判断Tensor x的元素是否大于Tensor y的对应元素
x >= y -> x.greater_equal(y) #判断Tensor x的元素是否大于或等于Tensor y的对应元素线性代数:
x.t() #矩阵转置
x.transpose([1, 0]) #交换第 0 维与第 1 维的顺序
x.norm('fro') #矩阵的弗罗贝尼乌斯范数
x.dist(y, p=2) #矩阵(x-y)的2范数
x.matmul(y) #矩阵乘法三、数据集定义与加载
参考《数据集定义与加载》
在飞桨框架中,可通过如下两个核心步骤完成数据集的定义与加载:
-
定义数据集:将磁盘中保存的原始图片、文字等样本和对应的标签映射到 Dataset,方便后续通过索引(index)读取数据,在 Dataset 中还可以进行一些数据变换、数据增广等预处理操作。在飞桨框架中推荐使用
paddle.io.Dataset自定义数据集,另外在paddle.vision.datasets和paddle.text目录下飞桨内置了一些经典数据集方便直接调用。 -
迭代读取数据集:自动将数据集的样本进行分批(batch)、乱序(shuffle)等操作,方便训练时迭代读取,同时还支持多进程异步读取功能可加快数据读取速度。在飞桨框架中可使用
paddle.io.DataLoader迭代读取数据集。
3.1 定义数据集
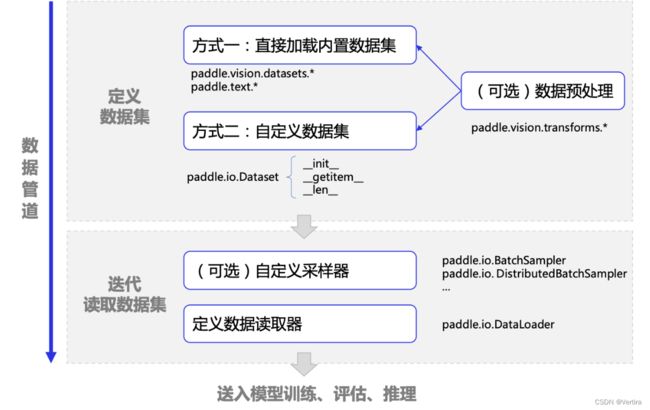
3.1.1 直接加载内置数据集
这部分内容在本文1.2.1已结讲过了
3.1.2 使用 paddle.io.Dataset 自定义数据集
在实际的场景中,一般需要使用自有的数据来定义数据集,这时可以通过 paddle.io.Dataset 基类来实现自定义数据集。
可构建一个子类继承自 paddle.io.Dataset ,并且实现下面的三个函数:
__init__:完成数据集初始化操作,将磁盘中的样本文件路径和对应标签映射到一个列表中。__getitem__:定义指定索引(index)时如何获取样本数据,最终返回对应 index 的单条数据(样本数据、对应的标签)。__len__:返回数据集的样本总数。
下面介绍下载 MNIST 原始数据集文件:
# 下载原始的 MNIST 数据集并解压
! wget https://paddle-imagenet-models-name.bj.bcebos.com/data/mnist.tar
# windows下可打开bash输入以下命令解压tar包
! tar -xf mnist.tar解压后文件模式如下

对应的标签
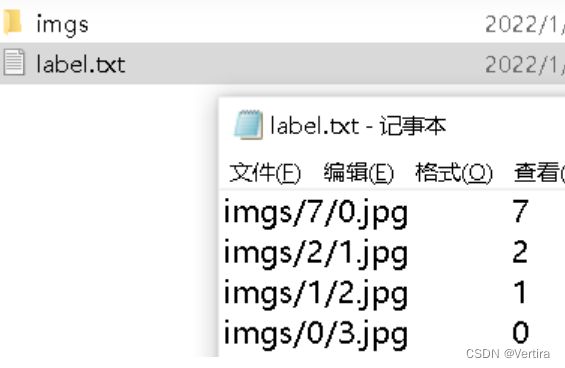
用 paddle.io.Dataset 定义数据集:
import os
import cv2
import numpy as np
from paddle.io import Dataset
from paddle.vision.transforms import Normalize
class MyDataset(Dataset):
def __init__(self, data_dir, label_path, transform=None):
"""
1.继承 paddle.io.Dataset 类
2.实现 __init__ 函数,初始化数据集,将样本和标签映射到列表中
"""
super(MyDataset, self).__init__()
self.data_list = []
with open(label_path,encoding='utf-8') as f:
for line in f.readlines():
#line的格式是:'imgs/5/0.jpg\t5\n'。.strip()去掉换行符,.split('\t')去掉制表符
image_path, label = line.strip().split('\t')#('imgs/5/0.jpg', '5')
image_path = os.path.join(data_dir, image_path)#'./mnist/train/imgs/5/0.jpg'
self.data_list.append([image_path, label])
# 传入定义好的数据处理方法,作为自定义数据集类的一个属性
self.transform = transform
def __getitem__(self, index):
"""
3.实现 __getitem__ 函数,定义指定 index 时如何获取数据,并返回单条数据(样本数据、对应的标签)
"""
# 根据索引,从列表中取出一个图像
image_path, label = self.data_list[index]
# 读取灰度图
image = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE)
# 飞桨训练时内部数据格式默认为float32,将图像数据格式转换为 float32
image = image.astype('float32')
# 应用数据处理方法到图像上
if self.transform is not None:
image = self.transform(image)
# CrossEntropyLoss要求label格式为int,将Label格式转换为 int
label = int(label)
# 返回图像和对应标签
return image, label
def __len__(self):
"""
4.实现 __len__ 函数,返回数据集的样本总数
"""
return len(self.data_list)
# 定义图像归一化处理方法,这里的CHW指图像格式需为 [C通道数,H图像高度,W图像宽度]
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# 打印数据集样本数
train_custom_dataset = MyDataset('mnist/train','mnist/train/label.txt', transform)
test_custom_dataset = MyDataset('mnist/val','mnist/val/label.txt', transform)
print('train_custom_dataset images: ',len(train_custom_dataset), 'test_custom_dataset images: ',len(test_custom_dataset)) 在上面的代码中,自定义了一个数据集类 MyDataset,MyDataset 继承自 paddle.io.Dataset 基类 ,并且实现了 __init__,__getitem__ 和 __len__ 三个函数。
- 在
__init__函数中完成了对标签文件的读取和解析,并将所有的图像路径 image_path 和对应的标签 label 存放到一个列表 data_list 中。 - 在
__getitem__函数中定义了指定 index 获取对应图像数据的方法,完成了图像的读取、预处理和图像标签格式的转换,最终返回图像和对应标签 image, label。 - 在
__len__函数中返回__init__函数中初始化好的数据集列表 data_list 长度。 - 另外,在
__init__函数和__getitem__函数中还可实现一些数据预处理操作,如对图像的翻转、裁剪、归一化等操作,最终返回处理好的单条数据(样本数据、对应的标签),该操作可增加图像数据多样性,对增强模型的泛化能力带来帮助。飞桨框架在 paddle.vision.transforms 下内置了几十种图像数据处理方法,详细使用方法可参考 数据预处理 章节。
3.2 迭代读取数据集
3.2.1 直接迭代读取自定义数据集
和内置数据集类似,可以使用下面的代码直接对自定义数据集进行迭代读取:
for data in train_custom_dataset:
image, label = data
print('shape of image: ',image.shape)
plt.title(str(label))
plt.imshow(image[0])
breakshape of image: (1, 28, 28)
3.2.2 使用 paddle.io.DataLoader 定义数据读取器
在飞桨框架中,推荐使用 paddle.io.DataLoader API 对数据集进行多进程的读取,并且可自动完成划分 batch 的工作。
# 定义并初始化数据读取器
train_loader = paddle.io.DataLoader(train_custom_dataset, batch_size=64, shuffle=True, num_workers=1, drop_last=True)
# 调用 DataLoader 迭代读取数据
for batch_id, data in enumerate(train_loader()):
images, labels = data
print("batch_id: {}, 训练数据shape: {}, 标签数据shape: {}".format(batch_id, images.shape, labels.shape))
breakbatch_id: 0, 训练数据shape: [64, 1, 28, 28], 标签数据shape: [64]
- 定义好数据读取器之后,便可用 for 循环方便地迭代读取批次数据,用于模型训练了。
- 高层 API 的
paddle.Model.fit已经封装了一部分 DataLoader 的功能,训练时只需定义数据集 Dataset 即可,不需要再单独定义 DataLoader。详细可参考 模型训练、评估与推理 章节。 - DataLoader中定义了采样的批次大小、顺序等信息,对应字段包括 batch_size、shuffle、drop_last。 是通过批采样器
BatchSampler产生的批次索引列表,并根据索引取得 Dataset 中的对应样本数据,以实现批次数据的加载。 - DataLoader 这三个字段也可以用一个
batch_sampler字段代替,并在 batch_sampler 中传入自定义的批采样器实例。两种方式二选一即可,可实现相同的效果,该用法可以更灵活地定义采样规则
3.2.3 (可选)自定义采样器
详情参考教程
-
采样器定义了从数据集中的采样行为,如顺序采样、批次采样、随机采样、分布式采样等。采样器会根据设定的采样规则,返回数据集中的索引列表,然后数据读取器 Dataloader 即可根据索引列表从数据集中取出对应的样本。
-
飞桨框架在 paddle.io 目录下提供了多种采样器,如批采样器 BatchSampler、分布式批采样器 DistributedBatchSampler、顺序采样器 SequenceSampler、随机采样器 RandomSampler 等。
3.2.4 多卡进行并行训练时,如何配置DataLoader进行异步数据读取
paddle中多卡训练时设置异步读取和单卡场景并无太大差别,动态图模式下,由于目前仅支持多进程多卡,每个进程将仅使用一个设备,比如一张GPU卡,这种情况下,与单卡训练无异,只需要确保每个进程使用的是正确的卡即可。
具体示例请参考飞桨API paddle.io.DataLoader中的示例。
四、数据预处理
本节以图像数据为例,介绍数据预处理的方法。
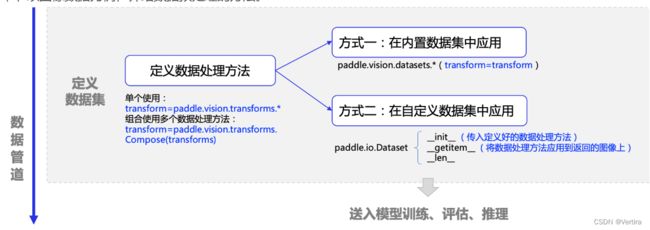
4.1 paddle.vision.transforms 简介
飞桨框架在 paddle.vision.transforms 下内置了数十种图像数据处理方法,包括图像随机裁剪、图像旋转变换、改变图像亮度、改变图像对比度等常见操作,各个操作方法的简介可参考 API 文档。
transform = CenterCrop(224) #对输入图像进行裁剪,保持图片中心点不变。
transform = RandomHorizontalFlip(0.5) #基于概率水平翻转图片,默认0.5
transform = RandomVerticalFlip(0.5) #基于概率垂直翻转图像,默认0.5
transform = RandomRotation(90) #对图像随机旋转,旋转的角度范围0°-90°
#随机调整图像的亮度、对比度、饱和度和色调。
transform = ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)1.单个调用:
from paddle.vision.transforms import Resize
# 定义了调整图像大小的方法
transform = Resize(size=28)
2.使用用Compose 进行组合调用:
from paddle.vision.transforms import Compose, RandomRotation
# 定义待使用的数据处理方法,这里包括随机旋转、改变图片大小两个组合处理
transform = Compose([RandomRotation(10), Resize(size=32)])4.2 在数据集中应用数据预处理操作
- 在框架内置数据集中应用
# 通过 transform 字段传递定义好的数据处理方法,即可完成对框架内置数据集的增强
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
2.在自定义的数据集中应用
对于自定义的数据集,可以在数据集中将定义好的数据处理方法传入 init 函数,将其定义为自定义数据集类的一个属性,然后在 getitem 中将其应用到图像上,代码见本文3.1.2节自定义数据集。
五、模型组网
模型组网是深度学习任务中的重要一环,该环节定义了神经网络的层次结构、数据从输入到输出的计算过程(即前向计算)等。模型组网常见用法有以下三种:
- 直接使用内置模型
- 使用
paddle.nn.Sequential组网 - 使用
paddle.nn.Layer组网
另外飞桨框架提供了 paddle.summary 函数方便查看网络结构、每层的输入输出 shape 和参数信息
5.1 直接使用内置模型
飞浆在 paddle.vision.models 下内置了计算机视觉领域的一些经典模型,行代码即可完成网络构建和初始化。
import paddle
print('飞桨框架内置模型:', paddle.vision.models.__all__)
桨框架内置模型: ['ResNet', 'resnet18', 'resnet34', 'resnet50', 'resnet101', 'resnet152', 'VGG', 'vgg11', 'vgg13', 'vgg16', 'vgg19', 'MobileNetV1', 'mobilenet_v1', 'MobileNetV2', 'mobilenet_v2', 'LeNet']以 LeNet 模型为例,可通过如下代码组网,
# 模型组网并初始化网络
lenet = paddle.vision.models.LeNet(num_classes=10)
# 可视化模型组网结构和参数
paddle.summary(lenet,(1, 1, 28, 28))
5.2 Paddle.nn 介绍、模型参数
参考 Paddle.nn 文档
5.2.1 Paddle.nn
paddle.nn:定义了丰富的神经网络层和相关函数 API,包括:
- 容器层:基于OOD实现的动态图Layer的
paddle.nn.Layer、顺序容器paddle.nn.Sequential等 - 1-3维卷积层:比如一维卷积层
paddle.nn.Conv1D、一维转置卷积层paddle.nn.Conv1DTranspose - pooling层:一二三维平均池化、最大池化等
- Padding层:一二三维padding层
- 循环神经网络层:
paddle.nn.RNN、paddle.nn.LSTM、paddle.nn.GRU等 - Transformer相关:
paddle.nn.Transformer、paddle.nn.MultiHeadAttention(多头注意力)、paddle.nn.TransformerDecoder、paddle.nn.TransformerEncoder - 线性层:
paddle.nn.Linear - Dropout层:
paddle.nn.Dropout等 - 激活层:
paddle.nn.GELU、paddle.nn.Softmax等激活函数 - Loss层:交叉熵损失层
paddle.nn.CrossEntropyLoss、paddle.nn.MSELoss等 - Normalization层:
paddle.nn.BatchNorm、paddle.nn.LayerNorm等 - Embedding层:
paddle.nn.Embedding
5.2.2 模型的参数(Parameter)
可通过网络的 parameters() 和 named_parameters() 方法获取网络在训练期间优化的所有参数(权重 weight 和偏置 bias),通过这些方法可以实现对网络更加精细化的控制,如设置某些层的参数不更新。
下面这段示例代码,通过 named_parameters() 获取了 LeNet 网络所有参数的名字和值,打印出了参数的名字(name)和形状(shape):
for name, param in lenet.named_parameters():
print(f"Layer: {name} | Size: {param.shape}")Layer: features.0.weight | Size: [6, 1, 3, 3]
Layer: features.0.bias | Size: [6]
Layer: features.3.weight | Size: [16, 6, 5, 5]
Layer: features.3.bias | Size: [16]
Layer: fc.0.weight | Size: [400, 120]
Layer: fc.0.bias | Size: [120]
Layer: fc.1.weight | Size: [120, 84]
Layer: fc.1.bias | Size: [84]
Layer: fc.2.weight | Size: [84, 10]
Layer: fc.2.bias | Size: [10]
5.3 使用 paddle.nn.Sequential 组网
构建顺序的线性网络结构时,可以选择该方式,只需要按模型的结构顺序,一层一层加到 paddle.nn.Sequential 子类中即可。例如构建LeNet 模型结构的代码如下:
from paddle import nn
# 使用 paddle.nn.Sequential 构建 LeNet 模型
lenet_Sequential = nn.Sequential(
nn.Conv2D(1, 6, 3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2D(2, 2),
nn.Conv2D(6, 16, 5, stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2D(2, 2),
nn.Flatten(),
nn.Linear(400, 120),
nn.Linear(120, 84),
nn.Linear(84, 10)
)
# 可视化模型组网结构和参数
paddle.summary(lenet_Sequential,(1, 1, 28, 28))使用 Sequential 组网时,会自动按照层次堆叠顺序完成网络的前向计算过程,简略了定义前向计算函数的代码。由于 Sequential 组网只能完成简单的线性结构模型,所以对于需要进行分支判断的模型需要使用 paddle.nn.Layer 组网方式实现。
5.4 使用 paddle.nn.Layer 组网
构建一些比较复杂的网络结构时,可以选择该方式,组网包括三个步骤:
- 创建一个继承自 paddle.nn.Layer 的类;
- 在类的构造函数
__init__中定义组网用到的神经网络层(layer); - 在类的前向计算函数 forward 中使用定义好的 layer 执行前向计算。
仍然以 LeNet 模型为例,使用 paddle.nn.Layer 组网的代码如下:
# 使用 Subclass 方式构建 LeNet 模型
class LeNet(nn.Layer):
def __init__(self, num_classes=10):
super(LeNet, self).__init__()
self.num_classes = num_classes
# 构建 features 子网,用于对输入图像进行特征提取
self.features = nn.Sequential(
nn.Conv2D(
1, 6, 3, stride=1, padding=1),
nn.ReLU(),
nn.MaxPool2D(2, 2),
nn.Conv2D(
6, 16, 5, stride=1, padding=0),
nn.ReLU(),
nn.MaxPool2D(2, 2))
# 构建 linear 子网,用于分类
if num_classes > 0:
self.linear = nn.Sequential(
nn.Linear(400, 120),
nn.Linear(120, 84),
nn.Linear(84, num_classes)
)
# 执行前向计算
def forward(self, inputs):
x = self.features(inputs)
if self.num_classes > 0:
x = paddle.flatten(x, 1)
x = self.linear(x)
return x
lenet_SubClass = LeNet()
# 可视化模型组网结构和参数
params_info = paddle.summary(lenet_SubClass,(1, 1, 28, 28))
print(params_info)在上面的代码中,将 LeNet 分为了 features 和 linear 两个子网,features 用于对输入图像进行特征提取,linear 用于输出十个数字的分类。
5.5 组网、训练、评估常见问题
参考《组网、训练、评估常见问题》
5.6 模型参数常见问题(梯度裁剪、共享权重、分层学习率等)
参考:《参数调整常见问题》
六:模型训练、评估与推理
桨框架提供了两种训练、评估与推理的方法:
- 飞桨高层 API:先用 paddle.Model 对模型进行封装,然后通过 Model.fit 、 Model.evaluate 、 Model.predict 等完成模型的训练、评估与推理。该方式代码量少,适合快速上手。
- 飞桨基础 API:提供了损失函数、优化器、评价指标、更新参数、反向传播等基础组件的实现,可以更灵活地应用到模型训练、评估与推理任务中,当然也可以很方便地自定义一些组件用于相关任务中。
6.1 指定训练的硬件
默认情况下飞桨框架会根据所安装的版本自动选择对应硬件,比如安装的 GPU 版本的飞桨,则自动使用 GPU 训练模型,无需手动指定。因此一般情况下,无需执行此步骤。
但是如果安装的 GPU 版本的飞桨框架,想切换到 CPU 上训练,则可通过 paddle.device.set_device 修改。如果本机有多个 GPU 卡,也可以通过该 API 选择指定的卡进行训练,不指定的情况下则默认使用 ‘gpu:0’。
import paddle
# 指定在 CPU 上训练
paddle.device.set_device('cpu')
# 指定在 GPU 第 0 号卡上训练
# paddle.device.set_device('gpu:0')
本节仅以单机单卡场景为例,介绍模型训练的方法,如果需要使用单机多卡、多机多卡训练,请参考分布式训练。飞桨框架除了支持在 CPU、GPU 上训练,还支持在百度昆仑 XPU、华为昇腾 NPU 等 AI 计算处理器上训练
6.2 加载数据集、定义模型
以 MNIST 手写数字识别任务为例,代码示例如下:
from paddle.vision.transforms import Normalize
transform = Normalize(mean=[127.5], std=[127.5], data_format='CHW')
# 加载 MNIST 训练集和测试集
train_dataset = paddle.vision.datasets.MNIST(mode='train', transform=transform)
test_dataset = paddle.vision.datasets.MNIST(mode='test', transform=transform)
# 模型组网,构建并初始化一个模型 mnist
mnist = paddle.nn.Sequential(
paddle.nn.Flatten(1, -1),
paddle.nn.Linear(784, 512),
paddle.nn.ReLU(),
paddle.nn.Dropout(0.2),
paddle.nn.Linear(512, 10)
)
- 使用 paddle.Model 封装模型
6.3 使用 paddle.Model 高层 API 训练、评估与推理
使用 paddle.Model 封装模型
2.使用 Model.prepare 配置训练准备参数
可通过 Model.prepare 进行训练前的配置准备工作,包括:
- paddle.optimizer 设置优化算法、 paddle.optimizer.lr 设置学习率策略;
- paddle.nn Loss层设置Loss 计算方法;
- paddle.metric 设置评价指标相关计算方法。
- amp_configs (str|dict|None) – 混合精度训练的配置,通常是个dict,也可以是str
# 为模型训练做准备,设置优化器及其学习率,并将网络的参数传入优化器,设置损失函数和精度计算方式
model.prepare(optimizer=paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters()),
loss=paddle.nn.CrossEntropyLoss(),
metrics=paddle.metric.Accuracy())
3.使用 Model.fit 训练模型
调用 Model.fit 接口来启动训练,需要指定至少三个关键参数:训练数据集,训练轮次和每批次大小。
# 启动模型训练,指定训练数据集,设置训练轮次,设置每次数据集计算的批次大小,设置日志格式
model.fit(train_dataset,
epochs=5,
batch_size=64,
verbose=1)完整参数为:
fit(train_data=None, eval_data=None, batch_size=1, epochs=1, eval_freq=1,
log_freq=10, save_dir=None, save_freq=1, verbose=2,
drop_last=False, shuffle=True, num_workers=0, callbacks=None)-
train_data (Dataset|DataLoader) – 一个可迭代的数据源,比如 paddle paddle.io.Dataset 或 paddle.io.Dataloader 的实例。
-
eval_data (Dataset|DataLoader) – 同上,当给定时,会在每个 epoch 后都会进行评估。默认值:None。
-
batch_size (int) – 训练数据或评估数据的批大小,当 train_data 或 eval_data 为 DataLoader 的实例时,该参数会被忽略。默认值:1。
-
shuffle (bool) – 是否样本乱序。当 train_data 为 DataLoader 的实例时,该参数会被忽略。默认值:True。
-
epochs (int) – 训练的轮数。默认值:1。
-
eval_freq (int) – 评估的频率,多少个 epoch 评估一次。默认值:1。
-
log_freq (int) – 日志打印的频率,多少个 step 打印一次日志。默认值:1。
-
save_dir (str|None) – 保存模型的文件夹,如果不设定,将不保存模型。默认值:None。
-
save_freq (int) – 保存模型的频率,多少个 epoch 保存一次模型。默认值:1。
-
verbose (int) – 可视化的模型,必须为0,1,2。当设定为0时,不打印日志,设定为1时,使用进度条的方式打印日志,设定为2时,一行一行地打印日志。默认值:2。
-
drop_last (bool) – 是否丢弃不完整的批次样本。默认值:False。
-
num_workers (int) – 启动子进程用于读取数据的数量。当 train_data 和 eval_data 都为 DataLoader 的实例时,该参数会被忽略。默认值:0。
-
callbacks (Callback|list[Callback]|None) – 传入回调函数,在模型训练的各个阶段进行一些自定义操作,比如收集训练过程中的一些数据和参数。
The loss value printed in the log is the current step, and the metric is the average value of previous steps.
Epoch 1/5
step 10/938 [..............................] - loss: 0.9679 - acc: 0.4109 - ETA: 13s - 14ms/stepstep 938/938 [==============================] - loss: 0.1158 - acc: 0.9020 - 10ms/step
Epoch 2/5
step 938/938 [==============================] - loss: 0.0981 - acc: 0.9504 - 10ms/step
Epoch 3/5
step 938/938 [==============================] - loss: 0.0215 - acc: 0.9588 - 10ms/step
Epoch 4/5
step 938/938 [==============================] - loss: 0.0134 - acc: 0.9643 - 10ms/step
Epoch 5/5
step 938/938 [==============================] - loss: 0.3371 - acc: 0.9681 - 11ms/step
4.使用 Model.evaluate 评估模型
模型训练完后,使用 Model.evaluate 接口完成模型评估操作,根据在 Model.prepare 中定义的 loss 和 metric 计算并返回相关评估结果。返回格式是一个字典(可包含loss和多个评估指标)
# 用 evaluate 在测试集上对模型进行验证
eval_result = model.evaluate(test_dataset, verbose=1)
print(eval_result)Eval begin...
step 10000/10000 [==============================] - loss: 2.3842e-07 - acc: 0.9714 - 2ms/step
Eval samples: 10000
{'loss': [2.384186e-07], 'acc': 0.9714}
5.使用 Model.predict 执行推理
Model.predict 接口,可对训练好的模型进行推理验证,返回的结果格式是一个列表:
# 用 predict 在测试集上对模型进行推理
test_result = model.predict(test_dataset)
# 由于模型是单一输出,test_result的形状为[1, 10000],10000是测试数据集的数据量。
#这里打印第一个数据的结果,这个数组表示每个数字的预测概率
print(test_result[0][0])
# 从测试集中取出一张图片
img, label = test_dataset[0]
# 打印推理结果,这里的argmax函数用于取出预测值中概率最高的一个的下标,作为预测标签
pred_label = test_result[0][0].argmax()
print('true label: {}, pred label: {}'.format(label[0], pred_label))
# 使用matplotlib库,可视化图片
from matplotlib import pyplot as plt
plt.imshow(img[0])Predict begin...
step 10000/10000 [==============================] - 2ms/step
Predict samples: 10000
[[ -6.512169 -6.7076845 0.5048795 1.6733919 -9.670526 -1.6352568
-15.833721 13.87411 -8.215239 1.5966017]]
true label: 7, pred label: 7除了上面介绍的三个 API 之外, paddle.Model 类也提供了其他与训练、评估与推理相关的 API:
- Model.train_batch:在一个批次的数据集上进行训练;
- Model.eval_batch:在一个批次的数据集上进行评估;
- Model.predict_batch:在一个批次的数据集上进行推理。
6.4 使用基础 API 训练、评估与推理
Model.prepare 、 Model.fit 、 Model.evaluate 、 Model.predict 都是由基础 API 封装而来。
6.4.1 模型训练
对应高层 API 的 Model.prepare 与 Model.fit ,一般包括如下几个步骤:
- 加载训练数据集、声明模型、设置模型实例为 train 模式
- 设置优化器、损失函数与各个超参数
- 设置模型训练的二层循环嵌套,并在内层循环嵌套中设置如下内容
- 从数据读取器 DataLoader 获取一批次训练数据
- 执行一次预测,即经过模型计算获得输入数据的预测值
- 计算预测值与数据集标签的损失
- 计算预测值与数据集标签的准确率
- 将损失进行反向传播
- 打印模型的轮数、批次、损失值、准确率等信息
- 执行一次优化器步骤,即按照选择的优化算法,根据当前批次数据的梯度更新传入优化器的参数
- 将优化器的梯度进行清零
# 用 DataLoader 实现数据加载
train_loader = paddle.io.DataLoader(train_dataset, batch_size=64, shuffle=True)
mnist.train()
# 设置迭代次数、损失函数
epochs,loss_fn = 5,paddle.nn.CrossEntropyLoss()
# 设置优化器
optim = paddle.optimizer.Adam(parameters=mnist.parameters())
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0] # 训练数据
y_data = data[1] # 训练数据标签
predicts = mnist(x_data) # 预测结果
loss = loss_fn(predicts, y_data)
acc = paddle.metric.accuracy(predicts, y_data)
# 下面的反向传播、打印训练信息、更新参数、梯度清零都被封装到 Model.fit() 中
# 反向传播
loss.backward()
if (batch_id+1) % 900 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id+1, loss.numpy(), acc.numpy()))
optim.step() # 更新参数
optim.clear_grad() # 梯度清零epoch: 0, batch_id: 900, loss is: [0.06991791], acc is: [0.96875]
epoch: 1, batch_id: 900, loss is: [0.02878829], acc is: [1.]
epoch: 2, batch_id: 900, loss is: [0.07192856], acc is: [0.96875]
epoch: 3, batch_id: 900, loss is: [0.20411499], acc is: [0.96875]
epoch: 4, batch_id: 900, loss is: [0.13589518], acc is: [0.96875]
6.4.2 模型评估
模型实例从 train 模式改为 eval 模式,不需要反向传播、优化器参数更新和优化器梯度清零。
# 加载测试数据集
test_loader = paddle.io.DataLoader(test_dataset, batch_size=64, drop_last=True)
loss_fn = paddle.nn.CrossEntropyLoss()
# 将该模型及其所有子层设置为预测模式。这只会影响某些模块,如Dropout和BatchNorm
mnist.eval()
# 禁用动态图梯度计算
for batch_id, data in enumerate(test_loader()):
x_data = data[0] # 测试数据
y_data = data[1] # 测试数据标签
predicts = mnist(x_data) # 预测结果
loss = loss_fn(predicts, y_data)
acc = paddle.metric.accuracy(predicts, y_data)
# 打印信息
if (batch_id+1) % 30 == 0:
print("batch_id: {}, loss is: {}, acc is: {}".format(batch_id+1, loss.numpy(), acc.numpy()))batch_id: 30, loss is: [0.23106411], acc is: [0.953125]
batch_id: 60, loss is: [0.4329119], acc is: [0.90625]
batch_id: 90, loss is: [0.07333981], acc is: [0.96875]
batch_id: 120, loss is: [0.00324837], acc is: [1.]
batch_id: 150, loss is: [0.0857158], acc is: [0.96875]6.4.3 模型推理
模型的推理过程相对独立,是在模型训练与评估之后单独进行的步骤。只需要执行如下步骤:
- 加载待执行推理的测试数据,并将模型设置为 eval 模式
- 读取测试数据并获得预测结果
- 对预测结果进行后处理
# 加载测试数据集
test_loader = paddle.io.DataLoader(test_dataset, batch_size=64, drop_last=True)
# 将该模型及其所有子层设置为预测模式
mnist.eval()
for batch_id, data in enumerate(test_loader()):
# 取出测试数据
x_data = data[0]
# 获取预测结果
predicts = mnist(x_data)
print("predict finished")
6.5 综合使用高层 API 和基础 API 、模型部署
飞桨的高层 API 和基础 API 可以组合使用,并不是完全割裂开的,这样有助于开发者更便捷地完成算法迭代。示例代码如下:
from paddle.vision.models import LeNet
class FaceNet(paddle.nn.Layer):
def __init__(self):
super().__init__()
# 使用高层API组网
self.backbone = LeNet()
# 使用基础API组网
self.outLayer1 = paddle.nn.Sequential(
paddle.nn.Linear(10, 512),
paddle.nn.ReLU(),
paddle.nn.Dropout(0.2)
)
self.outLayer2 = paddle.nn.Linear(512, 10)
def forward(self, inputs):
out = self.backbone(inputs)
out = self.outLayer1(out)
out = self.outLayer2(out)
return out
# 使用高层API封装网络
model = paddle.Model(FaceNet())
# 使用基础API定义优化器
optim = paddle.optimizer.Adam(learning_rate=1e-3, parameters=model.parameters())
# 使用高层API封装优化器和损失函数
model.prepare(optim, paddle.nn.CrossEntropyLoss(), metrics=paddle.metric.Accuracy())
# 使用高层API训练网络
model.fit(train_dataset, test_dataset, epochs=5, batch_size=64, verbose=1)本节中介绍了在飞桨框架中使用高层 API 进行模型训练、评估和推理的方法,并拆解出对应的基础 API 实现方法。需要注意的是,这里的推理仅用于模型效果验证,实际生产应用中,则可使用飞桨提供的一系列推理部署工具,满足服务器端、移动端、网页/小程序等多种环境的模型部署上线需求,具体可参见 推理部署 章节。
七、模型保存与载入
7.1 保存载入体系简介
参考:《模型保存与载入》、《模型保存常见问题》
panddle2.1对模型与参数的保存与载入,有以下体系:
- 基础API保存载入体系(6个接口)
- 训练调优场景:推荐使用
paddle.save/load保存和载入模型 - 推理部署场景,推荐使用paddle.jit.save/load(动态图)和paddle.static.save/load_inference_model(静态图)保存载入模型
- 高阶API保存载入体系:
- paddle.Model.fit (训练接口,同时带有参数保存的功能)
- paddle.Model.save、paddle.Model.load

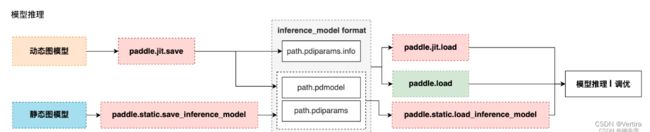
7.2 训练调优场景的模型&参数保存载入
7.2.1 动态图参数保存载入
- 若仅需要保存/载入模型的参数,可以使用
paddle.save/load结合Layer和Optimizer的state_dict达成目的 - state_dict是对象的持久参数的载体,dict的key为参数名,value为参数真实的numpy array值。
- 参数保存时,先获取目标对象(Layer或者Optimzier)的state_dict,然后将state_dict保存至磁盘
- 参数载入时,先从磁盘载入保存的state_dict,然后通过set_state_dict方法配置到目标对象中
以LeNet举例,如何保存和载入模型:
import numpy as np
import paddle
import paddle.nn as nn
import paddle.optimizer as opt
#定义模型和优化器
model= paddle.vision.models.LeNet(num_classes=10)
adam = opt.Adam(learning_rate=0.001, parameters=layer.parameters())
# 保存模型参数和优化器参数
"""
参数保存时,先获取目标对象(Layer或者Optimzier)的state_dict,
然后将state_dict保存至磁盘
"""
paddle.save(model.state_dict(), PATH1)#
paddle.save(adam.state_dict(), PATH2)
#模型和优化器参数载入
"""
参数载入时,先从磁盘载入保存的state_dict,然后通过set_state_dict方法配置到目标对象中
"""
model.set_state_dict(paddle.load(PATH1))#可分两步写model_state_dict = paddle.load(PATH1)
adam.set_state_dict(paddle.load(PATH2))#同上,便于理解可以分两步写此时,已经保存了模型的参数和优化器参数(有scheduler的话也保存了),所以加载后可用于增量训练模型的继续训练。
7.3 静态图模型&参数保存载入
还是以LeNet举例:
- 保存参数:
paddle.save/load结合模型的state_dict达成,类似上面动态图保存 - 保存整个模型:保存参数之外,还需使用
paddle.save保存模型结构Program
import numpy as np
import paddle
import paddle.nn as nn
import paddle.optimizer as opt
#定义模型和优化器
model= paddle.vision.models.LeNet(num_classes=10)
adam = opt.Adam(learning_rate=0.001, parameters=layer.parameters())
paddle.save(model.state_dict(),"temp/model.pdparams")#保存模型参数
paddle.save(model, "temp/model.pdmodel") #保存模型结构
"""
如果只保存了state_dict,只需要载入参数state_dict
如果同时保存了模型结构,需要先载入模型结构
"""
prog = paddle.load("temp/model.pdmodel")#r\如果没有保存模型结构,跳过此步
state_dict = paddle.load("temp/model.pdparams")
prog.set_state_dict(state_dict)
7.4 常见问题
paddle.load可以加载哪些API产生的结果呢?
paddle.load除了可以加载paddle.save保存的模型之外,也可以加载其他save相关API存储的state_dict, 但是在不同场景中,参数path的形式有所不同:
- 从
paddle.static.save或者paddle.Model().save(training=True)的保存结果载入:path需要是完整的文件名,例如model.pdparams或者model.opt; - 从
paddle.jit.save或者paddle.static.save_inference_model或者paddle.Model().save(training=False)的保存结果载入:path需要是路径前缀, 例如model/mnist,paddle.load会从mnist.pdmodel和mnist.pdiparams中解析state_dict的信息并返回。 - 从paddle 1.x API
paddle.fluid.io.save_inference_model或者paddle.fluid.io.save_params/save_persistables的保存结果载入:path需要是目录,例如model,此处model是一个文件夹路径。
需要注意的是,如果从paddle.static.save或者paddle.static.save_inference_model等静态图API的存储结果中载入state_dict,动态图模式下参数的结构性变量名将无法被恢复。在将载入的state_dict配置到当前Layer中时,需要配置Layer.set_state_dict的参数use_structured_name=False。
7.5 训练部署场景的模型&参数保存载入
请参考paddle文档
八、paddle开发进阶用法
以下内容请参考paddle文档
8.1 模型可视化
8.2 Paddle中的模型与层
8.3 自定义Loss、Metric 及 Callback
8.4 分布式训练