随机森林 matlab
Ref: 官方 matlab 已有牛人
在前人的基础上进行学习,然后针对具体应用。 很容易掌握 随机森林法
基本概念
Random Forest(随机森林)是Bagging的扩展变体,它在以决策树 为基学习器构建Bagging集成的基础上,进一步在决策树的训练过程中引入了随机特征选择
因此可以概括RF包括四个部分:
1、随机选择样本(放回抽样);
2、随机选择特征属性;
3、构建决策树;
4、随机森林投票(平均) 因此防止过拟合能力更强,降低方差。
图来源: 影响随机森林模型的参数

1 确定参数: leaf 和tree的数量
这一块直接使用他人代码,然后根据自己需求修改 。
input:输入的工艺参数 m*n , n个特征。
output:输出结果 m*1
for RFOptimizationNum=1:5
RFLeaf=[5,10,20,50,100,200,500];
col='rgbcmyk';
figure('Name','RF Leaves and Trees');
for i=1:length(RFLeaf)
RFModel=TreeBagger(2000,Input,Output,'Method','R','OOBPrediction','On','MinLeafSize',RFLeaf(i));
plot(oobError(RFModel),col(i));
hold on
end
xlabel('Number of Grown Trees');
ylabel('Mean Squared Error') ;
LeafTreelgd=legend({'5' '10' '20' '50' '100' '200' '500'},'Location','NorthEast');
title(LeafTreelgd,'Number of Leaves');
hold off;
% xlabel 'Number of Grown Trees'
% ylabel 'Mean Squared Error'
disp(RFOptimizationNum);
end
%RFLeaf=50; NumTrees=400RFOptimizationNum是为了多次循环,防止最优结果受到随机干扰。
RFLeaf定义初始的叶子节点个数,这里设置了从5到500,从5到500这个范围内找到最优叶子节点个数。
Input与Output分别是输入(自变量)与输出(因变量)
如果训练还要调参,看这个
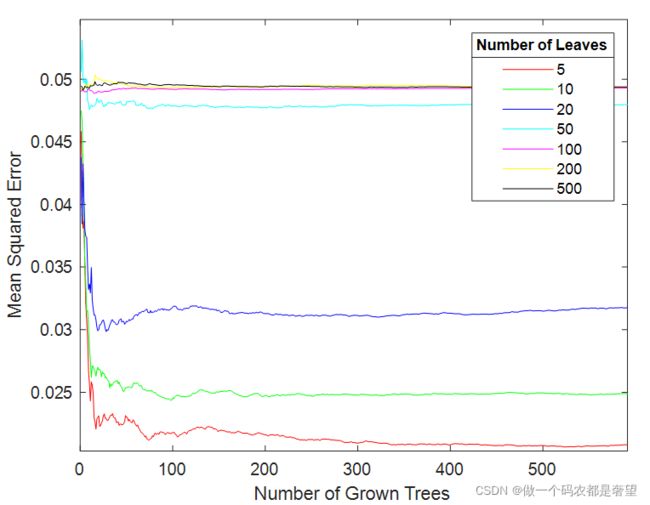
叶子5(mse最小),树350(稳定了)
2 模型训练
采用上面的参数进行训练
这里涉及里的一个随机分配数据集的问题,我的程序中数据已经归一化到【0,1】,所以获得随机样本后,有一个找训练集,然后删除随机样本的模块。就是赋值=-2,标记为随机的样本,循环外将测试集的行删除了。这里还可有其他方法,深度学习里有矩阵删除。后期补充。
TrainYield是训练集的因变量,TrainVARI是训练集的自变量;TestYield是测试集的因变量,TestVARI是测试集的自变量。
变量名参照大牛的程序,所以没改。
%% Training Set and Test Set Division
RandomNumber=(randperm(length(Output),floor(length(Output)*0.2)))';
TrainYield=Output;
TestYield=zeros(length(RandomNumber),1);
TrainVARI=Input;
TestVARI=zeros(length(RandomNumber),size(TrainVARI,2));
for i=1:length(RandomNumber)
m=RandomNumber(i,1);
TestYield(i,1)=TrainYield(m,1);
TestVARI(i,:)=TrainVARI(m,:);
TrainYield(m,1)=-2;
TrainVARI(m,:)=-2;
end
TrainYield(all(TrainYield==-2,2),:)=[];
TrainVARI(all(TrainVARI==-2,2),:)=[];
%% RF
nTree=350;%200;%350;
nLeaf=5;% 前面获得的
RFModel=TreeBagger(nTree,TrainVARI,TrainYield,...
'Method','regression','OOBPredictorImportance','on', 'MinLeafSize',nLeaf);
[RFPredictYield,RFPredictConfidenceInterval]=predict(RFModel,TestVARI);
% PredictBC107=cellfun(@str2num,PredictBC107(1:end));
%% Accuracy of RF
RFRMSE=sqrt(sum(sum((RFPredictYield-TestYield).^2))/size(TestYield,1));
RFrMatrix=corrcoef(RFPredictYield,TestYield);
RFr=RFrMatrix(1,2);
RFRMSEMatrix=[RFRMSEMatrix,RFRMSE];
RFrAllMatrix=[RFrAllMatrix,RFr];
% if RFRMSE<1000
disp(RFRMSE);
% break;
% end
% disp(RFCycleRun);
% str=['Random Forest is Solving...',num2str(100*RFCycleRun/RFRunNumSet),'%'];
% waitbar(RFCycleRun/RFRunNumSet,RFScheduleBar,str);
% end
close(RFScheduleBar);
RFRMSE
% % rmse=0.20
[mae,rmse,r2,mape] = EvlMetrix(TestYield,RFPredictYield) nTree、nLeaf就是 确定的最优树个数与最优叶子节点个数,RFModel就是训练的模型,RFPredictYield是预测结果,RFPredictConfidenceInterval是预测结果的置信区间。
3 模型结果对比
用随机测试集来测试性能
[RFPredictYield,RFPredictConfidenceInterval]=predict(RFModel,TestVARI);
[mae,rmse,r2,mape] = EvlMetrix(TestYield,RFPredictYield)
figure
plot(TestYield,'b-d')
hold on
plot(RFPredictYield,'r-d')
hold off
legend('GroundTruth','Prediction')
xlabel('Sample Number')
ylabel('target Value')
4 评价函数
评价指标介绍 看大牛的
评价指标的函数 MAE, RMSE, R2,MAPE 等具体计算方法如下,我进行了封装, Yreal,Ypred分别是真值和预测值。
平均绝对误差

均方根误差

平均绝对误差(Mean Absolute Error)
.
平均绝对百分比误差(Mean Absolute Percentage Error)

我用R2和mae进行性能比较
具体函数如下:
function [mae,rmse,r2,mape] = EvlMetrix(YReal,YPred)
% caculate the index of machine learning
% Detailed explanation goes here
rmse = sqrt(mean((YPred-YReal).^2));
r2 = 1 - (sum((YPred - YReal).^2) / sum((YReal - mean(YReal)).^2));
mae = mean(abs(YReal - YPred));
mape = mean(abs((YReal - YPred)./YReal));
end
5 关联指标评价
我的参数太少,没用
figure
bar(RFModel.OOBPermutedVarDeltaError)
xlabel 'Feature Number'
ylabel 'Out-of-Bag Feature Importance'