【PyTorch】构造VGG19网络进行本地图片分类(超详细过程)——程序代码
本篇博客主要解决以下3个问题:
- 如何自定义网络(以VGG19为例)。
- 如何自建数据集并加载至模型中。
- 如何使用自定义数据训练自定义模型。
第一篇:【PyTorch】构造VGG19网络进行本地图片分类(超详细过程)——项目介绍
第二篇:【PyTorch】构造VGG19网络进行本地图片分类(超详细过程)——程序代码
Github:https://github.com/MarvelInSky/vgg_classify
文章目录
- 1 vgg_model.py
- 2 vgg_dataset.py
- 3 vgg_train.py
- 4 vgg_test.py
- 5 vgg_classify.pt
1 vgg_model.py
在PyTorch深度学习框架下,自定义一个模型均通过继承nn.Module类来实现,需要在init构造函数中定义各层结构,在forward中实现层之间的连接关系,实际上就是前向传播的过程。其代码结构如下:
import torch.nn as nn
class VGG(nn.Module):
# 初始化并定义网络结构
def __init__():
# 定义网络结构
...
def forward(self, x)
# 前项传播的方法
其中主要包含卷积层、池化层和全连接层,前项传播就是将图片数据输入到网络中,经过层层卷积、池化、全连接等各种操作得到输出。针对于3分类问题,输出为 [ 1 , 3 ] [1,3] [1,3]的矩阵,每一个值表示为该类别的概率。
卷积层可以起到下采样的作用,提取图片中的特征,其中in-channels为输入的维度,第一层卷积层的输入通常为3,因为输入图片通常为3通道的RGB图片;out-channels为输出维度;kernel-size为卷积核的大小;stride为卷积核移动的步长;padding为零填充区大小。
池化层可以进一步缩小图像尺寸减少计算量,nn.MaxPool2d表示采用最大池化方法,kernel-size=2表示在2 × \times × 2的区域范围内进行池化,stride表示池化的步长;padding为零填充区大小。
nn.Linear表示全连接层,in-features表示输入的维度,out-features输出的特征参数数量,即输出维度。最后一层全连接层输出的维度为类别的数目,分别对应各类别的概率。
其中,nn.BatchNorm2d()表示2维的batch normalization,批量正则化;nn.ReLU()为激活函数,对传递的值进行非线性化处理。nn.Dropout(p=0.5)防止过低和,舍弃50%的参数。
# 卷积层
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# 池化层
nn.MaxPool2d(kernel_size=2,stride=2,padding=0)
)
# 全连接层
self.fc17 = nn.Sequential(
nn.Linear(input_channel=int(512 * img_size * img_size / 32 / 32), out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5)
图像输入到模型中,经过每一层后其维度的变化如表所示。其中,第一个参数表示输入的batch,第二个参数表示图像通道数,第三和第四个参数表示图像尺寸。因为在训练时,设置batchsize=4,所以此时第一个参数为4;因为输入到模型中的图像为3通道的RGB图片,所以初始的深度为3;因为输入图像的尺寸为128$\times$128,所以第三和第四个参数均为128。通过不断的卷积核下采样最终维度变为[4, 512, 4, 4]的张量,全连接层将这些参数全部连接起来,其中 512 × 4 × 4 = 8192 512\times4\times4=8192 512×4×4=8192,所以第一个全连接网络的输入维度为8192;然而,此处的数值会因为输的图片尺寸的不同而发生变化,所以可以设置该处的数值为 512 × ( i m g s i z e / 32 ) 2 512\times (imgsize/32)^2 512×(imgsize/32)2。最后一层全连接层将维度从4096转变为类别数量3,直接得出每种类别的概率。可以取其中概率最高的类别作为该图片的最终分类结果。

代码如下:
# vgg_model.py
import torch.nn as nn
class VGG(nn.Module):
# initialize model
def __init__(self, img_size=224, input_channel=3, num_class=3):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channels=input_channel, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64), # default parameter:nn.BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
nn.ReLU(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2,stride=2,padding=0)
)
self.conv3 = nn.Sequential(
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
)
self.conv4 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
self.conv5 = nn.Sequential(
nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
)
self.conv6 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
)
self.conv7 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
)
self.conv8 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
self.conv9 = nn.Sequential(
nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
)
self.conv10 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
)
self.conv11 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
)
self.conv12 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
self.conv13 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
)
self.conv14 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
)
self.conv15 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
)
self.conv16 = nn.Sequential(
nn.Conv2d(in_channels=512, out_channels=512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
)
self.fc17 = nn.Sequential(
nn.Linear(int(512 * img_size * img_size / 32 / 32), 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5) # 默认就是0.5
)
self.fc18 = nn.Sequential(
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5)
)
self.fc19 = nn.Sequential(
nn.Linear(4096, num_class)
)
self.conv_list = [self.conv1, self.conv2, self.conv3, self.conv4, self.conv5, self.conv6, self.conv7,
self.conv8, self.conv9, self.conv10, self.conv11, self.conv12, self.conv13, self.conv14,
self.conv15, self.conv16]
self.fc_list = [self.fc17, self.fc18, self.fc19]
print("VGG Model Initialize Successfully!")
# forward
def forward(self, x):
for conv in self.conv_list: # 16 CONV
x = conv(x)
output = x.view(x.size()[0], -1)
for fc in self.fc_list: # 3 FC
output = fc(output)
return output
if __name__ == '__main__':
vgg19 = VGG()
print(vgg19) # print model of vgg19
2 vgg_dataset.py
在PyTorch深度学习框架中提供了Dataset来对数据进行加载,通过继承Dataset类得到MyDataset类,我们可以实现对自己数据集的加载。继承的类需要重写init、len、getitem。其代码结构如下:
class MyDataset(Dataset):
def __init__(self, type, img_size, data_dir):
# 加载数据
...
def __len__(self):
# 返回图片数量
return len(self.data_list)
def __getitem__(self, item):
...
# 返回图片数据和标签
return img, label
其中,len:返回数据内包含的数据总量,可以将所有数据的地址存储在一个列表里,返回字典的长度即刻;getitem:根据对象的索引,返回(x,y),x为图像的数据,y为标签;init:为初始化函数,根据以上len和getitem的需求,可以将每张数据图片的路径存在一个list中,方便getitem的调用。
根据需求不同,MyDataset的编写方法也不同,可以采用读取txt文本的方法获取图片的路径和类别,也可以直接读取某个目录中的所有图片。本项目中将数据集分为训练集train和测试test分别存放,通过读取不同路径分别获取训练集和测试集数据。在数据集中,图片的命名格式为class-number,如dogs-0001.jpg,所以可在文件名中提取出标签,在getitem方法中,就可以通过图片的路径读取图片获取图片数据,并根据图片的名称获得图片的类别,最后将图片数据img和标签label返回。
代码如下:
# vgg_dataset.py
import os
from PIL import Image
from torch import tensor
from torch.utils.data import Dataset
from torchvision.transforms import ToTensor
class MyDataset(Dataset):
def __init__(self, type, img_size, data_dir):
self.name2label = {"cats": 0, "dogs": 1, "panda": 2}
self.img_size = img_size
self.data_dir = data_dir
self.data_list = list()
for file in os.listdir(self.data_dir):
self.data_list.append(os.path.join(self.data_dir, file))
print("Load {} Data Successfully!".format(type))
def __len__(self):
return len(self.data_list)
def __getitem__(self, item):
file = self.data_list[item]
img = Image.open(file)
if len(img.split()) == 1:
img = img.convert("RGB")
img = img.resize((self.img_size,self.img_size))
label = self.name2label[os.path.basename(file).split('_')[0]]
image_to_tensor = ToTensor()
img = image_to_tensor(img)
label = tensor(label)
return img, label
3 vgg_train.py
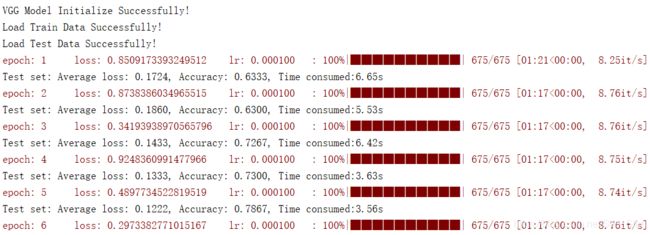
该代码用于训练分类猫、狗和熊猫图像的VGG模型,是整个项目中最重要也是最复杂的部分。可分为三大部分:训练函数train,针对每一轮epoch进行训练;验证函数val,针对每一轮epoch的训练结果进行验证计算准确率;主函数main包含以下功能:初始化参数、初始化模型、加载数据、设置损失函数、设置优化器、调用tensorboard、循环epochs进行训练并验证、保存准确率最高的模型。
在主函数中,首先通过argparse.ArgumentParser()对训练程序的默认参数进行配置,其中包括:训练集路径、测试集路径、图像尺寸、类别数目、训练模型保存路径,batch-size、epochs、学习率、学习率衰减周期、是否使用GPU、是否使用Tensorboard。设置好参数后,调用vgg-model.py中已经定义好的vgg模型进行模型的初始化,并根据是否使用GPU设置模型中参数的类型。然后,通过调用vgg-dataset.py中MyDataset创建数据集对象,包括训练集和测试集,并使用DataLoader加载数据,加载数据时可以设置batch-szie、是否乱序等属性。接下来,设置损失函数、优化器,损失函数选择交叉熵,可直接调用函数torch.nn.CrossEntropyLoss();优化器使用SGD,可直接调函数用torch.optim.SGD()并设置优化网络参数、设置学习率为0.0001,并分别在50%、80%和90%epoch处降低学习率为原值的0.1倍。最后通过For循环进行训练,代码流程如下:
for epoch in range(1, epochs + 1):
train(epoch, pbar) # 训练
loss, acc = val() # 验证
...
# 记录准确率,保存最好的模型
在train函数中,首先使用net.train()命令,表示在使用模型的时启用Batch Normalization和Dropout。然后,通过for循环输入每一batch的数据进行训练、计算损失函数、进行反向传播优化模型。在eval函数中,首先使用net.eval()命令,表示在使用模型的时不启用Batch Normalization和Dropout,通过将测试集数据批量输入模型中计算出总的损失函数和正确率,实时反馈模型的训练效果。
项目采用Kaggle中的动物数据集,共包含3000张图片,含有3类目标:猫、狗和熊猫,每类数据有1000张。设置训练集为2700张图片,包含猫、狗和熊猫3类动物各900张。数据集下载链接:https://www.kaggle.com/ashishsaxena2209/animal-image-datasetdog-cat-and-panda
据多次训练中loss曲线和准确率曲线的变化最终设置epochs为50;受限于GPU的显存,设置batchszie为4。受限于GPU的显存,和模型的参数设置,最终设置输入模型的尺寸为128$\times 128 , 也就是说,输入模型的图片首先要 r e s i z e 为 128 128,也就是说,输入模型的图片首先要resize为128 128,也就是说,输入模型的图片首先要resize为128\times$128;经过多次的调试,最终设置学习率为0.0001,学习率分别在25、40、45epoch降低为原值的0.1。
# vgg_train.py
import os
import time
import torch
import logging
import argparse
import vgg_model, vgg_dataset
from tqdm import tqdm
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
logger = logging.getLogger(__name__)
# train each epoch
def train(epoch, pbar):
net.train()
# start batch
for step, (images, labels) in pbar:
if opt.gpu:
images, labels = images.cuda(), labels.cuda()
optimizer.zero_grad()
outputs = net(images)
loss = loss_function(outputs, labels)
loss.backward()
optimizer.step()
train_scheduler.step()
# print(train_scheduler.get_lr()[-1])
s = ('epoch: %d\t loss: %10s\t lr: %6f\t' % (epoch, loss.item(), train_scheduler.get_last_lr()[-1]))
pbar.set_description(s)
# end batch
def val():
start = time.time()
net.eval()
test_loss = 0.0 # cost function error
correct = 0.0
for (images, labels) in test_loader:
if opt.gpu:
images = images.cuda()
labels = labels.cuda()
outputs = net(images)
loss = loss_function(outputs, labels)
test_loss += loss.item()
_, preds = outputs.max(1)
correct += preds.eq(labels).sum()
finish = time.time()
test_loss = test_loss / len(test_loader.dataset)
test_acc = correct.float() / len(test_loader.dataset)
print('Test set: Average loss: {:.4f}, Accuracy: {:.4f}, Time consumed:{:.2f}s'.format(
test_loss,
test_acc,
finish - start
))
return test_loss, test_acc
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-train_path', type=str, default="F:\\Course\\9-Artificial Intelligence\\code\\dataset\\train", help='train images dir')
parser.add_argument('-test_path', type=str, default="F:\\Course\\9-Artificial Intelligence\\code\\dataset\\test", help='test images dir')
parser.add_argument('-img_size', type=int, default=128, help='the size of image, mutiple of 32')
parser.add_argument('-num_class', type=int, default=3, help='the number of class')
parser.add_argument('-checkpoint_path', type=str, default="checkpoint", help='path to save model')
parser.add_argument('-batch_size', type=int, default=4, help='batch size for dataloader')
parser.add_argument('-epochs', type=int, default=50, help='epochs')
parser.add_argument('-milestones', type=float, default=[0.5, 0.8, 0.9], help='milestones')
parser.add_argument('-gpu', default=True, help='use gpu or not')
parser.add_argument('-warm', type=int, default=1, help='warm up training phase')
parser.add_argument('-lr', type=float, default=1e-4, help='initial learning rate of optimizer')
parser.add_argument('-tensorboard', default=True, help='use tensorboard or not')
opt = parser.parse_args()
# initialize vgg
if opt.gpu:
net = vgg_model.VGG(img_size=opt.img_size, input_channel=3, num_class=opt.num_class).cuda()
else:
net = vgg_model.VGG(img_size=opt.img_size, input_channel=3, num_class=opt.num_class)
# load data
train_dataset = vgg_dataset.MyDataset("Train", opt.img_size, opt.train_path)
test_dataset = vgg_dataset.MyDataset("Test", opt.img_size, opt.test_path)
train_loader = DataLoader(train_dataset, batch_size=opt.batch_size, num_workers=2, shuffle=True) # Reference https://blog.csdn.net/zw__chen/article/details/82806900
test_loader = DataLoader(test_dataset, batch_size=opt.batch_size, num_workers=2, shuffle=True)
nb = len(train_dataset)
# Optimzer
loss_function = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), lr=opt.lr, momentum=0.9, weight_decay=5e-4)
train_scheduler = torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones=opt.epochs * opt.milestones, gamma=0.1) # learning rate decay
# checkpoint
if not os.path.exists(opt.checkpoint_path):
os.makedirs(opt.checkpoint_path)
checkpoint_path = os.path.join(opt.checkpoint_path, 'epoch_{epoch}-{type}-acc_{acc}.pth')
# tensorboard
if opt.tensorboard:
writer = SummaryWriter(log_dir=opt.checkpoint_path)
# Start train
best_acc = 0.0
for epoch in range(1, opt.epochs + 1):
pbar = tqdm(enumerate(train_loader), total=int(nb / opt.batch_size)) # process_bar
train(epoch, pbar) # train 1 epoch
loss, acc = val() # valuation
if opt.tensorboard:
writer.add_scalar('Test/Average loss', loss, epoch)
writer.add_scalar('Test/Accuracy', acc, epoch)
if epoch > opt.epochs * opt.milestones[1] and best_acc < acc:
weights_path = checkpoint_path.format(epoch=epoch, type='best', acc=acc)
print('saving weights file to {}'.format(weights_path))
torch.save(net.state_dict(), weights_path)
best_acc = acc
continue
if epoch == opt.epochs+1:
weights_path = checkpoint_path.format(epoch=epoch, type='regular', acc=acc)
print('saving weights file to {}'.format(weights_path))
torch.save(net.state_dict(), weights_path)
# end epoch
4 vgg_test.py
# vgg_test.py
import time
import torch
import argparse
import vgg_model, vgg_dataset
from torch.utils.data import DataLoader
def val(test_loader):
start = time.time()
net.eval()
test_loss = 0.0 # cost function error
correct = 0.0
for (images, labels) in test_loader:
if opt.gpu:
images = images.cuda()
labels = labels.cuda()
outputs = net(images)
_, preds = outputs.max(1)
correct += preds.eq(labels).sum()
finish = time.time()
test_acc = correct.float() / len(test_loader.dataset)
print('Test set: Accuracy: {:.4f}, Time consumed:{:.2f}s'.format(
test_acc,
finish - start
))
return test_loss, test_acc
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-img_path', type=str, default="F:\\Course\\9-Artificial Intelligence\\code\\dataset\\test", help='images path')
parser.add_argument('-model_path', type=str, default="checkpoint\\epoch_41-best-acc_0.8600000143051147.pth", help='model path')
parser.add_argument('-img_size', type=int, default=128, help='the size of image, mutiple of 32')
parser.add_argument('-num_class', type=int, default=3, help='the number of class')
parser.add_argument('-gpu', default=True, help='use gpu or not')
opt = parser.parse_args()
# initialize vgg
if opt.gpu:
net = vgg_model.VGG(img_size=opt.img_size, input_channel=3, num_class=opt.num_class).cuda()
else:
net = vgg_model.VGG(img_size=opt.img_size, input_channel=3, num_class=opt.num_class)
# load model data
net.load_state_dict(torch.load(opt.model_path))
net.eval()
test_dataset = vgg_dataset.MyDataset("Test", opt.img_size, opt.img_path)
test_loader = DataLoader(test_dataset, shuffle=True)
val(test_loader)
5 vgg_classify.pt
# vgg_classify.py
import torch
import argparse
import vgg_model
from PIL import Image
from torchvision.transforms import ToTensor
class_names = ["cats", "dogs", "panda"]
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-img_path', type=str, default="F:\\Course\\9-Artificial Intelligence\\code\\dataset\\image\\dog.jpg", help='images path')
parser.add_argument('-model_path', type=str, default="checkpoint\\epoch_41-best-acc_0.8600000143051147.pth", help='model path')
parser.add_argument('-img_size', type=int, default=128, help='the size of image, mutiple of 32')
parser.add_argument('-num_class', type=int, default=3, help='the number of class')
parser.add_argument('-gpu', default=True, help='use gpu or not')
opt = parser.parse_args()
# initialize vgg
if opt.gpu:
net = vgg_model.VGG(img_size=opt.img_size, input_channel=3, num_class=opt.num_class).cuda()
else:
net = vgg_model.VGG(img_size=opt.img_size, input_channel=3, num_class=opt.num_class)
# load model data
net.load_state_dict(torch.load(opt.model_path))
net.eval()
img = Image.open(opt.img_path)
if len(img.split()) == 1:
img = img.convert("RGB")
img = img.resize((opt.img_size, opt.img_size))
image_to_tensor = ToTensor()
img = image_to_tensor(img)
img = img.unsqueeze(0)
if opt.gpu:
img = img.cuda()
output = net(img)
_, indices = torch.max(output, 1)
percentage = torch.nn.functional.softmax(output, dim=1)[0] * 100
perc = percentage[int(indices)].item()
result = class_names[indices]
print('predicted:', result)