RetinaNet详细解读
| 网络名称 | RetinaNet |
|---|---|
| 发表时间 | 2018年1月 |
| 作者 | Tsung-Yi Lin, Priya Goyal, Ross Girshick, Kaiming He, and Piotr Dollar |
| 机构 | Facebook AI Research (FAIR) |
| 领域 | 目标检测(object detection) |
| 简介 | 使用Focal Loss解决样本不均衡问题,让one-stage网络达到two-stage的精度。 |
简介
针对one stage网络中类别不均衡问题,本文作者提出一种新的损失函数:Focal Loss,这个损失函数是在标准交叉熵损失基础上修改得到的。这个函数可以通过减少易分类样本的权重,使得模型在训练时更专注于稀疏的难分类的样本;防止大量易分类负样本在训练中压垮检测器。为了证明focal loss的有效性,作者设计了一个dense detector:RetinaNet,并且在训练时采用focal loss训练。实验证明RetinaNet不仅可以达到one-stage detector的速度,也能超过现有two-stage detector的准确率。
背景
Object detection算法主要可以分为两大类:two-stage detector和one-stage detector。前者是指类似Faster RCNN,RFCN这样需要region proposal的检测算法,这类算法可以达到很高的准确率,但是速度较慢。虽然可以通过减少proposal的数量或降低输入图像的分辨率等方式达到提速,但是速度并没有质的提升。后者是指类似YOLO,SSD这样不需要region proposal,直接回归的检测算法,这类算法速度很快,但是准确率不如前者。研究发现正负样本极不均衡是主要原因。
Focal Loss
对于二分类问题交叉熵函数如下所示:
C E = − y l o g ( p ) − ( 1 − y ) l o g ( 1 − p ) ( 1 ) CE = -ylog(p)-(1-y)log(1-p) \qquad\qquad\qquad\qquad\qquad (1) CE=−ylog(p)−(1−y)log(1−p)(1)
式子中 y y y代表ground truth真实值标签, p p p代表预测结果为正的概率。
可以改写为
p t = { p i f y = 1 1 − p o t h e r w i s e . ( 2 ) p_{t} = \begin{cases}p & if \space y = 1 \\1-p & otherwise. \end{cases} \qquad\qquad\qquad\qquad\qquad\qquad\qquad (2) pt={p1−pif y=1otherwise.(2)
C E ( p , y ) = C E ( p t ) = − l o g ( p t ) ( 3 ) CE(p, y) = CE(p_t) = -log(p_t) \qquad\qquad\qquad\qquad\qquad\qquad (3) CE(p,y)=CE(pt)=−log(pt)(3)
对于交叉熵函数来说,正例和反例对于loss的贡献是对称平衡的,而在目标检测任务中,有大量的反例(背景像素),尽管每一个像素的准确率都很高,但是由于反例较多,导致整体的loss较高。举个例子,假设背景的预测的概率都为0.1,前景预测的出的概率都为0.9,而背景像素点数量与前景数量比为100:1,那么整体的loss为 -100 * log(1-0.1) - 1 * log(0.9),那么对于loss来说背景贡献了100/101的loss,所以该网络模型会更加注重背景的预测准确,而忽略了前景的情况。Focal Loss则是将那些容易被看出是前景或者背景的例子不做loss的贡献,而关心相对不准的样例。
而Focal Loss公式如下:
F L = − ( 1 − p t ) γ l o g ( p t ) ( 4 ) FL = -(1-p_{t})^{\gamma} log(p_{t}) \qquad\qquad\qquad\qquad\qquad\qquad\qquad (4) FL=−(1−pt)γlog(pt)(4)
其中 γ \gamma γ称为聚焦参数,越大代表易分类样本的权重越低,实验发现 γ = 2 \gamma = 2 γ=2效果最好。
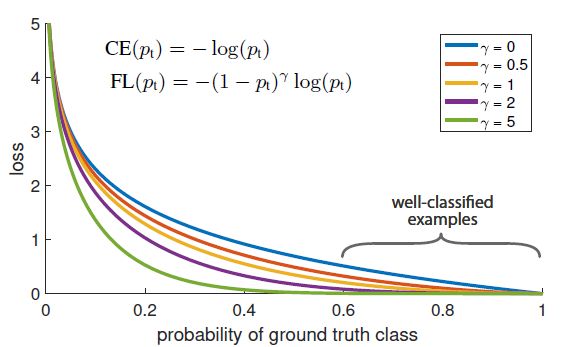
图1 不同条件因子下Focal Loss曲线
直观的,调节因子降低易分类样本的权重,并扩展的样本低损失值的区间。
例如: γ = 2 \gamma = 2 γ=2下,如果易分类样本的 p t p_t pt比CE的损失函数值小100倍,如果 p t ≈ 0.968 p_t \approx 0.968 pt≈0.968则小1000倍。这种操作反向增加了纠正错分类样本的重要性。
同时在最后,Focal Loss增加了使用一个 α \alpha α平衡变量。因为这种形式可以轻微的提升精确性。最终,在损失函数层组合sigmoid操作计算 p t p_t pt,获取更好的数值稳定性。最终Focal Loss公式如下:
F L = − α t ( 1 − p t ) γ l o g ( p t ) ( 4 ) FL = -\alpha^t(1-p_{t})^{\gamma} log(p_{t}) \qquad\qquad\qquad\qquad\qquad\qquad\qquad (4) FL=−αt(1−pt)γlog(pt)(4)
在论文中作者指出Focal Loss可以有很多种变形新式,只要目的是为了平滑较低易识别样本的贡献的loss函数都可以达到不错的精度,所以公式的具体形式不是重点,重点是具体的思想。
RetinaNet
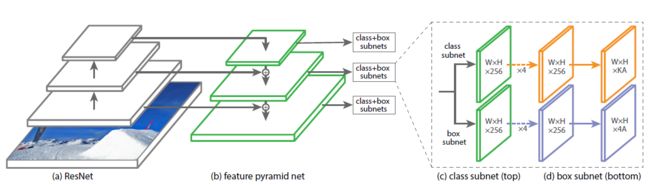
图2 RetinaNet网络结构
- ResNet+FPN:提取图片特征
- Anchor:边框搜索
- Class subnet (Focal Loss):预测类别
- Box subnet:预测边框坐标和大小
性能结果
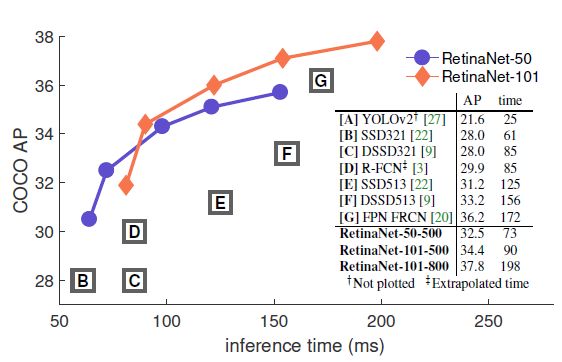
图3 COCO测试集性能结果对比1

图4 COCO测试集性能结果对比2
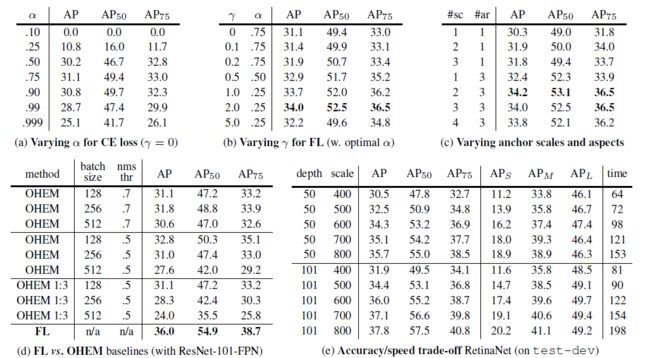
图5 Focal Loss实验性能对比
扩展
论文地址:https://arxiv.org/pdf/1708.02002.pdf
开源代码:https://github.com/yhenon/pytorch-retinanet
样本不平衡问题:https://zhuanlan.zhihu.com/p/59910080