Tensorflow教程
前言
1、TensorFlow 是由 Google Brain 团队为深度神经网络(DNN)开发的功能强大的开源软件库;
2、TensorFlow 允许将深度神经网络的计算部署到任意数量的 CPU 或 GPU 的服务器、PC 或移动设备上,且只利用一个 TensorFlow API。
3、那 TensorFlow 与其他深度学习库,如 Torch、Theano、Caffe 和 MxNet的区别在哪里呢?
包括 TensorFlow 在内的大多数深度学习库能够自动求导(自动求导 (Automatic Differentiation, AD) - 秦时明月0515 - 博客园)、开源、支持多种 CPU/GPU、拥有预训练模型,并支持常用的NN架构,如递归神经网络(RNN)、卷积神经网络(CNN)和深度置信网络(DBN)。
TensorFlow程序
import tensorflow as tf
message = tf.constant('Hello World!')
with tf.session() as sess:
print(sess.run(message).decode())tf.session()用法:TensorFlow:tf.Session函数_w3cschool
tf.constant()用法:tf.constant(常量)_bestrivern的博客-CSDN博客_tf.constant
Python decode() 方法:Python decode()方法 | 菜鸟教程
TensorFlow 程序解读分析
前面的代码分为以下三个主要部分:
1、 import 模块包含代码将使用的所有库,在目前的代码中只使用 TensorFlow,import tensorflow as tf 则允许 Python 访问 TensorFlow 所有的类、方法和符号。
2、包含图形定义部分...创建想要的计算图。在本例中计算图只有一个节点,tensor 常量消息由字符串“Welcome to the exciting world of Deep Neural Networks”构成。
3、是通过会话执行计算图,这部分使用 with 关键字创建了会话,最后在会话中执行以上计算图。
TensorFlow程序结构(深度剖析)
TensorFlow程序结构(深度剖析)
TensorFlow常量、变量和占位符详解
TensorFlow常量、变量和占位符详解
1、tensorflow常量
#Tensorflow常量举例:
zero_t=tf.zeros([2,3],tf.int32)#创立一个2*3的所有元素都是0的张量
ones_t = tf.ones([2,3],tf.int32)#全部元素都是1TensorFlow 允许创建具有不同分布的随机张量,也可以随机裁剪张量为指定的大小。
tensorflow参数—seed:如果设置了seed的值,则每次执行程序所产生的随机数或者随机序列均相等,即都为同一个随机数或者随机序列;如果没有设置seed参数的取值,那么每次执行程序所产生的随机数或者随机序列均不等。浅析tensorflow的种子(seed)参数_Legolas~的博客-CSDN博客_tensorflow随机数种子
tensorflow参数—mean:均值(默认为0),stddev:标准差(默认为1.0)。
2、tensorflow变量
#两者将被初始化为形状为 [50,50] 的随机均匀分布,最小值=0,最大值=10
rand=tf.random_uniform([50,50],0,10,seed=0)
rand_a=tf.Variable(rand)
rand_b=tf.Variable(rand)
#定义权重和偏置
weight=tf.Variable(tf.random_normal([100,100],stddev=2))
bias=tf.Variable(tf.zeros[100],name='biases')
#法一:在计算图的定义中通过声明初始化操作对象来实现
sess=tf.session()
init_op=tf.globle_variables_initializer()
sess.run(init_op)
#法二:每个变量也可以在运行图中单独使用 tf.Variable.initializer 来初始化
with tf.session() as sess:
sess.run(bias.initializer)
注意:
变量通常在神经网络中表示权重和偏置。
变量的定义将指定变量如何被初始化,但必须(在计算或者运行中)显式初始化所有的声明变量。
所有常量、变量和占位符在代码的计算图部分中定义。如果在定义部分使用 print 语句,只会得到有关张量类型的信息,而不是它的值。(要用session会话对需要提取的张量显式使用运行命令)
3、TensorFlow 占位符——它们用于将数据提供给计算图
#在这里,为 x 定义一个占位符并计算 y=2*x,使用 feed_dict 输入一个随机的 4×5 矩阵:
x=tf.placeholder("float")
y=x*2
data=tf.random_uniform([4,5],10)
with session() as sess:
x_data=sess.run(data)
print(sess.run(y,feed_dict={x:x_data})补充:很多时候需要大规模的常量张量对象,在这种情况下,为了优化内存,最好将它们声明为一个可训练标志设置为 False 的变量,如
t_large=tf.Variable(large_array,trainable=False)TensorFlow矩阵基本操作及其实现
import tensorflow as tf
#开始一个交互式对话
sess=tf.InteractiveSession()
#创建一个5*5的对角为1单位矩阵
matrix=tf.eye(5)
print(matrix.eval())
#创建一个10*10的对角为1单位矩阵变量
Matrix=tf.Variable(tf.eye(10))
Matrix.initilizer.run()
print(Matrix.eval())
#创建一个5*10的随机矩阵
matrix_t=tf.Variable(tf.random_normal([5,10]))
matrix_t.initilizer.run()
#两个矩阵相乘
product=tf.matmul(matrix_t,Matrix)
print(product.eval())
#类型转换
Matrix_t=tf.Variable(tf.random_uniform([5,10],0,2,dtype=tf.int32))
Matrix_t.initlizer.run()
print(Matrix_t.eval())
Matrix_tnew=tf.cast(Matrix_t,dtype=tf.float32)
#两矩阵相加
sum=tf.add(product,Matrix_tnew)
print("sum=",sum.eval())
#其他情况
a=tf.Variable(tf.random_normal([4,5],stddev=2))
b=tf.Variable(tf.random_normal([4,5],stddev=2))
A=a*b
B=tf.scalar_mul(2,A)
C=tf.div(a,b)
D=tf.mod(a,b)
init_op=tf.globle_variables_initilizer()
with tf.session() as sess
sess.run(init_op)
write=tf.summary.FileWrite('graphs',sess.graph)
A_,B_,C_,D_=sess.run([A,B,C,D])
print("A=",A_,"\nB=",B_)
writer.close() #需要close才能保存计算图
tf.InteractiveSession()与tf.Session()的区别_XerCis的博客-CSDN博客
Tensorflow.js tf.eye()用法及代码示例 - 纯净天空
tf.random_uniform()_永久的悔的博客-CSDN博客_tf.random_uniform
tf.multiply()、tf.matmul()、tf.scalar_mul()函数介绍和示例_痴迷、淡然~的博客-CSDN博客
TensorFlow四则运算之除法:tf.divide()_凝眸伏笔的博客-CSDN博客_tf.divide
tf.summary.FileWriter用法_小小码农JACK的博客-CSDN博客_tf.summary.filewriter
如果在整数张量之间进行除法,最好使用 tf.truediv(a,b),因为它首先将整数张量转换为浮点类,然后再执行按位相除。
TensorFlow TensorBoard可视化数据流—提供计算图的图像
TensorBoard 的第一步是确定想要的 OP 摘要。
以 DNN 为例,通常需要知道损失项(目标函数)如何随时间变化。
import tensorflow.compat.v1 as tf
# 定义两个变量
a = tf.placeholder(dtype=tf.float32, shape=[])
b = tf.placeholder(dtype=tf.float32, shape=[])
#添加变量进去,确定想要的摘要
tf.summary.scalar('a', a)
tf.summary.scalar('b', b)
# 将所有summary全部保存到磁盘,以便tensorboard显示
# 摘要将在会话操作中生成,可以在计算图中定义tf.merge_all_summaries OP 一步操作得到摘要,而不需要单独执行每个摘要操作。
smy = tf.summary.merge_all()
#初始化全局变量
init_op = tf.global_variables_initializer()
with tf.Session() as sess:
# 初始化变量
sess.run(init_op)
#把信息存储在具体的文件夹里面
writer = tf.summary.FileWriter("tf_summary_FILE", sess.graph)
#赋值
for i in range(5):
sumers=sess.run(smy,feed_dict={a:i+9,b:i+2})
#把步骤都记录下来
writer.add_summary(summary=sumers,global_step=i)
Python—tf.summary.scalar()用法_noedn的博客-CSDN博客_tf.summary.scalar(
还可以使用 tf.summary.histogram 可视化梯度、权重或特定层的输出分布:
output_tensor=tf.matmul(input_tensor,weights)+biases
tf.summary.histogram('output',output_tensor)TensorFlow XLA加速线性代数编译器
加速线性代数器(Accelerated linear algebra,XLA)是线性代数领域的专用编译器,用于优化Tensorflow计算。XLA 可以提高服务器和移动平台的执行速度、内存使用率和可移植性。
TensorFlow指定CPU和GPU设备操作
TensorFlow支持 CPU 和 GPU,也支持分布式计算。可以在一个或多个计算机系统的多个设备上使用 TensorFlow。
TensorFlow 将支持的 CPU 设备命名为“/device:CPU:0”(或“/cpu:0”),第 i 个 GPU 设备命名为“/device:GPU:I”(或“/gpu:I”)。
GPU 比 CPU 要快得多,因为它们有许多小的内核。然而,在所有类型的计算中都使用 GPU 也并不一定都有速度上的优势。为了解决这个问题,TensorFlow 可以选择将计算放在一个特定的设备上。默认情况下,如果 CPU 和 GPU 都存在,TensorFlow 会优先考虑 GPU。
1、验证 TensorFlow 是否确实在使用指定的设备(CPU 或 GPU),可以创建会话,并将 log_device_placement 标志设置为 True。
如果不确定设备,并希望 TensorFlow 选择现有和受支持的设备,则可以将 allow_soft_placement 标志设置为 True:即:
config=tf.ConfigProto(allow_soft_placement=True,log_device_placement=True)
2、手动选择 CPU 进行操作
#手动选择 CPU 进行操作
with tf.device('/cpu:0'):
rand=tf.random_uniform([50,50],0,10,dtype=tf.float32,seed=0)
a=tf.Variable(rand)
b=tf.Variable(rand)
c=tf.matmul(a,b)
init=tf.global_variables_initilizer()
#创建会话
sess=tf.Session(config)
sess.run(init)
print(sess.run(c))3、手动选择一个 GPU 来操作(同理)
with tf.device('/gpu:0'):
rand=tf.random_uniform([50,50],0,10,dtype=tf.float32,seed=0)
a=tf.Variable(rand)
b=tf.Variable(rand)
c=tf.matmul(a,b)
init=tf.global_variables_initilizer()
#创建会话
sess=tf.Session(config=tf.ConfigProto(lod_device_placement=True))
sess.run(init)
print(sess.run(c))4、手动选择多个GPU
c=[]
#多个GPU
for d in ['/gpu:1','/gpu:2']:
with tf.device(d):
rand=tf.random_uniform([50,50],0,10,dtype=tf.float32,seed=0)
a=tf.Variable(rand)
b=tf.Variable(rand)
c.append(tf.matmul(a,b))#在张量的末尾添加新的对象
init=tf.global_variables_initilizer()
#创建会话
sess=tf.Session(config=tf.ConfigProto(allow_soft_placement=True,lod_device_placement=True))
sess.run(init)
print(sess.run(c))
sess.close()
#若系统有3个GPU 设备,那第一组乘法由'/:gpu:1'执行,第二组乘法由'/gpu:2'执行。- 函数 tf.device() 选择设备(CPU 或 GPU)。
- with 块确保设备被选择并用其操作。with 块中定义的变量、常量、操作将用所选择的设备。
- 会话配置使用 tf.ConfigProto 进行控制。通过设置 allow_soft_placement 和 log_device_placement 标志,告诉 TensorFlow 在指定的设备不可用时自动选择可用的设备,并在执行会话时给出日志消息作为描述设备分配的输出,如下图。
![]()
浅谈深度学习之TensorFlow
在这里介绍基础知识,并探讨 TensorFlow 的哪些特性使其成为深度学习的热门选择。
1、神经网络是一个生物启发式的计算和学习模型。像生物神经元一样,它们从其他细胞(神经元或环境)获得加权输入。这个加权输入经过一个处理单元并产生可以是二进制或连续(概率,预测)的输出。
2、人工神经网络(ANN)是这些神经元的网络,可以随机分布或排列成一个分层结构。这些神经元通过与它们相关的一组权重和偏置来学习。
3、深度学习(https://www.cs.toronto.edu/~hinton/absps/NatureDeepReview.pdf)是由多个处理层(隐藏层)组成的计算模型。层数的增加会导致学习时间的增加。由于数据量庞大,学习时间进一步增加,现今的卷积神经网络(CNN)或生成对抗网络(GAN)的规范也是如此。为了实现 DNN,需要高计算能力。NVDIA 公司 GPU 的问世使其变得可行,随后 Google 的 TensorFlow 使得实现复杂的 DNN 结构成为可能,而不需要深入复杂的数学细节,大数据集的可用性为 DNN 提供了必要的数据来源。
4、任何深度学习网络都由四个重要部分组成:数据集、定义模型(网络结构)、训练/学习和预测/评估。可以在 TensorFlow 中实现所有这些。
TensorFlow 成为最受欢迎的深度学习库,原因如下:
- TensorFlow 是一个强大的库,用于执行大规模的数值计算,如矩阵乘法或自动微分。这两个计算是实现和训练 DNN 所必需的。
- TensorFlow 在后端使用 C/C++,这使得计算速度更快。
- TensorFlow 有一个高级机器学习 API(tf.contrib.learn),可以更容易地配置、训练和评估大量的机器学习模型。
- 可以在 TensorFlow 上使用高级深度学习库 Keras。Keras 非常便于用户使用,并且可以轻松快速地进行原型设计。它支持各种 DNN,如RNN、CNN,甚至是两者的组合。
5、数据集
TensorFlow 支持三种主要的读取数据的方法,可以在不同的数据集中使用。
- 通过feed_dict传递数据;
- 从文件中读取数据;
- 使用预加载的数据;
1)通过feed_dict传递数据
运行每个步骤时都会使用 run() 或 eval() 函数调用 feed_dict 中的参数来提供数据。这是在占位符的帮助下完成的,这个方法允许传递 Numpy 数组数据。
使用占位符,在 feed_dict 的帮助下传递包含 X 值的数组和包含 Y 值的数组。
x=tf.placeholder(tf.float32)
y=tf.placeholder(tf.float32)
with tf.Session as sess:
X_Array=some Numpy Array
Y_Array=some Numpy Array
loss=...#计算loss值
sess.run(loss,feed_dict={x:X_Array,y:Y_Array})
2)通过文件读取
当数据集非常大时,使用此方法可以确保不是所有数据都立即占用内存。
TensorFlow提供了tf.train.match_filenames_once函数来获取符合一个正则表达式的所有文件,得到的文件列表可以通过tf.train.string_input_producer函数来进行有效管理。
#创建文件命名列表
files=tf.train.match_filenames_once('*.JPG')
#创建一个队列来保存文件名
filename_queue=tf.train.string_input_producer(files)
#选择对应的文件阅读器,从文件名队列中读取文件
reader=tf.TextLinerReader()
key,value=reader.read(filename_queue)#读取队列中文件元素下标和值
#使用一个或多个解码器和转换操作,将值字符串解码为训练样本的张量
# record_defaults:指定每一个样本的每一列的类型和默认值
record=[[1],[1],[1]] #字符串格式
col1,col2,col3=tf.decode_csv(value,record_defaults=record)使用tf.train.match_filenames_once()时报错FailedPreconditionError: Attempting to use uninitialized value X_qq_41707764的博客-CSDN博客
TensorFlow输入文件队列_dz4543的博客-CSDN博客
Python TensorFlow,读取文件流程,读取CSV文件案例,TextLineReader()_houyanhua1的博客-CSDN博客
TensorFlow之数据读取_AI小白一枚的博客-CSDN博客
3)预数据加载
#常量
training_data = ...
training_labels = ...
with tf.Session() as sess:
input_data = tf.constant(training_data)
input_labels = tf.constant(training_labels)
#变量
training_data = ...
training_labels = ...
with tf.Session() as sess:
data_initializer = tf.placeholder(dtype=training_data.dtype,shape=training_data.shape)
label_initializer=tf.placeholder(dtype=training_labels.dtype,shape=training_labels.shape)
input_data = tf.Variable(data_initalizer, trainable=False, collections=[])
input_labels = tf.Variable(label_initalizer, trainable=False, collections=[])
...
sess.run(input_data.initializer,feed_dict={data_initializer: training_data})
sess.run(input_labels.initializer,feed_dict={label_initializer: training_lables})6、定义模型
建立描述网络结构的计算图。它涉及指定信息从一组神经元到另一组神经元的超参数、变量和占位符序列以及损失/错误函数。
7、训练/学习
在 DNN 中的学习通常基于梯度下降算法,其目的是要找到训练变量(权重/偏置),将损失/错误函数最小化。这是通过初始化变量并使用 run() 来实现的。
8、评估模型
通过 predict() 函数使用验证数据和测试数据来评估网络。这可以评价模型是否适合相应数据集,可以避免过拟合或欠拟合的问题。一旦模型取得让人满意的精度,就可以部署在生产环境中了。
一般来说,数据被分为三部分:训练数据、验证数据和测试数据。
常用的三种回归算法
1、线性回归:
- 简单线性回归(一个输入变量,一个输出变量)
- 多元线性回归(多个输入变量,一个输出变量)
- 多变量线性回归(多个输入变量,多个输出变量)
2、逻辑回归:
用来确定一个事件的概率。事件可被表示为类别因变量,‘事件的概率用 logit 函数表示。
目标是估计权重 W=(w1,w2,...,wn) 和偏置项 b。在逻辑回归中,使用最大似然估计量或随机梯度下降来估计系数。损失函数通常被定义为交叉熵项。
3、正则化
当有大量的输入特征时,需要正则化来确保预测模型不会太复杂。正则化可以帮助防止数据过拟合。它也可以用来获得一个凸损失函数。有两种类型的正则化——L1 和 L2 正则化。
TensorFlow损失函数
1、线性回归
#定义全局变量
m=1000
n=15
p=2
#标准线性回归
X=tf.placeholder(tf.float32,name='X')#一个输入
Y=tf.placeholder(tf.float32,name='Y')#一个输出
#定义偏置和权重
W0=tf.Variable(0.0)
W1=tf.Variable(0.0)
#线性回归模型
Y_hat=X*W0+W1
#计算loss
loss=tf.square(Y-Y_hat,name='loss')
#多元线性回归
X=tf.placeholder(tf.float32,name='X',shape=[m,n])#多个输入
Y=tf.placeholder(tf.float32,name='Y')#一个输出
W0=tf.Variable(tf.random_normal([n,1]))
W1=tf.Variable(0.0)
Y_hat=tf.matmul(X,W0)+W1
loss=tf.reduce_mean(tf.square(Y-Y_hat),name='loss')
tf.reduce_mean()函数解析(最清晰的解释)_我是管小亮的博客-CSDN博客_tf.reduce_mean
2、逻辑回归
在逻辑回归的情况下,损失函数定义为交叉熵,输出 Y 的维数等于训练数据集中类别的数量P。
X=tf.placeholder(tf.float32,name='X',shape=[m,n])
Y=tf.placeholder(tf.float32,name='Y',shape=[m,p])
W0=tf.Variable(tf.zeros([1,p]),name='bias')
W1=tf.Variable(tf.random_normal([n,1]),name='weights')
Y_hat=dtf.matmul(X*W1)+W0 #[m,p]形式
entropy=tf.nn.softmax_cross_entropy_with_logits(Y_hat,Y) #求单loss
loss=tf.redduce_mean(entropy) #求平均
【TensorFlow】tf.nn.softmax_cross_entropy_with_logits的用法_xf__mao的博客-CSDN博客
【TensorFlow】tf.nn.softmax_cross_entropy_with_logits的用法_zj360202的博客-CSDN博客
tf.nn.softmax参数详解以及作用_dovert的博客-CSDN博客_tf.softmax
3、正则化
X=tf.placeholder(tf.float32,name='X',shape=[m,n])
Y=tf.placeholder(tf.float32,name='Y',shape=[m,p])
W0=tf.Variable(tf.zeros([1,p]),name='bias')
W1=tf.Variable(tf.random_normal([n,1]),name='weights')
Y_hat=dtf.matmul(X*W1)+W0 #[m,p]形式
entropy=tf.nn.softmax_cross_entropy_with_logits(Y_hat,Y) #求单loss
loss=tf.reduce_mean(entropy) #求平均
#L1正则化
lamda=tf.constant(0.8)#系数
param=lamda*tf.reduce_sum(tf.abs(W1))#对权重张量的每个元素求和
loss+=prama #new loss
#L2正则化
lamda=tf.constant(0.8)#系数
prama=lamda*tf.nn.l2_loss(W1)#对权重张量的每一个元素平方,然后求和,最后乘1/2
loss+=prama #new loss
tf.nn.l2_loss()的用法_草尖上的舞动的博客-CSDN博客
TensorFlow优化器使用
函数在一阶导数为零的地方达到其最大值和最小值。梯度下降算法基于相同的原理,即调整系数(权重和偏置)使损失函数的梯度下降。
1、首先确定想用的优化器。
optimizer=tf.train.GradientDescentOptimizer(learning_rate=0.01)
# learning_rate 参数可以是一个常数或张量,值介于0-1之间。
#必须为优化器给定要优化的函数minimize,实现loss最小化。该方法计算梯度并将梯度应用于系数的学习。
train_step=optimizer.minimize(loss)
with tf.Session() as sess:
sess.run(train_step)梯度下降中的另一个变化是增加了动量项,如:
optimizer=tf.train.MomentumOptimizer(learning_rate=0.01,momentum=0.5).minimize(loss)2、衰减学习率
通常建议从较大学习率开始,并在学习过程中将其降低。这有助于对训练进行微调,可以使用 TensorFlow 中的 tf.train.exponential_decay 方法来实现这一点。
1)变量:
- learning_rate:标量float32或float64张量或者Python数字。初始学习率。
- global_step:标量int32或int64张量或者Python数字。指一次epoch的总共迭代次数,值是等于图像数量/batchsize,用于衰减计算的全局步数,非负。
- decay_steps:标量int32或int64张量或者Python数字。也是指迭代次数,当迭代decay_step次后,改变一次学习率,正数。
- decay_rate:标量float32或float64张量或者Python数字。衰减率。
- staircase:布尔值。若为真则以离散的间隔衰减学习率。
- name:字符串。可选的操作名。默认为ExponentialDecay。
2)返回:
- 与learning_rate类型相同的标量张量,即衰减的学习率。
global_step=tf.Variable(0,trainable=false)
initial_learning_rate=0.2
learning_rate=tf.train.exponential_decay(initial_learning_rate,global_step,decay_steps=100000,decay_rate=0.95,staircase=True)训练神经网络 | 三个基本概念:Epoch, Batch, Iteration_OnlyCoding…的博客-CSDN博客
TensorFlow实现简单线性回归
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt #绘图
#为了使训练有效,输入应该被归一化,所以定义一个函数来归一化输入数据.
def normalize(X)
mean=np.mean(X)#计算全局平均值
std=np.std(X) #计算全局标准差
X=(X-mean)/std#标准化:对原始数据进行变换到均值为0,标准差为1范围内
return X
#Boston房屋价格数据集中data即为特征变量,target为目标变量。选取data中的RM,target是MEDV变量进行单变量线性回归
#使用TensorFlow contrib数据集加载波士顿房价数据集,并将其分解为 X_train 和 Y_train。可以对数据进行归一化处理:
boston=tf.contrib.learn.datasets.load_dataset('boston')
X_train,Y_train=boston.data[:,5],boston.target #X_train第六列全部数据
X_train=normalize(X_train)
n_sample=len(X_train)
#为训练数据声明 TensorFlow 占位符:
X=tf.placeholder(tf.float32,name='X')
Y=tf.placeholder(tf.float32,name='Y')
#创建 TensorFlow 的权重和偏置变量且初始值为零:
b=tf.Variable(0.0)
w=tf.Variable(0.0)
#定义用于预测的线性回归模型
Y_hat=X*w+b
#定义损失函数
loss=tf.square(Y-Y_hat,name='loss')
#选择梯度优化器
tf.train.GredientDescentOptimizer(learning_rate=0.01).minimize(loss)
#初始化操作符:
init_op=tf.globle_variables_initializer()
total=[]
#计算图
with tf.Session() as sess:
sess.run(init_op)
writer=tf.summary.FileWriter('graphs',sess.graph)
for i in range(100):
total_loss=0
for x,y in zip(X_Train,Y_train)
_,l=sess.run([optimizer,loss],feed_dict={X:x,Y=y}) #返回一次迭代的loss为l
total_loss+=l #total_loss为总的loss值
total.append(total_loss/n_sample) #n_sample为迭代次数,这里默认为len,即batch_size=1
print('Epoch{0}:Loss{1}'.format(i,total_loss/n_sample))
writer.close()
b_value,w_value=sess.run([b,w])
#查看结果
Y_pred=X_train*w_value+b_value
pringt('done')
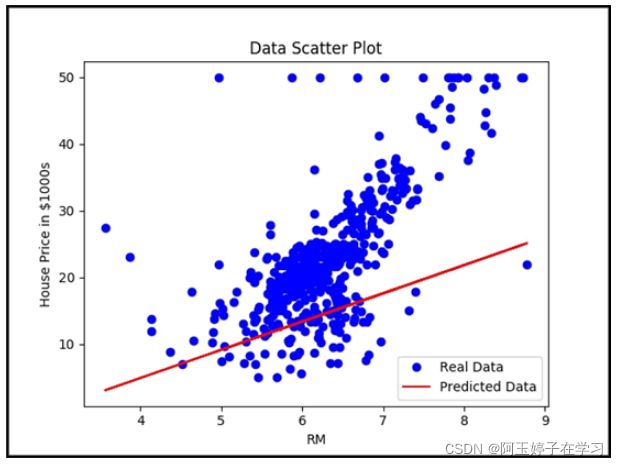
plt.plot(X_train,Y_train,label='real data')
plt.plot(X_train,Y_pred,label='predict data')
plt.legend()#给图加上图例,没有参数则根据lable自动识别
plt.show()
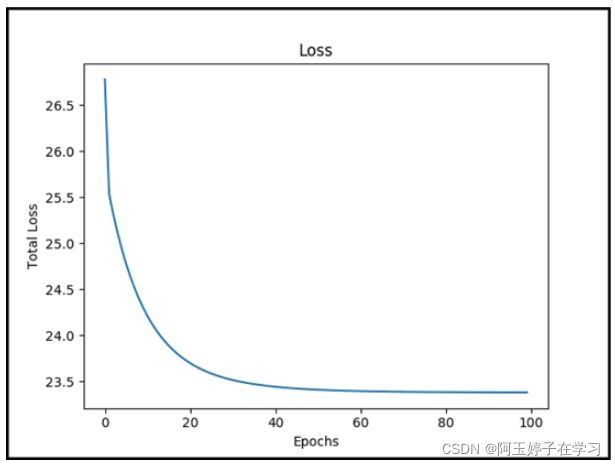
plt.plot(total)
plt.show()
2. Python数据可视化matplotlib.pyplot - 简书
data[:,0] data[1,:]的含义_Sophia要一直努力的博客-CSDN博客_data[:]
深度学习基础知识归纳 - 知乎标准化和归一化,请勿混为一谈,透彻理解数据变换_夏洛克江户川的博客-CSDN博客_标准化和归一化
CUDA、NVIDIA driver、多版本cuda - 知乎
Ubuntu下NVidia驱动、CUDA、CuDNN的安装和卸载 - 知乎
显卡,显卡驱动,nvcc, cuda driver,cudatoolkit,cudnn到底是什么? - 知乎
Pandas 库之 DataFrame - 败北桑 - 博客园
Pandas中head( )函数_Nate.li的博客-CSDN博客_head()
Python format 格式化函数 | 菜鸟教程
TensorFlow实现多元线性回归
在实现简单线性回归的基础上,可通过在权重和占位符的声明中稍作修改来对相同的数据进行多元线性回归。
简单线性回归和多元线性回归的主要不同在于权重,且系数的数量始终等于输入特征的数量。
这里是波士顿房价数据集的多重线性回归的代码,使用 3 个输入特征。由于每个特征具有不同的值范围,归一化变得至关重要。
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt #绘图
#为了使训练有效,输入应该被归一化,所以定义一个函数来归一化输入数据.
def normalize(X)
mean=np.mean(X)#计算全局平均值
std=np.std(X) #计算全局标准差
X=(X-mean)/std#标准化:对原始数据进行变换到均值为0,标准差为1范围内
return X
#这里添加一个额外的固定输入值将权重和偏置结合起来。(最好写几个矩阵看一下每行加一然后转置)
def append_bias_reshape(festures,lables):
m=features.shape[0] #获取feature的行数
n=features.sahpe[1] #获取feature的列数
x=np.reshape(np.c_[np.ones(m),features],[m,n+1])#重新组合成新的行列数目
y=np.reshape(lables,[m,1])#重新组合成新的行列数目
return x,y
#注意到X_train包含所需要的特征,可以在这里对数据进行归一化处理,也可以添加偏置并对数据重构:
boston=tf.contrib.learn.datasets.load_dataset('boston')
X_train,Y_train=boston.data,boston.target #全部数据
X_train=normalize(X_train)
X_train,Y_train=append_bias_reshape(X_train,Y_train)
m=len(X_train)#返回列表元素的个数
n=3+1
#为训练数据声明 TensorFlow 占位符。观测占位符 X 的形状变化
X=tf.placeholder(tf.float32,name='X',shape=[m,n])
Y=tf.placeholder(tf.float32,name='Y')
#通过随机数初始化权重:
w=tf.Variable(tf.random_normal([n,1]))
#定义要用于预测的线性回归模型。现在需要矩阵乘法来完成这个任务:
Y_hat=tf.matmul(X,w)
#为了更好地求微分,定义损失函数
loss=tf.reduce_mean(tf.square(Y-Y_hat,name='loss'))
#选择正确的优化器:
tf.train.GredientDescentOptimizer(learing_rate=0.01).minimize(loss)
#初始化操作符:
init_op=tf.globle_variables_initializer()
total=[]
#计算图
with tf.Session() as sess:
sess.run(init_op)
writer=tf.summary.FileWriter('graphs',sess.graph)
for i in range(100):
total_loss=0
for x,y in zip(X_Train,Y_train)
_,l=sess.run([optimizer,loss],feed_dict={X:X_train,Y=Y_train})
total_loss+=l #total_loss为总的loss值
total.append(total_loss/len) #len为一个epoch的总的迭代次数
print('Epoch{0}:Loss{1}'.format(i,total_loss/len))
writer.close()
b_value,w_value=sess.run([b,w])
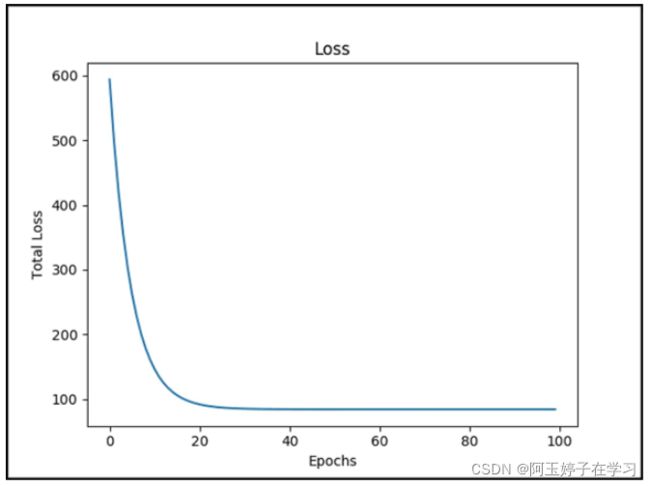
#绘制损失函数
plt.plot(total)
plt.show()
numpy np.c_[ ]和np.r_[ ]_Cao-Y的博客-CSDN博客_np.r_[]
Python中的numpy.ones()_cunchi4221的博客-CSDN博客
MNIST数据集简介
它是机器学习的基础,包含手写数字的图像及其标签来说明它是哪个数字。
MNIST数据集_/home/liupc的博客-CSDN博客_minist数据集
【TensorFlow】MNIST手写数字识别_笔尖bj的博客-CSDN博客
训练数据,验证数据和测试数据分析_浪曦007的博客-CSDN博客_测试数据 训练数据
Tensorflow常用函数
tensorflow笔记 :常用函数说明_multiangle的博客-CSDN博客
机器学习精度评价
机器学习中的F1-score__Yucen的博客-CSDN博客_f1 score
TP、True Positive 真阳性:预测为正,实际也为正
FP、False Positive 假阳性:预测为正,实际为负
FN、False Negative 假阴性:预测与负、实际为正
TN、True Negative 真阴性:预测为负、实际也为负。
Unet模型
语义分割(Semantic Segmentation)是图像处理和机器视觉一个重要分支。
与分类任务不同,语义分割需要判断图像每个像素点的类别,进行精确分割。语义分割目前在自动驾驶、自动抠图、医疗影像等领域有着比较广泛的应用。

上图为自动驾驶中的移动分割任务的分割结果
可以从一张图片中识别出汽车(深蓝色),行人(红色),红绿灯(黄色),道路(浅紫色)等。
Unet可以说是最常用、最简单的一种分割模型了,它简单、高效、易懂、容易构建、可以从小数据集中训练。
图像分割必备知识点 | Unet详解 理论+ 代码 - 忽逢桃林 - 博客园

这个结构就是先对图片进行卷积和池化;
- Unet中卷积池化4次,如开始的图片是224x224的,那就会变成112x112,56x56,28x28,14x14四个不同尺寸的特征。
- 然后我们对14x14的特征图做上采样或者反卷积,得到28x28的特征图,这个28x28的特征图与之前的28x28的特征图进行通道伤的拼接concat,然后再对拼接之后的特征图做卷积和上采样,得到56x56的特征图,再与之前的56x56的特征拼接,卷积,再上采样,经过四次上采样可以得到一个与输入图像尺寸相同的224x224的预测结果。

百度安全验证(卷积和池化)
全卷积网络 FCN 详解
全卷积网络 FCN 详解 - 知乎