Equalized Focal Loss for Dense Long Tailed Object Detection 论文解读
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
导读
对Focal Loss做了改进,使之可以在一阶段物体检测器中适用于长尾分布数据集的场景。效果提升明显。
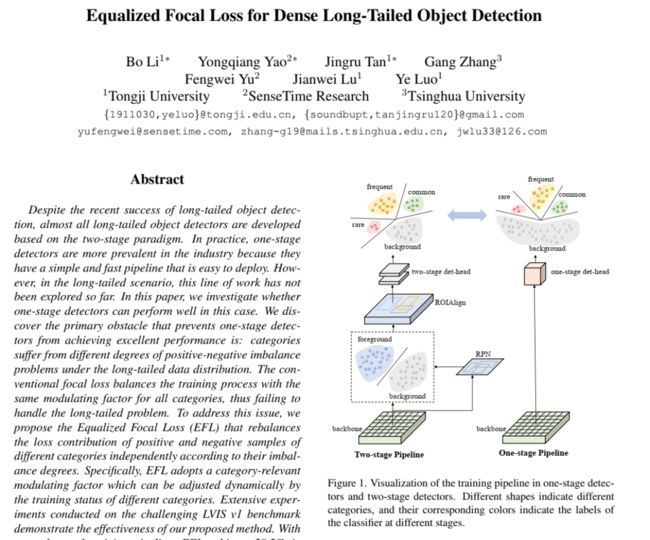
摘要:最近的长尾目标检测的方法,都是用的2阶段的模式。而在实际的工业场景中,一阶段目标检测器是更常用的,应为它更加简单,更容易部署。但是,在长尾分布的场景中,这部分的工作并没有进行很深入的探索。本文,我们研究了是否一阶段的物体检测器也可以在这个领域表现很好。我们发现了导致一阶段物体检测器表现不好的最主要的障碍:在长尾数据分布下的类别的正负样本不均衡的问题。Focal loss对于所有的loss在训练时起到了一个调节的作用,但是在长尾分布的时候,效果却不好。为了解决这个问题,我们提出了Equalized Focal Loss (EFL) ,利用不同的类别的不均衡度,分别来对正负样本的分布进行重新的均衡。具体来说,EFL利用了类别相关的调节因子来动态的调节不同类别的训练状态。实验表明,该方法可以取得显著的提升。
代码:https://github.com/ModelTC/EOD
1. 介绍
在长尾分布数据集中,几个很少的头部类别包含了大量的数据,主导了训练过程。相比之下,大量的尾部类别的实例很少。常用的长尾物体检测方法包括数据的重采样,解耦训练,和损失加权。除了这些,大部分的长尾物体检测器都是用的R-CNN的两阶段方法。而实际上,一阶段物体检测器在现实场景中更加适用。
相比于二阶段物体检测器,一阶段物体检测器本身就有前景和背景的不均衡问题,再加上长尾分布的类别间的不均衡的问题,更加了导致了performance变差。
Focal loss是解决前景和背景不均衡的一种非常方便的方法。在正常的类别分布下,效果很好,但是在长尾分布的数据下,就不是很合适了。为了解决这个问题,我们从已有的两阶段的方法EQLv2开始,想利用Focal loss在一阶段的物体检测器上解决这个问题。但是发现这些方法只在二阶段的方法上有提升。通过对比不同数据分布上的正负样本的比例。我们意识到不均衡问题的本质是不同类别正负样本的不均衡度不一样。稀少类别的正负样本不均衡度相比常见类别会更严重。
本文中,我们提出了Equalized Focal Loss (EFL) ,在focal loss中引入了类别相关的调节因子。这个调节因子使用了2个解耦的动态因子(聚焦因子和权重因子)来处理不同类别中的正负样板的不均衡问题。聚焦因子根据不同类别的不均衡度来决定学习过程中的困难正样本。采样因子用来增大稀少类别的影响。
2. 长尾目标检测
相比于通用的目标检测,长尾目标检测更加复杂,因为其受到了极度不均衡的前景类别的影响。一个直接的方法是在训练的时候通过重采样的方法来解决不均衡的问题。即对于稀少类别使用过采样,对于多数类别使用欠采样。还有人采用解耦的方式来寻检测器,提出了一个额外的分类分支,使用类别均衡的采样器在实例级别做均衡。其他还有方法通过元学习或者存储增强的方式来做数据均衡。Loss的加权也是另一种常用的方法。EQL缓和了头部类别对尾部类别的梯度压制,EQLv2使用了新的梯度导向机制来对每个类别进行重新的加权。除了数据重采样和loss加权之外,还有一些方法从不同的角度进行了尝试,比如解耦训练,margin调整,增量学习,因果推断等。但是所有这些方法都是在二阶段的检测器上使用的。本文中,我们提出了第一个一阶段检测器上的长尾目标检测的解决方案,优于现有的所有方法。
3. 方法
3.1 Focal Loss回顾
Focal loss的公式如下:
![]()
在多类的情况下,focal loss将多分类转换为多个二分类的情况来处理,因此,focal loss对于不同的类别的处理方式是一样的,因此,无法处理长尾的不均衡的问题。
3.2 Equalized Focal Loss 公式
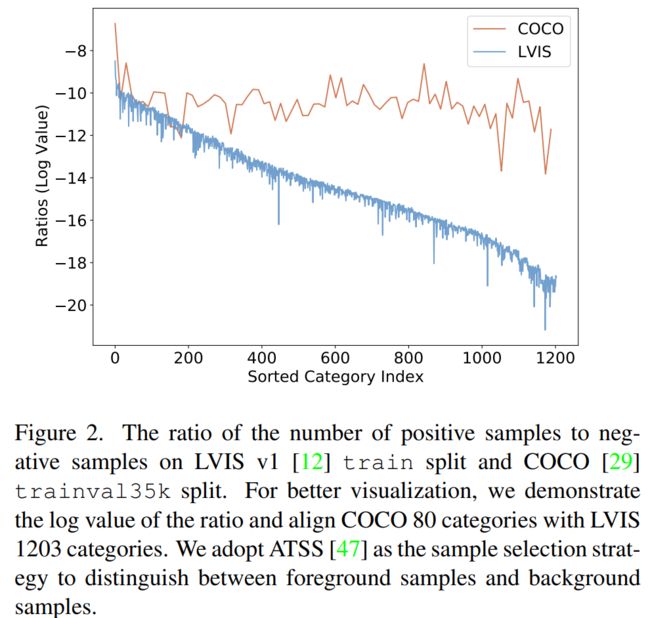
在长尾分布数据集中,除了前景和背景的不均衡,前景的类别之间也是不均衡的。如图2,我们从y轴来看,正负样本的比例远小于0,这表示了前景和背景样本的极度不均衡。我们把这个值作为正负样本的不均衡度。从x轴来看,我们可以看到类别之间的巨大差别,这表示了前景类别的不均衡性。很明显可以看出,在均衡数据集上(COCO),类别之间的不均衡性很小。因此,在focal loss中使用相同的调制因子是足够的。相比之下,长尾分布中,不同类别的前景背景的不均衡性是不一样的,越是稀少的类别,不均衡性越大。如表1所示,大部分的一阶段的物体检测器在稀少类别上的表现要差于常见类别。这也表明使用相同的调制因子是不合适的。
聚焦因子 基于上面的分析,我们提出了Equalized Focal Loss (EFL),利用了类别相关的聚焦因子来解决不同类别的正负样本不均衡性的问题。对于第j类的损失:
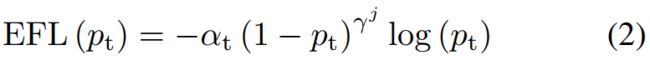
其中,和的含义和focal loss中一样。参数是第j个类别的聚焦因子,作用和focal loss中的γ一样。我们对稀有类别使用大的,常见类别使用小的。聚焦因子分解为2个部分,一个是类别无关的参数,一个是指定类别的参数:
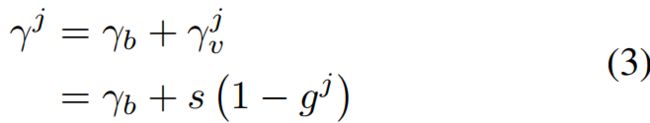
受到EQLv2的启发,我们利用梯度导向机制来选择。参数表示第j个类别的正负样本的累积梯度率。大的表示该类别比较均衡,小的表示该类别不均衡,为了满足,我们把限制到[0,1]范围内。超参数s用来缩放EFL中的的上限。
加权因子 即便有了,还是有2个问题,(1)对于二分类任务,更大的γ更加适用于严重不均衡的问题。但是对于多分类,如图3a,对于相同的,γ越大,loss越小。这导致了当我们想要更加关注一个类别的训练的时候,我们不得不牺牲掉其loss在整个训练过程中的贡献。这导致了稀少类别无法取得更好的效果。(2)当比较小,来自不同类别有着不同的聚焦因子的损失会收敛到相似的值。实际上,我们希望稀少类别的样本能够贡献更多的loss。
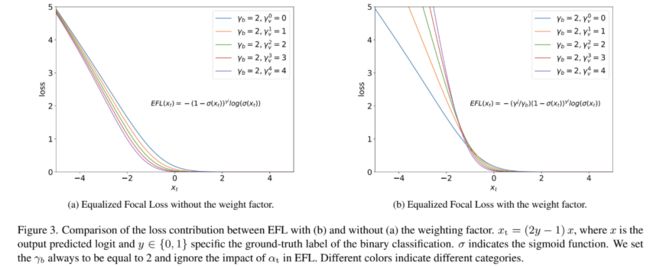
我们提出了加权因子来缓解这个问题,通过对不同的类别重新平衡loss的贡献来实现。和聚焦因子类似,我们对稀少类别使用大的加权因子,对于常见类别,加权因子接近于1。具体来说我们把第j类的加权因子设置为,最终的EFL的公式为:
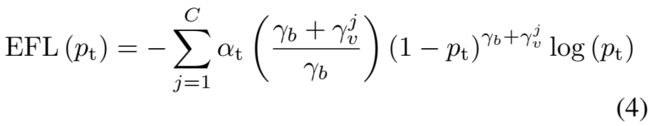
如图3b所示,有了加权因子,EFL对于稀少类别的loss的贡献显著增加了。
聚焦因子和加权因子在EFL中使得调节因子和类别相关。使得分类器可以动态的调节loss的贡献。对于分布均衡的数据,对于所有的就是原始的focal loss。因此,EFL可以适用于所有不同的分布的数据中。
4. 实验
4.1 实验设置
数据集 我们使用了LVISv1数据集,这是一个大型的长尾分布物体检测数据集,有1203个类别,1.3M个实例,这些类别被分为3组,稀有组(1 ~ 10张图),一般组(11 ~ 100张图),常见组(> 100张图)。
评估指标 物体检测一般用AP来做评估,我们还额外增加了APr ,APc,APf分别表示稀有类别,一般类别和常见类别的AP。
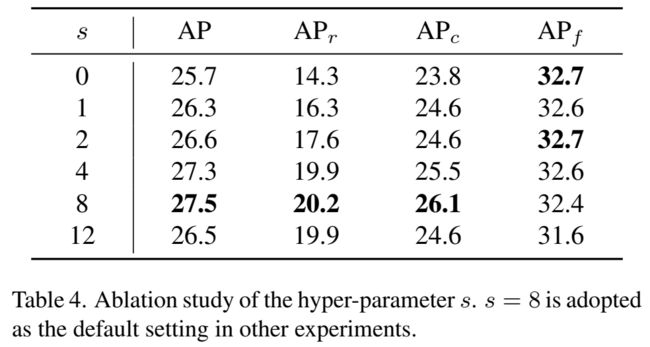
实现细节 我们用了ResNet50的ImageNet预训练模型作为backbone,用了FPN作为neck,使用SGD作为优化器,动量为0.9,权重衰减设为0.0001。batchsize为16,用了16个GPU,每个GPU一张图。初始学习率0.02。对于EFL,我们设置平衡因子,,超参数s设为8。
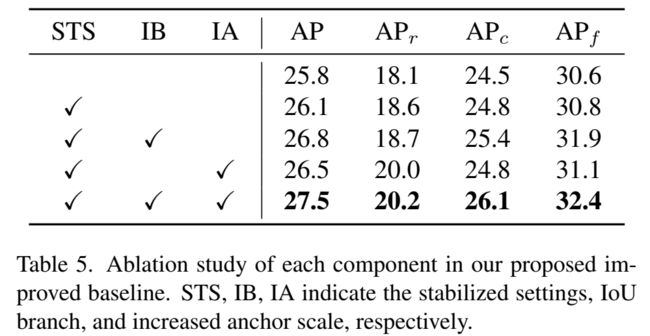
基线 我们选择了ATSS作为基线,同时,在ATSS中,我们用IoU分支来代替centerness分支,将anchor scale从{8}变为{6,8},超参数k=18,来覆盖更多的候选框。
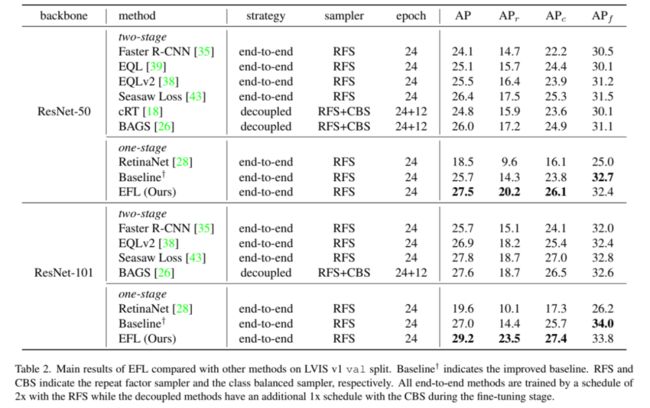
4.2 Benchmark结果
和其他方法的对比:
4.3 消融实验
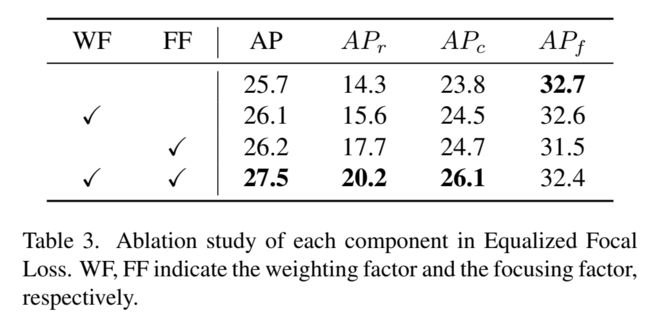
EFL中不同部分的影响:
超参数的影响:
对baseline做的改进的影响:
4.4 模型分析
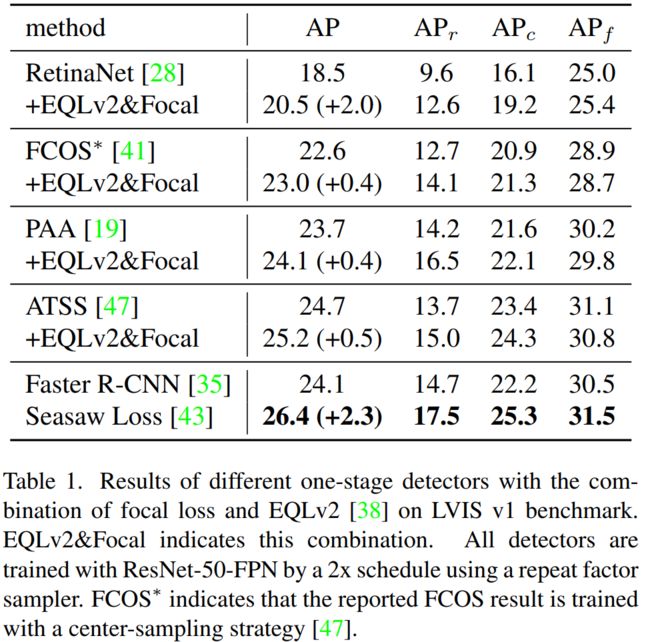
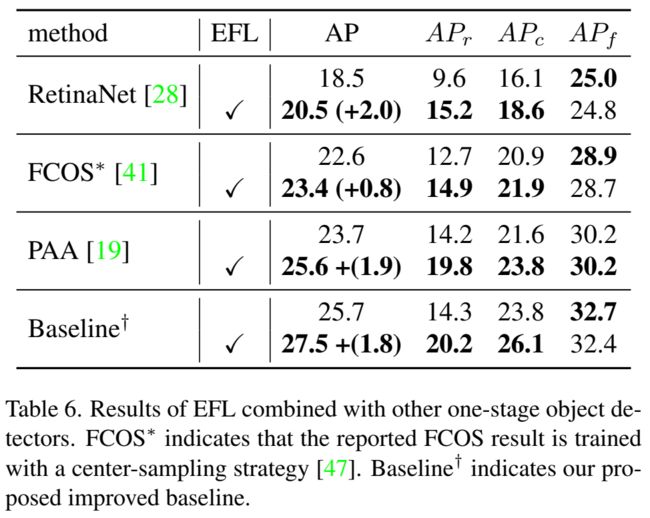
和其他的一阶段检测器一起使用,对于稀少类别有明显提升:
更清晰的决策边界 如图4,对于所有类别,margin都变大了,对于稀少样本,正负样本之间的margin变大的更加明显。

4.5 在Open Images上的检测结果
为了测试该方法在其他数据集上的有效性,我们还在OpenImage数据集上做了实验。结果如下:
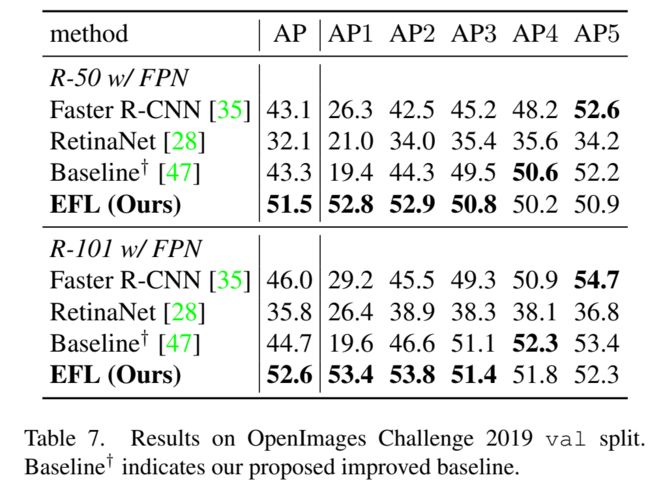
我们的方法显示出了明显的提升。特别是在AP1上,AP1表示第一组,也就是稀少类别。AP5表示第5组,表示最常出现的类别。
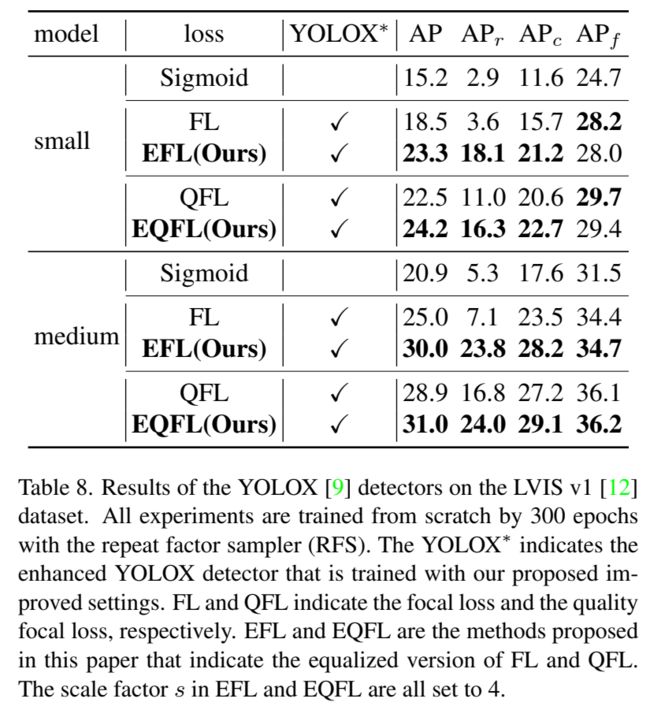
5. 和YOLOX组合使用
对稀少类别也有明显的提升:
![]()
—END—
论文链接:https://arxiv.org/pdf/2201.02593.pdf

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!