BERT预训练模型系列总结
BERT预训练模型系列总结
文章目录
- BERT预训练模型系列总结
-
- BERT模型
-
- BERT模型的输入输出
- BERT模型的预训练任务
- BERT模型的下游任务
- ROBERTa模型
- ALBERT模型
- MacBERT模型
本文主要针对大规模预训练模型BERT及基于BERT的优化模型进行总结,让大家快速学习了解Bert模型的核心,及优化模型的核心改进点。优化模型主要为RoBERTa、ALBERT、MacBERT。当然,基于预训练模型还有很多,复旦大学邱锡鹏教授发表过一篇NLP预训练模型综述,从多个角度对当前的预训练模型进行了分析,这里附上综述的论文链接:https://arxiv.org/pdf/2003.08271.pdf。
BERT模型
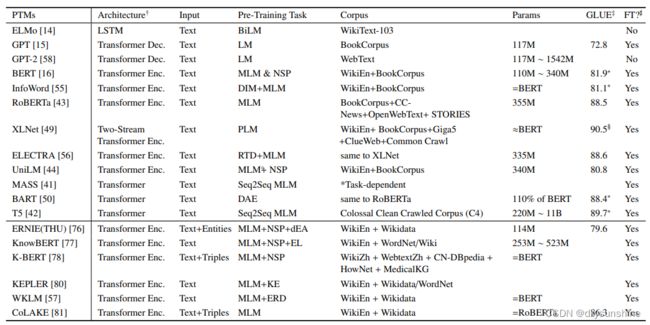
首先我们先来总结下BERT模型,BERT的全名是Bidirectional Encoder Representations from Transformers,是由Devlin等人在2018年提出的,其主要结构是Transformer的encoder层,其包括两个训练阶段,预训练与fine-tuning。BERT论文链接:https://arxiv.org/pdf/1810.04805.pdf。下面我们从模型的输入输出、预训练任务及下游任务来进行介绍。
BERT模型的输入输出
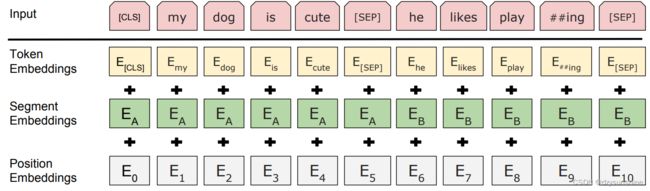
BERT模型的输入主要包含三部分:分别是token embedding词向量,segment embedding段落向量,position embedding位置向量。这里简单说下BERT输入与Transformer的区别:
Transformer的输入只包含两部分,token embedding词向量和position encoding位置向量,且position encoding用的是函数式(正余弦函数),BERT的position embedding位置向量是参数式(可学习的),且segment embedding段落向量用于区分两个句子(第一个句子为0,第二个句子为1)。
需要注意的就是,【CLS】和【SEP】,【CLS】为句首向量,【SEP】为句中和句尾向量。
BERT模型的输出为每个token对应的向量,在代码中通常包含last_hidden_state和pooler_output。
-
last_hidden_state:shape是(batch_size, sequence_length, hidden_size),hidden_size=768,它是模型最后一层输出的隐藏状态。
-
pooler_output:shape是(batch_size, hidden_size),这是序列的第一个token(classification token)的最后一层的隐藏状态,它是由线性层和Tanh激活函数进一步处理的,这个输出不是对输入的语义内容的一个很好的总结,对于整个输入序列的隐藏状态序列的平均化或池化通常更好。(【CLS】—> Linear —>tanh函数 )
通常用output[0]表示上面的last_hidden_state,output[1]表示的是pooler_output。
如果 return_dict = False,就会返回一个元组(tuple);
如果 return_dict = True,就会返回一个字典,包含下面几部分。

BERT模型的预训练任务
BERT模型的预训练任务主要包含两个, 一个是MLM(Masked Language Model),一个是NSP(Next Sentence Prediction),BERT 预训练阶段实际上是将上述两个任务结合起来,同时进行,然后将所有的 Loss 相加。
Masked Language Model 可以理解为完形填空,随机mask每一个句子中15%的词,用其上下文来做预测。而这样会导致预训练阶段与下游任务阶段之间的不一致性(下游任务中没有【MASK】),为了缓解这个问题,会按概率选择以下三种操作:
例如:my dog is hairy → my dog is [MASK]
80%的是采用[mask],my dog is hairy → my dog is [MASK]
10%的是随机取一个词来代替mask的词,my dog is hairy -> my dog is apple
10%的保持不变,my dog is hairy -> my dog is hairy
Next Sentence Prediction可以理解为预测两段文本的蕴含关系(分类任务),选择一些句子对A与B,其中50%的数据B是A的下一条句子(正样本),剩余50%的数据B是语料库中随机选择的(负样本),学习其中的相关性。前面提到序列的头部会填充一个[CLS]标识符,该符号对应的bert输出值通常用来直接表示句向量。
BERT模型的下游任务
BERT模型在经过大规模数据的预训练后,可以将预训练模型应用在各种各样的下游任务中。使用方式主要有两种:一种是特征提取,一种是模型精调。
特征提取:仅使用BERT提取输入文本特征,生成对应上下文的语义表示,来进行下游任务的训练(BERT本身不参与训练);
模型精调:利用BERT作为下游任务模型基底,生成文本对应的上下文语义表示,并参与到下游任务的训练。
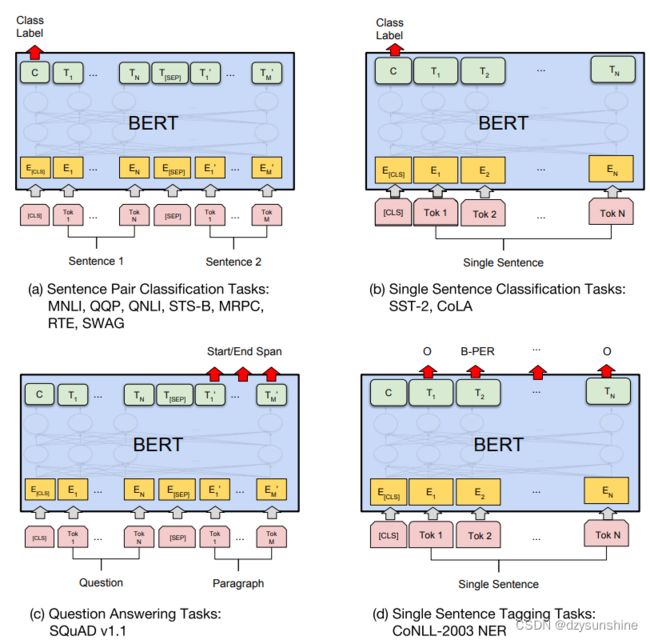
常见的下游任务有四种:单句文本分类、句子对文本分类、阅读理解和序列标注等。
ROBERTa模型
RoBERTa的全名是Robustly OptimizedBERT Pre-training Approach,对BERT模型进行了优化,在BERT的基础上引入了动态掩码技术,同时舍弃了 NSP任务,同时采用了更大规模预训练数据,并以更大的批次和BPE词表训练了更多的步数。ROBERTa模型论文链接:https://arxiv.org/pdf/1907.11692.pdf。
Bert 模型
原始静态mask:
BERT中是准备训练数据时,每个样本只会进行一次随机mask(因此每个epoch都是重复),后续的每个训练步都采用相同的mask,这是原始静态mask,即单个静态mask,这是原始 BERT 的做法。
RoBERTa 模型
修改版静态mask:
在预处理的时候将数据集拷贝 10 次,每次拷贝采用不同的 mask(总共40 epochs,所以每一个mask对应的数据被训练4个epoch)。这等价于原始的数据集采用10种静态 mask 来训练 40个 epoch。
动态mask:
并没有在预处理的时候执行 mask,而是在每次向模型提供输入时动态生成 mask,所以是时刻变化的。
RoBERTa 模型在 Bert 模型基础上的调整:
- 训练时间更长,Batch_size 更大,(Bert 256,RoBERTa 8K)
- 训练数据更多(Bert 16G,RoBERTa 160G)
- 移除了 NPL(next predict loss)
- 动态调整 Masking 机制
- Token Encoding:使用基于 bytes-level 的 BPE
简单总结如下:
| 参数\模型 | Bert | RoBerta |
|---|---|---|
| Batch_size | 256 | 2K、8K |
| 训练数据 | 13G(Bert Large) | 16G、160G |
| 训练步数 | 1M | 125K、31K |
| 是否有NSP | 是 | 否 |
| Mask方式 | static mask(静态mask) | dynamic(动态mask) |
| text Encoding | 基于 char-level 的 BPE | 基于 bytes-level 的BPE |
| 词表大小 | 30K | 50K |
ALBERT模型
ALBERT的全名 A Lite BERT,一个轻量级的BERT模型。ALBERT模型主要是为了解决BERT模型参数量大,占用计算资源大的问题。ALBERT模型降低了内存消耗并提高了BERT的训练速度。主要有两项:词向量参数因式分解和跨层参数共享,同时还引入了SOP的预训练任务,取代了BERT中原有的NSP任务。ALBERT模型论文地址:https://arxiv.org/pdf/1909.11942.pdf。
具体描述如下:
- 对Embedding因式分解:WordePiece embedding的大小 E(向量维度) 学习的是单词与上下文无关的表示,而隐藏层 H 学习的是与上下文相关的表示,显然后者更复杂,需要更多的参数,也就是说要增加隐藏层的维度H,因此通过将embedding matrix分解为两个大小分别为 V * E 和 E * H 的矩阵,来减小模型参数量,降低至原来的1/8。(减小了模型参数量,解决数据稀疏的问题,但在一定程度上降低了模型表现)
- 跨层参数共享,也就是所有参数共享。(减少参数量,使模型参数更加稳定)。
- Next-sentence prediction (NSP) 改为 Sentence Order Prediction(SOP),也就是句子顺序预测。BERT产生负例的方式是从两篇文档中各选一个句子,两篇文档的话题可能是不同的,这样模型就会更多的通过话题分析两个句子的关系,而不是句子间的连贯性,SOP则是通过选择将两个连续的句子顺序交换作为负例,这样就使得两个句子有相同的话题,模型学习到的就更多是句子间的连贯性,相比NSP任务难度更大。
- ALBERT的训练速度明显比BERT快,但效果是不如BERT的,E设为128效果最好。(需要注意的是只是训练速度快,但推理速度并没有加快)
MacBERT模型
MacBERT模型的全名 MLM as correction(校正),是一种基于文本纠错的掩码语言模型。MacBERT模型是由哈工大讯飞联合实验室提出的,BERT模型存在预训练—微调不一致的问题,具体来说就是在预训练阶段使用了【MASK】进行了掩码,但在微调阶段并没有【MASK】。MacBERT模型通过改变掩码方式解决了该问题。MacBERT模型论文链接:https://arxiv.org/pdf/2004.13922.pdf
MacBERT模型主要进行了以下修改:
-
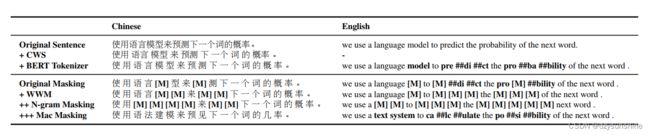
使用整词掩码及N-gram掩码两种方式选择待掩码的标记,其中 unigram 至 4-gram的概率分别为为40%,30%,20%,10%。
-
为了解决【MASK】在预训练和微调不一致的问题,使用类似的单词进行masking。 通过使用基于word2vec相似度计算的同义词工具包获得相似的单词。 如果选择一个N-gram进行masked,分别找到相似的单词。 在极少数情况下,当没有相似的单词时,会降级以使用随机单词替换。
-
对15%比例的输入单词进行masking,其中80%替换为相似的单词,10%将替换为随机单词,其余10%则保留原始单词。
-
采用ALBERT引入的句子顺序预测(SOP)任务,替换BERT中的NSP任务,并通过切换两个连续句子的原始顺序来创建负样本。
不同掩码方式的对比示例如下: