DNN、CNN、RNN、LSTM的区别,最全最详细解答
**
DNN、CNN、RNN、LSTM的区别,最全最详细解答
**
神经网络的变种目前有,
如误差反向传播(Back Propagation,BP)神经网路、
概率神经网络、
RNN-循环神经网络
DNN-深度神经网络
CNN-卷积神经网络(-适用于图像识别)、
LSTM-时间递归神经网络(-适用于语音识别)等。
但最简单且原汁原味的神经网络则是
多层感知器(Muti-Layer Perception ,MLP)。
MLP神经网络的结构和原理
最典型的MLP包括包括三层:输入层、隐层和输出层,MLP神经网络不同层之间是全连接的(全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)。

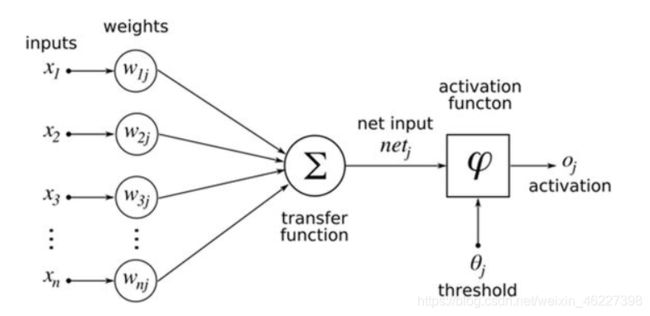
由此可知,神经网络主要有三个基本要素:权重、偏置和激活函数
权重:神经元之间的连接强度由权重表示,权重的大小表示可能性的大小
偏置:偏置的设置是为了正确分类样本,是模型中一个重要的参数,即保证通过输入算出的输出值不能随便激活。
激活函数:起非线性映射的作用,其可将神经元的输出幅度限制在一定范围内,一般限制在(-1~1)或(0~1)之间。最常用的激活函数是Sigmoid函数,其可将(-∞,+∞)的数映射到(0~1)的范围内。
MLP的最经典例子就是数字识别,即我们随便给出一张上面写有数字的图片并作为输入,由它最终给出图片上的数字到底是几。
对于一张写有数字的图片,我们可将其分解为由28*28=784个像素点构成,每个像素点的值在(0~1)之间,其表示灰度值,值越大该像素点则越亮,越低则越暗,以此表达图片上的数字并将这786个像素点作为神经网络的输入。
而输出则由十个神经元构成,分别表示(0~9)这十个数字,这十个神经元的值也是在(0~1)之间,也表示灰度值,但神经元值越大表示从输入经判断后是该数字的可能性越大。
*神经网络:多层感知器-MLP | ChinaIT.com http://www.chinait.com/ai/30661.html
DNN(深度神经网络)
神经网络是基于感知机的扩展,而DNN可以理解为有很多隐藏层的神经网络。多层神经网络和深度神经网络DNN其实也是指的一个东西,DNN有时也叫做多层感知机(Multi-Layer perceptron,MLP)。
DNN存在的局限:
参数数量膨胀。由于DNN采用的是全连接的形式,结构中的连接带来了数量级的权值参数,这不仅容易导致过拟合,也容易造成陷入局部最优。
局部最优。随着神经网络的加深,优化函数更容易陷入局部最优,且偏离真正的全局最优,对于有限的训练数据,性能甚至不如浅层网络。
梯度消失。使用sigmoid激活函数(传递函数),在BP反向传播梯度时,梯度会衰减,随着神经网络层数的增加,衰减累积下,到底层时梯度基本为0。
无法对时间序列上的变化进行建模。对于样本的时间顺序对于自然语言处理、语音识别、手写体识别等应用非常重要。
DNN的基本介绍可参考:
深度神经网络(DNN)模型与前向传播算法 - 刘建平Pinard - 博客园 https://www.cnblogs.com/pinard/p/6418668.html
深层学习为何要“Deep” - 知乎 https://zhuanlan.zhihu.com/p/22888385
CNN(卷积神经网络)
主要针对DNN存在的参数数量膨胀问题,对于CNN,并不是所有的上下层神经元都能直接相连,而是通过“卷积核”作为中介(部分连接)。同一个卷积核在多有图像内是共享的,图像通过卷积操作仍能保留原先的位置关系。
CNN之所以适合图像识别,正式因为CNN模型限制参数个数并挖掘局部结构的这个特点。
CNN相关知识可参考:
YJango的卷积神经网络——介绍 - 知乎 https://zhuanlan.zhihu.com/p/27642620
RNN(循环神经网络)
针对CNN中无法对时间序列上的变化进行建模的局限,为了适应对时序数据的处理,出现了RNN。
在普通的全连接网络或者CNN中,每层神经元的信号只能向上一层传播,样本的处理在各个时刻独立(这种就是前馈神经网络)。而在RNN中,神经元的输出可以在下一个时间戳直接作用到自身。
(t+1)时刻网络的最终结果O(t+1)是该时刻输入和所有历史共同作用的结果,这就达到了对时间序列建模的目的。
存在的问题:RNN可以看成一个在时间上传递的神经网络,它的深度是时间的长度,而梯度消失的现象出现时间轴上。
RNN相关知识可参考:
循环神经网络(RNN)模型与前向反向传播算法 - 刘建平Pinard - 博客园 https://www.cnblogs.com/pinard/p/6509630.html
YJango的循环神经网络——介绍 - 知乎 https://zhuanlan.zhihu.com/p/24720659
在NLP上,CNN、RNN、MLP三者相比各有何优劣
MLP:因为句子长度不固定,所以一般是用Bag-of-Word-Vectors 简单将词向量相加,然后使用MLP,这个方法比较简单,训练速度比较快,得到的结果也不是很差。只是没有利用到上下文信息。
RNN:将句子或文本作为序列输入比较自然,可以利用到历史信息,将词的顺序也考虑进去。此外,RNN的使用有很多变化,最简单的是使用最基础的RNN将最后一个词的隐含层输出进行softmax,但这样越往后的词会显得越重要(因为从前向后,最后一个输入的信息会更多地留下来),或者将每个隐含层的输出的和和均值进行softmax。也可以将基础的RNN变化为使用LSTM(很容易过拟合)或GRU单元,或使用bi-RNN获取更多的上下文信息。最后结果上并没有比MLP的结果好很多,但训练速度上慢了很多。(PS: 我这里的RNN指Recurrent Neural Network)
CNN:这个方法看起来对处理这种序列输入不是很自然,所以一般是对句子的所有词的词向量使用不同大小的窗口(能获取一定前后文信息,有点像隐式的n-gram)进行一维的卷积,然后用最大池化获得最重要的影响因子(我个人觉得这个比较讲得通,因为文本中不是所有词对分类结果都有贡献)和定长输出。CNN的方法也训练起来也比较简单,现阶段最后实验的效果也是最好。但有一些窗口大小上选取的经验问题,对文本长程依赖上的问题也并不是很好解决,因为窗口大小一般不会选很大。
LSTM(长短时记忆单元)
为了解决RNN中时间上的梯度消失,机器学习领域发展出了长短时记忆单元LSTM,通过门的开关实现时间上记忆功能,并防止梯度消失。
LSTM相关知识可参考:
[译] 理解 LSTM(Long Short-Term Memory, LSTM) 网络 - wangduo - 博客园 https://www.cnblogs.com/wangduo/p/6773601.html?utm_source=itdadao&utm_medium=referral
探索LSTM:基本概念到内部结构 - 知乎 https://zhuanlan.zhihu.com/p/27345523
扩展
深度神经网络中的梯度不稳定性,前面层中的梯度或会消失,或会爆炸。前面层上的梯度是来自于后面层上梯度的乘乘积。当存在过多的层次时,就出现了内在本质上的不稳定场景,如梯度消失和梯度爆炸。
梯度爆炸(exploding gradient):梯度爆炸就是由于初始化权值过大,前面层会比后面层变化的更快,就会导致权值越来越大,梯度爆炸的现象就发生了。
在深层网络或循环神经网络中,误差梯度可在更新中累积,变成非常大的梯度,然后导致网络权重的大幅更新,并因此使网络变得不稳定。在极端情况下,权重的值变得非常大,以至于溢出,导致 NaN 值。
网络层之间的梯度(值大于 1.0)重复相乘导致的指数级增长会产生梯度爆炸。
解决梯度爆炸的方法参考:
详解梯度爆炸和梯度消失 - hank的DL之路 - 博客园 https://www.cnblogs.com/DLlearning/p/8177273.html
梯度消失(vanishing gradient):前面的层比后面的层梯度变化更小,故变化更慢,从而引起了梯度消失问题。
因为通常神经网络所用的激活函数是sigmoid函数,这个函数有个特点,就是能将负无穷到正无穷的数映射到0和1之间,并且对这个函数求导的结果是f′(x)=f(x)(1−f(x))。因此两个0到1之间的数相乘,得到的结果就会变得很小了。神经网络的反向传播是逐层对函数偏导相乘,因此当神经网络层数非常深的时候,最后一层产生的偏差就因为乘了很多的小于1的数而越来越小,最终就会变为0,从而导致层数比较浅的权重没有更新,这就是梯度消失。
因为sigmoid导数最大为1/4,故只有当abs(w)>4时梯度爆炸才可能出现。深度学习中最普遍发生的是梯度消失问题。
解决方法:使用ReLU,maxout等替代sigmoid。
ReLU与sigmoid的区别:(1)sigmoid函数值在[0,1],ReLU函数值在[0,+无穷],所以sigmoid函数可以描述概率,ReLU适合用来描述实数;(2)sigmoid函数的梯度随着x的增大或减小和消失,而ReLU不会。