Crawlab运行selenium爬虫
上篇文章学习了Crawlab运行scrapy爬虫和单文件爬虫,这次学习Crawlab运行selenium爬虫,我的例子是单文件的。
环境准备
Crawlab虽然自带了一些爬虫用的第三方库,但是不全,总有一些库是你的代码需要但它没自带的,如selenium就没自带。
查看已安装的库
有两种方法可以看你的Crawlab是否安装了selenium(截图时我已安装),如果你没装,则下面的图中你看不到selenium。
方法一
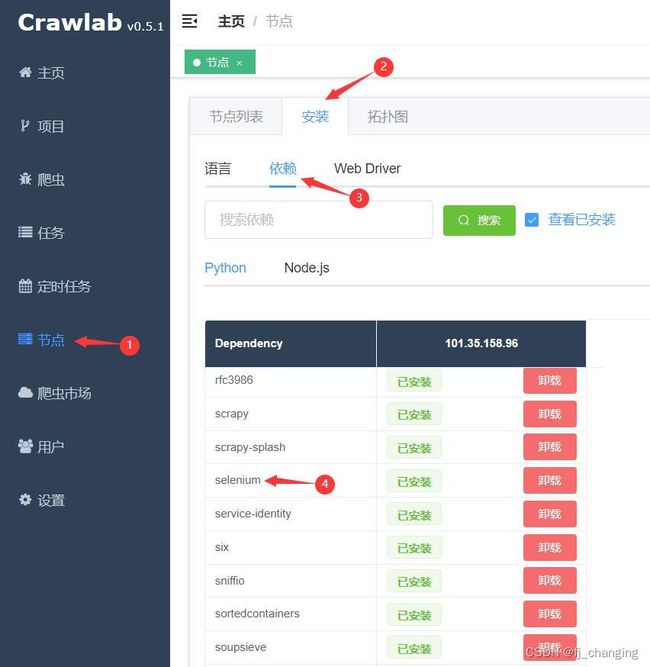 图1
图1
方法二
 图2
图2
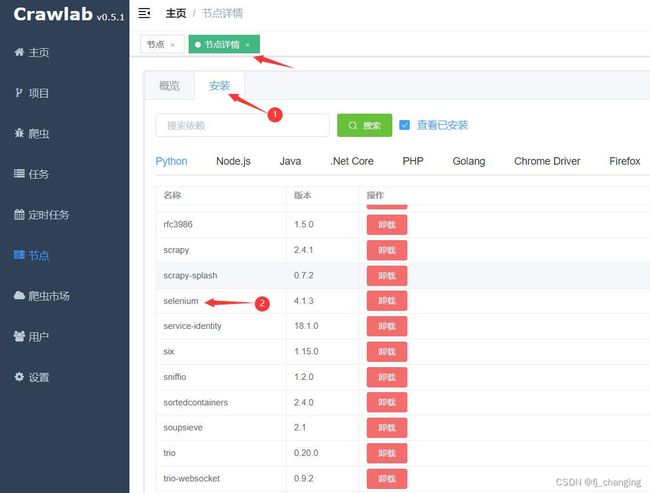 图3
图3
安装需要的库
文档中有两处提到安装依赖,文档-爬虫-自动安装依赖,文档-节点-安装节点依赖末尾。
自动安装依赖
对于 Docker 安装 Crawlab 的开发者来说,每次更新容器(例如 down & up)时候会比较繁琐,因为需要重新安装爬虫的依赖,这对于长期使用 Crawlab 的用户来说,是一个痛点。
为了解决开发者的痛点,Crawlab 开发组开发了自动安装依赖的功能。
为了使用自动安装依赖的功能,用户需要将在爬虫项目中,将
requirements.txt(Python)或package.json(Node.js)放在爬虫根目录,并上传到 Crawlab。Crawlab 会自动扫描代码目录,如果存在requirements.txt或package.json,就会自动执行对应的安装程序,将指定的依赖安装到 Crawlab 节点上。对于经常需要重启 Crawlab 的用户来说,可以将需要的依赖存在依赖配置文件(
requirements.txt或package.json)里,每次重启 Crawlab 后,它会自动将对应的依赖安装上。
不足的地方
我知道开发者们会吐槽:为何不做上传
requirements.txt或package.json批量安装的功能啊;为何不支持环境持久化,每次都要重新安装啊;为何不支持 Java 啊... 我知道这些都是很实用的功能,但 Crawlab 的开发向来都是遵从敏捷开发和精益打磨的原则,不会过度开发一个功能,优先保证可行性、可用性、健壮性和稳定性。因此,在验证了大家的使用情况后,我们会逐步完善这个功能,让其变得更加实用。
这两处看上去可能有点矛盾,实际Crawlab0.5.1支持requirements.txt,所以若Crawlab没自带你用的库,则把库名写入requirements.txt,再将它和代码文件一起压缩到同一个zip并上传就行。之后再用这个库时就不用再写requirements.txt了。
现在selenium有了,还需要chrome和chrome驱动。
我的Crawlab是用Docker部署的,将带有requirements.txt的zip文件(zip文件中不能有chrome驱动,否则上传失败)上传后,直接就可以运行本次上传的selenium爬虫了,Crawlab会自动准备chrome和chrome驱动。若你手动在服务器通过终端命令行运行selenium爬虫,则需手动安装chrome并手动准备chrome驱动文件。
查看chrome驱动是否已安装同样有两种方法,分别为图4和图5。
 图4
图4
 图5 - 步骤类似图3
图5 - 步骤类似图3
你可能会疑惑,这些图片中的位置不能手动安装库吗?就是直接在网页端安装selenium、chrome驱动,文档里虽然说了可以在网页端安装库,但我安装失败了。
运行selenium爬虫
和上篇文章中单文件爬虫的运行方法一样
 图6 - 运行爬虫
图6 - 运行爬虫
示例代码,用selenium打开B站,点击登录,保存登录二维码图片到本地,并保存登录二维码图片的链接(不用吐槽为什么保存这个,注释中有)。
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
# from selenium.webdriver.support.ui import WebDriverWait 上一行也可以这样写,ui里导入了wait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from crawlab import save_item
url = 'https://www.bilibili.com/'
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--disable-gpu')
options.add_argument('--start-maximized')
options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36')
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_argument('--no-sandbox') # 禁用沙盒,Linux使用
options.add_argument('--disable-dev-shm-usage') # Linux的Docker中使用,但Linux的Docker的Crawlab中运行时不写也行
browser = webdriver.Chrome(options=options) # Crawlab中运行时不用手动指定executable_path参数,即chrome驱动文件路径。首次上传到Crawlab的含selenium的项目,需将selenium写入requirements.txt并和代码文件压缩到同一个zip,一起上传,之后Crawlab会自动安装selenium和chroem驱动,Crawlab0.5.1可能无法在网页端手动安装selenium和chroem驱动(我安装失败了)。
browser.get(url)
locator = (By.CLASS_NAME, 'header-login-entry') # 定位到登录按钮
try:
login_button = WebDriverWait(browser, 10, 0.5).until(EC.presence_of_element_located(locator)) # 显式等待。最多等待10秒,每隔0.5秒查找一次指定元素(默认0.5秒,可不写),若找到指定元素则不再等待并返回找到的元素,若直到超时都未找到则报错TimeoutException。注意EC.presence_of_element_located()的参数是一个元组。
except TimeoutException:
browser.quit()
raise TimeoutException('直到超时都没找到登录按钮')
else:
login_button.click()
try:
login_QRcode_img = WebDriverWait(browser, 10).until(EC.presence_of_element_located((By.XPATH, '//div[@class="bili-mini"]//img[@alt="Scan me!"]')))
except TimeoutException:
browser.quit()
raise TimeoutException('直到超时都没找到登录二维码')
else:
login_QRcode_img.screenshot('./login_QRcode.png') # 对当前元素截图并保存。假设它是要识别的验证码,所以保存。
'''
我用Docker部署的Crawlab,Docker是用宝塔安装的,截图文件不知道为什么会保存两份
/www/server/docker/overlay2/d95a9341ee143253800f88bfd1aad0bca2d598f52ecae604138f804291071e27/diff/app/spiders/selenium_test/login_QRcode.png
/www/server/docker/overlay2/d95a9341ee143253800f88bfd1aad0bca2d598f52ecae604138f804291071e27/merged/app/spiders/selenium_test/login_QRcode.png
merged和diff文件夹的介绍
https://www.cnblogs.com/fqnb001/p/12384402.html
https://blog.csdn.net/wshk918/article/details/84449879
'''
login_QRcode_img_url = login_QRcode_img.get_property('src') # 获取html元素的属性的值
result = {'login_QRcode_img_url': login_QRcode_img_url}
save_item(result) # 只是为了测试在Crawlab中使用selenium,所以随便向MongoDB存入一个内容。若实际为了识别验证码,则不能保存验证码图片链接,因再次访问链接时返回的验证码和前一次访问时不同,需直接保存验证码图片再识别。
browser.quit()