SRGAN论文与ESRGAN论文总结
博客结构
- SRGAN
-
- Contribution:
- Network Architecture:
-
- Generator Network
- Discriminator Network
- Perceptual loss function:
- Experiments:
- Mean opinion score (MOS) testing:
- ESRGAN
-
- Contribution:
- Network Architecture:
-
- ESRGAN相对于SRGAN对生成器做出了一下两点修改:
- Relativistic Discriminator:
- Perceptual Loss:
- Network Interpolation:
- Experiments:
-
- Dataset:
- Qualitative Results:
- 消融实验
SRGAN论文地址:http://arxiv.org/abs/1609.04802
ESRGAN论文地址:https://arxiv.org/abs/1809.00219
SRGAN
Contribution:
- 提出了深度残差网络SRResNet
- 文章提出基于MSE(最小均方误差)、PSNR(信噪比)和SSIM(结构相似度)评价标准的局限性。
MSE捕捉感知相关差异(高纹理细节)的能力十分有限。因为它是基于像素级的差异定义的。
下图表示虽然MSE可以得到高PSNR和高SSIM的图像,但是在视觉感知上并不是很理想。
- 提出一种新的感知损失,将基于MSE的内容损失替换为基于VGG网络特征图计算的损失。
- 提出SRGAN网络架构,证明了SRGAN是具有高放大因子的SR图像技术。
Network Architecture:
Generator Network
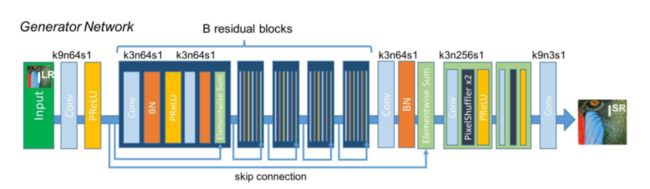
生成网络的核心是B残差块。文章使用两个3*3卷积核,输出通道数为64,卷积层之后使用批归一化BN层和ParametricReLU激活层。
最后使用了两个经过训练的子像素卷积层(trained sub-pixel convolution layer)提高输入图像的分辨率。
Discriminator Network

鉴别网络使用LeakyReLU激活函数(α=0.2),用来避免网络中的最大池化。鉴别网络包含八个卷积层,其中有3个滤波器核,与VGG一样channel个数从64增加到512.
Strided convolution用来当通道数增加一倍时,降低特征图分辨率。得到channel=512的特征图之后是两个Dense layer和一个Sigmoid层。
Perceptual loss function:
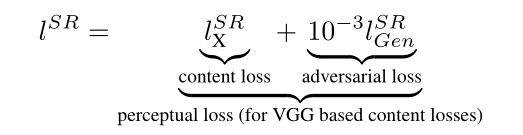
感知损失函数定义为内容损失和对抗损失的加权和。
像素级MSE loss函数定义为:
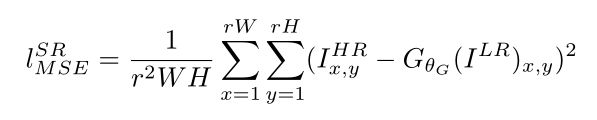
其中r表示缩放因子。
文章中将content loss由先前较为常用的像素级MSE loss更改为基于ReLU激活层的VGG loss,VGG loss定义为重建图像的特征表示与相应图像之间的欧式距离。计算公式如下:
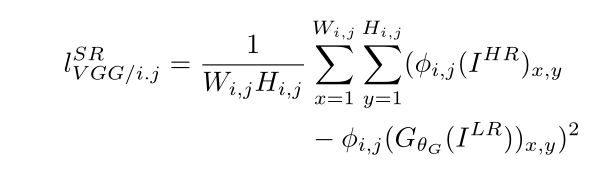
其中 ϕ i , j \phi_{i,j} ϕi,j表示通过第j次卷积后(激活后)第i个最大池化前获得的特征映射。 W i , j , H i , j W_{i,j},H_{i,j} Wi,j,Hi,j表示VGG网络中各自特征图的维度。
对抗损失的添加鼓励网络通过愚弄鉴别网络来支持存在于多种自然图像上的解决方案。生成损失定义为基于鉴别器在所有训练样本上的概率:

Experiments:
使用Set5、Set14、BSD100数据集,testing set of BSD300。

其中SRResNet(SRGAN)-X表示使用不同content loss的网络。VGG22与VGG54分别表示对抗损失使用、。MOS会在下节解释。
文章将SRGAN-VGG54称为SRGAN,将SRResNet-MSE称为SRResNet。
文章将SRResNet与SRGAN使用不同的Content loss进行对比。发现即使与Adversarial loss相结合,使用MSE作为Content loss,也具有最高的PSNR和SSIM。但是从视觉上看,MSE提供的图像相当平滑,缺少高频纹理细节,见下图。文章解释是由于MSE的Content loss和Adversarial loss相互竞争导致的。由表格所知,SRGAN-VGG54具有最高的MOS得分,其性能优于其他方案。
与相比,使用更深的VGG特征映射可以获得更好的纹理细节。
表2是比较了SRResNet和SRGAN与NN、双三次插值和四种最新方法的性能。再次验证了SRResNet-MSE可以提供最高的PSNR和SSIM得分,但是重建图像的视觉感受并不理想。SRGAN-VGG54拥有最高的MOS得分。证明了SRGAN优于所有的参考方法,为photo-
realistic image SR提供了新的技术水平。表2进一步表明,PSNR和SSIM等标准定量测量无法捕获和准确评估与人类视觉系统相关的图像质量[56]。这项工作的重点是超分辨率图像的感知质量,而不是计算效率。
Mean opinion score (MOS) testing:
因为生成图片质量,没有一个合适的定量分析的标准,作者让26名评分员给超分辨率图像评分,1-5分分别对应质量差到质量好。评分员对Set5、Set14和BSD100上的每个图像的12个版本进行评分:最近邻(NN)、双三次、SRCNN[9]、SelfExSR[31]、DRCN[34]、ESPCN[48]、SRResNet MSE、SRResNetwork-VGG22∗ (∗未在BSD100中评级),SRGAN-SE∗, SRGAN-VGG22型∗, SRGANVGG54和原始HR图像。得到下图:
评级机构非常一致地将NN插值测试图像评级为1,将原始HR图像评级为5。并得出提出的SRGAN拥有最好的重建质量。
ESRGAN
Contribution:
- 提出ESRGAN模型,与SRGAN相比,可以获得更好的感知质量。
- 提出一个新的感知体系结构,包含若干RRDB块,去掉了SRGAN中所有的BN层。
- 使用residual scaling和smaller initialization技术便于对深度模型进行训练。
- 使用relativistic GAN作为discriminator。相比于传统discriminator估计输入图像x真实和自然的概率,它学习判断一幅图像是否比另一幅图像更逼真,以此来指导generator恢复更详细的纹理。
- 使用激活前特征,增强感知损失,这些特征提供了更强的监督,从而恢复更精确的亮度和纹理。
- 使用网络插值,能够在不引入伪影的情况下,为任何可行的α生成有意义的结果,可以在不重新训练模型的情况下持续平衡感知质量和忠实度。
Network Architecture:

其中Basic Block可以被更换为Residual block、dense block和RRDB。
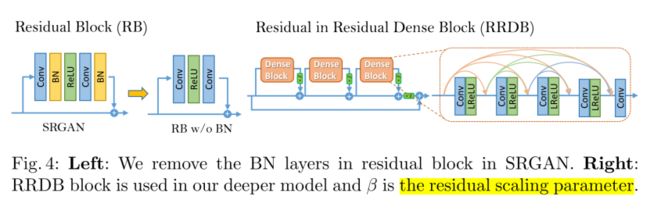
ESRGAN相对于SRGAN对生成器做出了一下两点修改:
- 去除所有BN层。文中提到,BN层在训练期间使用batch中的均值和方差对特征进行规范化,在测试期间使用整个训练集的均值和方差。在训练数据和测试数据差异很大时,BN层会引入伪影,限制模型的泛化能力。而去除BN层可以实现稳定的训练和一致的性能。提高模型泛化能力,减少模型计算复杂度和内存的使用。
- 使用所提出的Residual in Residual Dense Block(RRDB)替换原始的基本块。RRDN结合了多级残差网络和密集连接。RRDN比SRGAN的基本块具有更深的结构,更复杂的残差连接方式。
同时作者提到,他们还使用了residual scaling技术,在残差值添加到主路径之前乘以一个[0,1]的常数用来缩小残差值,防止不稳定。
Smaller initialization,根据经验发现,当初始参数方差变小时,残差结构会变得更加容易训练。
Relativistic Discriminator:
Standard discriminator D估计一个输入图像x真实和自然的概率。Relativistic discriminator尝试预测真实图像xr比假图像xr更真实的概率。

SRGAN中Standard discriminator可以表示为 D ( X ) = σ ( C ( X ) ) D(X)=\sigma(C(X)) D(X)=σ(C(X)),其中 σ \sigma σ表示sigmoid函数, C ( X ) C(X) C(X)是非变换鉴别器输出。
ESRGAN中Relativistic Discriminator(RaD)表示为:
D R a ( x r , x f ) = σ ( C ( x r ) − E x f [ C ( x f ) ] ) D_{Ra}(x_r,x_f)=\sigma(C(x_r)-\mathbb{E}_{x_f}[C(x_f)]) DRa(xr,xf)=σ(C(xr)−Exf[C(xf)])
其中 E [ ⋅ ] \mathbb{E[·]} E[⋅]表示对mini-batch中所有fake数据进行平均操作。
Discriminator loss定义如下:
L D R a = − E x r [ l o g ( D R a ( x r , x f ) ) ] ] − E x f [ l o g ( 1 − D R a ( x f , x r ) ) ] L_D^{Ra}=-\mathbb{E}_{x_r}[log(D_{Ra}(x_r,x_f))]]-\mathbb{E}_{x_f}[log(1-D_{Ra}(x_f,x_r))] LDRa=−Exr[log(DRa(xr,xf))]]−Exf[log(1−DRa(xf,xr))]
生成器的对抗损失为对称形式:
L E R a = − E x r [ l o g ( 1 − D R a ( x r , x f ) ) ] ] − E x f [ l o g ( D R a ( x f , x r ) ) ] L_E^{Ra}=-\mathbb{E}_{x_r}[log(1-D_{Ra}(x_r,x_f))]]-\mathbb{E}_{x_f}[log(D_{Ra}(x_f,x_r))] LERa=−Exr[log(1−DRa(xr,xf))]]−Exf[log(DRa(xf,xr))]
其中, x f = G ( x i ) x_f=G(x_i) xf=G(xi), x i x_i xi表示输入的LR(low resolution)图像。 x r x_r xr表示real photo。Generator的Adversarial loss中包含 x r x_r xr和 x i x_i xi,因此生成器可以从对抗训练中的生成数据和real数据的梯度中收益,而在SRGAN中只有生成的部分有效。
Perceptual Loss:
作者认为,应当将感知损失在激活层之前计算,原始设计有以下两个缺点:
- 激活特征稀少
下图是激活前后特征的变化,可以看出激活前特征包含更多信息。而稀疏激活提供较弱的监督,导致性能低下。
- 激活后使用特征会导致重建亮度与地面真实图像不一致
总的生成器loss定义如下:
L G = L p e r c e p + λ L G R a + η L 1 L_G=L_{percep}+\lambda L_G^{Ra}+\eta L_1 LG=Lpercep+λLGRa+ηL1
其中, L 1 = E x i ∣ ∣ G ( x i ) − y ∣ ∣ 1 L_1=\mathbb{E}_{x_i}||G(x_i)-y||_1 L1=Exi∣∣G(xi)−y∣∣1评估恢复图像和真实图像y之间1-范数距离的Content loss, λ \lambda λ, η \eta η是平衡不同损失项的系数。
Network Interpolation:
作者为了在GAN的基础上去除不愉快的噪声,同时保持良好的感知质量,提出了网络插值方法。
- 首先训练一个面向PSNR的网络 G P S N R G_{PSNR} GPSNR,通过微调获得一个基于GAN的网络 G G A N G_{GAN} GGAN。
- 然后对两个网络所有相应参数进行插值,得到一个插值模型 G I N T E R P G_{INTERP} GINTERP
其参数为:
θ G I N T E R P = ( 1 − α ) θ G P S N R + α θ G G A N \theta_G^{INTERP}=(1-\alpha)\theta_G^{PSNR}+\alpha\theta_G^{GAN} θGINTERP=(1−α)θGPSNR+αθGGAN
其中, θ G I N T E R P \theta_G^{INTERP} θGINTERP、 θ G P S N R \theta_G^{PSNR} θGPSNR和 θ G G A N \theta_G^{GAN} θGGAN分别是 G I N T E R P G_{INTERP} GINTERP、 G P S N R G_{PSNR} GPSNR和 G G A N G_{GAN} GGAN的参数, α ∈ [ 0 , 1 ] \alpha\in[0,1] α∈[0,1]是插值参数。引入网络插值有两个优点:
- 不引入伪影的情况下,为任何可行的α生成有意义的结果。
- 在不重新训练模型的情况下持续平衡感知质量和忠实度。
Experiments:
Follow SRGAN,在LR和HR图像之间以*4的比例因子执行所有实验。
训练分为两个阶段,首先使用L1 loss训练一个面向PSNR的模型,然后使用经过训练的面向PSNR的模型作为生成器的初始化。
这样做的优点是:
- 它可以避免生成器不希望的局部最优;
- 经过预训练后,鉴别器在一开始就接收到相对较好的超分辨率图像,这有助于它更加关注纹理识别。
Dataset:
使用DIV2K数据集(包含800张2k分辨率图像),Flickr2K数据集(包括Flickr网站上收集的2650张2k图像),OutdoorSceneTraining(OST)数据集。在RGB通道中训练模型,并使用随机水平翻转和90度旋转来增加训练数据集。
Qualitative Results:
与SRCNN、EDSR、RCAN、SRGAN和EnhanceNet进行了比较,结果如下图。
消融实验
如下图,每一列代表一个模型,配置如上边的表格所示。
由第2、3列,BN层的去除不会降低性能,但是可以节省计算资源和内存使用。文中提到在某些情况下,BN层的移除可以观察到细微的改进,并且当网络更深更复杂时,BN层可能引入令人不快的伪影。
感知损失在激活前计算,可以获得更精确的重建图像亮度。激活前使用特征有助于产生更尖锐的边缘和更丰富的纹理。见下图:
RaGAN(Relativistic GAN)有助于学习更清晰的边缘和更详细的纹理。
使用RRDB建立更深的网络可以进一步改进恢复的纹理,同时更深的模型可以减少不愉快的噪音。
作者指出与SRGAN不同,SRGAN声称更深的模型更难以训练,而更深的ESRGAN则显示出更优越的性能,更易于训练。得益于无BN层的RRDB。
作者比较了网络插值与图像插值在平衡面向PSNR和GAN方法上的效果,见上图,通过对α间隔0.2的取值,观察网络插值和图像插值的区别:
- 纯GAN方法产生尖锐的边缘和更丰富的纹理,但有一些令人不快的伪影。
- 纯PSNR方法输出卡通风格的模糊图像。
- 图像插值无法有效地消除这些伪影。