Keras卷积神经网络识别CIFAR-10图像
基于对卷积神经网络有一定认识以及对Keras有一定了解
参考教材《TensorFlow+Keras深度学习人工智能实践应用》
基于jupyter notebook
基本流程
- (1)导入相关库
- (2)数据预处理
- (3)建立卷积模型
- (4)进行训练
- (5)评估和预测
- (6)显示混淆矩阵
- (7)补充:模型保存和加载
(1)导入相关库
from keras.datasets import cifar10 # 导入cifar10数据集
from keras.utils import np_utils # 导入做热处理的库
import numpy as np # 导入numpy库
np.random.seed(10) # 第10批种子
(2)数据预处理
(x_train_image,y_train_label),(x_test_image,y_test_label) = cifar10.load_data() # 下载数据
x_train_normalize = x_train_image.astype('float32') / 255.0 # 转为float类型后标准化
x_test_normalize = x_test_image.astype('float32') / 255.0
y_train_label_OneHot = np_utils.to_categorical(y_train_label) # 转为一位热编码形式
y_test_label_OneHot = np_utils.to_categorical(y_test_label)
(3)建立卷积模型
from keras.models import Sequential # 导入模型库
from keras.layers import Dense,Dropout,Conv2D,MaxPooling2D,Flatten # 导入卷积相关层
model = Sequential() # 初始化
# 32个过滤器 卷积核3*3 输入shape 32*32*3 激活函数relu 采取零填充法
model.add(Conv2D(filters=32,kernel_size=(3,3),input_shape=(32,32,3),activation='relu',padding='same')) # 添加卷积层
model.add(Dropout(0.25))
model.add(MaxPooling2D(pool_size=(2,2))) # 池化
# 建立第二个卷积层
# 64个过滤器 卷积核3*3 输入shape 32*32*3 激活函数relu 采取零填充法
model.add(Conv2D(filters=64,kernel_size=(3,3),activation='relu',padding='same')) # 添加卷积层
model.add(Dropout(0.25))
model.add(MaxPooling2D(pool_size=(2,2))) # 池化
# 平坦层
model.add(Flatten())
model.add(Dropout(0.25))
# 隐藏层
model.add(Dense(units=1024,activation='relu')) #1024个神经元 relu激活
model.add(Dropout(0.25))
# 输出层
model.add(Dense(10,activation='softmax'))
print(model.summary()) # 打印模型摘要
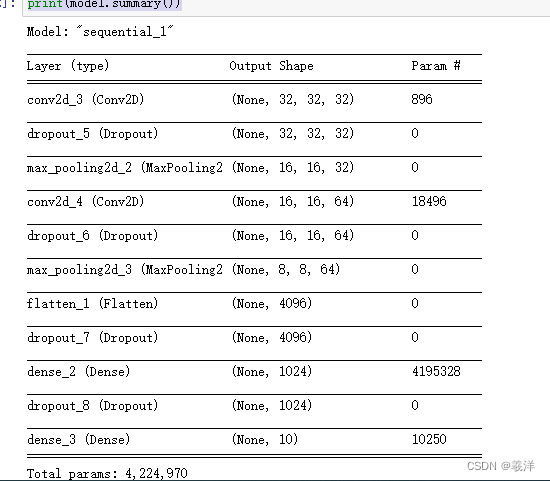
(4)进行训练
# 定义训练方式 交叉熵损失函数 adam优化器 accuracy作为评价指标
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
# 开始训练 80%训练20%验证 5个训练周期 每批128个 显示训练过程
train_history=model.fit(x_train_normalize,y_train_label_OneHot,validation_split=0.2,epochs=5,batch_size=128,verbose=2)
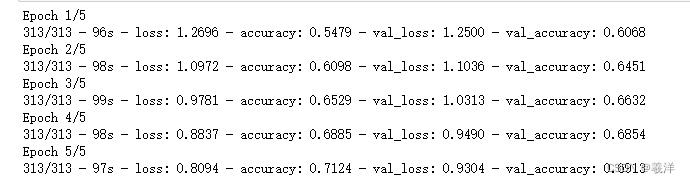
显示训练过程
# 显示训练过程的准确率和损失函数的变化
show_train_history(train_history,'accuracy','val_accuracy')
show_train_history(train_history,'loss','val_loss')
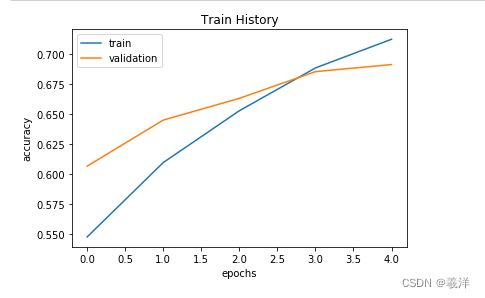
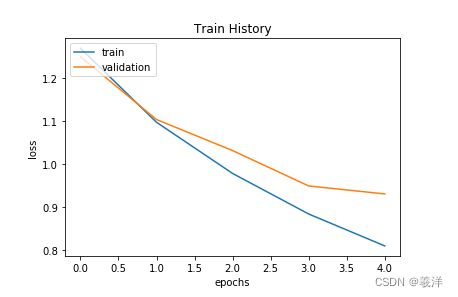
(5)评估和预测
# 评估模型准确率
scores = model.evaluate(x_test_normalize,y_test_label_OneHot)
print(scores[1])

预测
# 预测
predict = model.predict(x_test_normalize)
prediction = np.argmax(predict,axis=1) # 取最大列 取对应概率最大值
prediction[:10]
![]()
查看预测概率
# 创建对应的字典 将数字转为对应的字符串
# 创建对应的字典 将数字转为对应的字符串
label_dict={0:'airplane',1:'automobile',2:'bird',3:'cat',4:'deer',5:'dog',6:'frog',7:'horse',8:'ship',9:'truck'}
# 查看预测概率
Predicted_Probability = predict
def show_Predicted_Probability(y_test_label,prediction,x_test_image,Predicted_Probability,i):
print('label:',y_test_label[i][0],',predict:',prediction[i]) # 打印实际值与预测值
plt.figure(figsize=(2,2)) # 设置显示图片的大小
plt.imshow(np.reshape(x_test_image[i],(32,32,3)))
plt.show() # 展示图片
# 展示该图片对应各个类别的概率
for j in range(10):
print(label_dict[j] + ' Probability:%1.9f'%(Predicted_Probability[i][j]))
show_Predicted_Probability(y_test_label,prediction,x_test_image,Predicted_Probability,0) # 查看第0项的预测概率

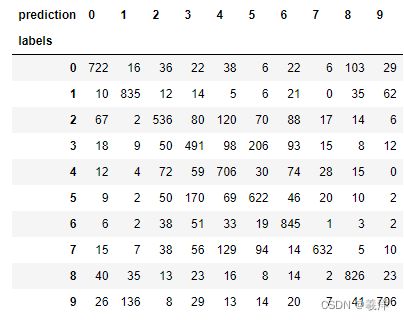
(6)显示混淆矩阵
import pandas as pd
# y_test_label转为1唯
pd.crosstab(y_test_label.reshape(-1),prediction,rownames=['labels'],colnames=['prediction'])
(7)补充:模型保存和加载
原因:每次重新启动之前的训练就白费了
在训练之前
# 训练前
try:
model.load_weights('SaveModel/cifarCnnModel.h5')
print('加载模型成功!继续训练模型')
except:
print('加载模型失败!开始训练一个新模型')
在训练之后
# 保存训练信息
model.save_weights('SaveModel/cifarCnnModel.h5')
print('Saved model to disk')