【Deep Learning】SPP-Net
这篇是R-CNN系列的第二篇,主要是对之前的R-CNN进行了加速并改进,提出了 空间金字塔池化(Spatial Pyramid Pooling)进行特征提取,通过加入 SPP Layer,使得整个网络能够适应任意大小(arbitrary size)的图片作为输入。
1.综述
在RCNN中,我们知道,需要为每个region proposal进行一次卷积特征提取,也就是说,每张图片通过 SS 方法提取出来的约 2k 个 region 都需要进行一次特征提取过程。这会导致耗费大量的时间,而SPP-Net通过在RCNN 中引入SPP-Layer成功的解决了这个问题,其中,SPP 指的是空间金字塔池化(Spatial Pyramid Pooling),并且将其加在CNN中最后一个卷积层之后,是前几层卷积对于任意size和scale的图片经过这一层后都能产生相同长度的特征再送到后面的全连接层。
2.整体框架
首先给出一幅图:

我们可以看到,SPP-Net与之前的目标检测网络相比,整体流程上大致有两个不同。
- 它不需要输入图像进行裁剪。
- 在全部的卷积层提取特征之后,它代替了最后一个池化层,得到固定的输出后直接送到后面的全连接层。
在介绍SPP-Net 流程之前,首先再看一下 RCNN 的算法流程:
1.首先使用大的数据集训练CNN网络模型。注意这些训练是不包括bounding box的,只有具体的类别。
2.通过region proposal 在每张图像上获得大约 2k 个与类别无关的区域候选。这里RCNN作者使用的是 selective search。
3.将CNN模型最后的 softmax 层分类结果改为我们目标检测所需要的分类结果数目,注意加上一类为背景区域。
4.将 2k 个区域候选按照 IoU的值进行分类,其中 IoU<0.5 的区域当做背景,反之则分到相应的类别中。这里需要注意因为 CNN 要求固定大小的图像作为输入,因此需要将每一个区域候选 resize 到227*227。然后将学习率设置为0.001(为进行CNN训练的1/10),这是为了避免微调对网络模型产生较大的更改。
5.进行微调,每次进行 SGD 的时候,作者使用 32 个正样本(IoU>0.5) 和 96 个负样本(因为正样本实在是太少了)。这样通过CNN 就能得到 Region proposal 的特征了。同时,这里所有的分类共享的是同一个卷积s神经网络,因此计算上的开销也就比较小。
6. 拿到 CNN 提取到的特征后需要为每一类训练一个 SVM 分类器用以筛选这个东西是前景还是背景。需要注意的是,对于 SVM 的训练,作者将 IoU <0.3 的样本当做负样本,正样本则定义为 ground-truth bounding-box。使用的方法是 standard hard negative mining converges.
7. 通过 SVM 判断后,同一类别可能会产生很多的区域,这时候就需要进行区域合并了。作者提出,首先通过 SVM 的结果对每个区域候选进行打分,然后根据打分的结果对于同一类使用 greedy non-maximum suppression 算法进行区域的合并。
从上面的流程中我们可以看到,在 R-CNN中,对于每一个 region proposal来说,都需要进行三个步骤:
- resize 到 227*227
- 放到 CNN 中进行训练,并提取特征
- 进行 SVM 类别判断
因此会比较耗时,因此 SPP-Net 对网络的改动如下所示:

对于任意 size 的一张图片,只进行一次 CNN 特征提取,从而生成一个feature map。对于每一个 region proposal 直接在 feature map 的相应位置上进行 spp 生成一个固定大小的特征向量传递给全连接层。
因此,我们会面临 2个 问题,
- 如何从原图像中的 region proposal 映射到 最后一个卷积层产生的 feature map 上?
- 对于size和 scale 都不同的 feature map 上的区域,如何产生固定大小的特征向量呢?
下面来分别介绍这两部分内容。
3. region proposal -> feature map
这部分主要介绍如何从原图上的 region proposal 映射到 feature map 上的相应区域。
首先给出在这片 paper 中的一句原话:
Given a window in the image domain, we project the left (top) boundary by: x’ = [x/S] + 1 and the right (bottom) boundary x’ = [x/S] - 1 . If the padding is not [p/2], we need to add a proper offset to x.
也就是说, SPP-Net 通过角点尽量将图像像素映射到 feature map 感受野的中央区域,假设每一层的 padding 都是 p/2,其中 p 为卷积核的大小。对于 feature map 的一个像素(x’, y’),它的实际感受野为:(Sx’,Sy’),其中 S 是之前所有层的 stride 的乘积,然后对于 region proposal的位置来说,我们直接获取左上角和右下角两个点对应的 feature map 的位置,然后取出特征就好了。因此,左上角映射为:
至于这个 padding 取值的问题,我们知道padding是用来补偿卷积所缩小的区域的。下面给出对于某一层卷积或者池化,假设输入进来的特征图的大小是 w*h, 那么输出的特征图设为w’ * h’,则有下面关系:
在 paper 中对于 padding有下面这句话:
To simplify the implementation, during deployment we pad ⌊p/2⌋ pixels for a layer with a filter size of p.
至于为什么设置 padding = ⌊p/2⌋ 是会使得实施过程比较简单,这是因为,在输入这层的 image 或 feature map 边缘上分别增加 ⌊p/2⌋ 这么多的像素,通过设置stride(stride=1),可以使得输入与输出的size相同。反过来想,如果我们控制了padding这个变量使得输出的size与其没有关系,那么只需要已知 stride 的值,即可快速的计算出 输入与输出的关系。这样我们便得到了上面有关于左上角和右下角的转换公式。也就是说,每个层的stride值,就代表了这个层对于输入的 image(feature map)的缩放程度,在这里,它就是图像的缩放因子。
4. SPP Layer
这里只介绍SPP-Net 针对检测任务的情况,下面说明为什么在RCNN网络中加入使用 SPP Layer 代替最后一个最大池化层能使网络可以接收任意 size and scala 的图像。
首先介绍一下空间金字塔,在图像检测里主要是指对 image(feature map)以大小不同的块来对图片进行特征提取,使用论文中的图:
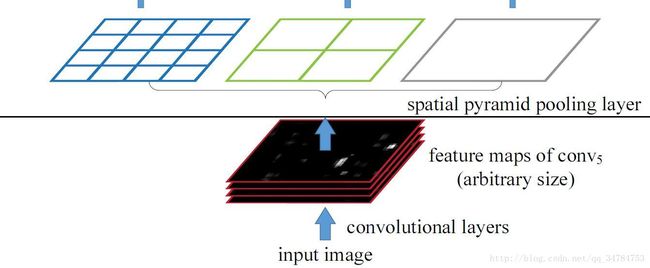
可以看到,文中分别使用 4*4,2x2 和 1x1 大小的块,将这三张网格放在下面这张 feature map 上,就可以得到 16+4+1=21中不同的分割快,我们再对每一个分割块执行1x1xblock_size 大小的最大池化,其中 block_size 指的是每一个小块的size,这样我们将得到一个21个256维的固定长度的特征向量,其中 21 表示空间盒的数量,而 256 则表示经过最后一个卷积层后卷积核的数量。
这样,我们将 SPP-Layer 加入到 RCNN 的框架中,也就得到了我们所说的 SPP-Net 目标检测网络。大体流程如下:
- 首先通过选择性搜索,使用 SS 方法对待检测的图片进行 region proposal,这一步和 R-CNN 完全相同。
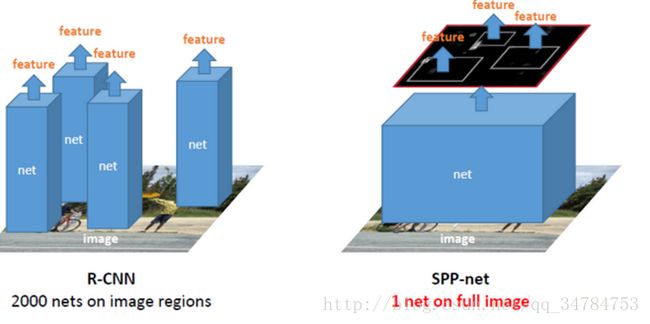
- 在特征提取阶段,这也是和 R-CNN 最大的不同之处。在 SPP-Layer 之前,与 R-CNN的结构相同,都是使用卷积神经网络进行特征提取,但是提取之后 SPP-Net 使用的是金字塔池化而非直接使用最大池化。具体步骤为:①把整张待检测的图片,输入到 CNN 中,进行一次性特征提取,得到 feature maps;②在feature maps中找到各个候选框的区域,在对各个候选框采用空间金字塔池化,提取出固定长度的特征向量。在这一步中,R-CNN 输入的是每个候选框,然后再进入 CNN,因为SPP-Net只需要一次对整张图片进行特征提取,然后找到每个候选框的位置及代表的特征向量,因此速度会有很大的提升。这也就是说, SPP-Net 每遍历张image,就相当于 R-CNN 遍历2000次。
- 之后的步骤也是和 R-CNN 相同,采用 SVM 进行特征向量的分类识别。
5.其他细节
- 在训练过程中,我们要训练得到多尺寸识别网络用来提取区域特征,其中的处理方法是每个尺寸的最短边大小在下面的尺寸集合中:
s∈S={480,576,688,864,1200}训练的时候通过上面提到的多尺寸训练的方法,也就是在每个 epoch 中首先训练一个尺寸产生一个 model,然后加载这个model 并训练第二个尺寸,知道训练完所有的尺寸。这时空间金字塔池化使用的尺度为:1x1,2x2,3x3,6x6 一共是50个bins。(PS,这个 bins,我的理解就是空间块)
- 作者为了表示网络能够接受任意尺度的输入,同时进行了多尺度训练。分别为(180*180 224*224),这两个size仅仅是通过放缩变化,内部没有任何差异。同时spp的windows_size、stride_size不同,其他网络参数都一致。
文中使用的算法是:在一个epoch中先训练其中一种size的网络,然后在下一个epoch中训练另外一个size的网络。由于这两个size的所有参数都一致,因此可以进行交替训练。作者发现,进行多尺度训练的时候,收敛速度和一个size的收敛速度差不多。 - 在测试过程中,每个 region proposal 选择能够使其包含的像素个数最接近的 224*224的尺寸,然后再提取相应的侧正。
- 因为 SPP 可以接收任意大小的输入,因此对于每个 region proposal 将它映射到 feature map 上,然后紧紧对这一块 feature map 进行 SPP 就可以得到固定唯独的特征用来训练 CNN 了。
- 使用SS 方法给出 region proposal 后,我们记下这大约 2000 个候选框的位置信息(左上角和右下角)。目的是用来映射到feature map 上的不同区域。
6.优缺点
优点:
- Can generate a fixed-length representation regardless of image scale/size
- SPP uses multi-level spatial bins;
- SPP can pool features extracted at variable scales thanks to the flexibility of input scales
个人觉得, SPP-Net 最大的优点有两个,一个是使加入 SPP-Net 的网络能够接受任意size的图像进行处理。而是因为每张图片的所有 region proposals 都一次提取到相应特征,从而与之前的 R-CNN 先比,大大增加了速度。
缺点:
- 网络的每一部分还是需要单独进行训练,并不是一个 end-to-end 的网络。且 region proposal 也不在网络内部。
- 检测速度还是达不到应用水准
- 特征提取后还是需要保存到本地,占用大量的本地存储空间。
7.参考文章
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- RCNN(二)SPP-NET:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
- RCNN学习笔记(3):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPP-net)
- 如何理解Spp-Net以及Fast R-CNN中将原图像ROI映射到Feature map上的机制
- 目标检测(3)-SPPNet