结构重参数化之三:Diverse Branch Block
paper: Diverse Branch Block: Building a Convolution as an Inception-like Unit
code: https://github.com/DingXiaoH/DiverseBranchBlock
前言
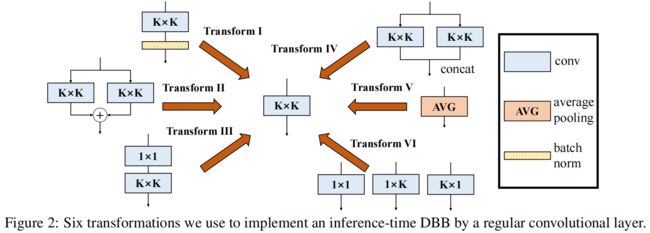
有了前两篇文章ACNet和RepVGG的铺垫,本文就忽略背景介绍,直接进入核心内容的讲解。本文首先总结了六种不同的结构重参数化的转换方法,然后借鉴Inception的多分支结构提出了一种新的building block:Diverse Branch Block(DBB),在训练阶段,对模型中的任意一个 \(K\times K\) 卷积,都可以用DBB替换,由于DBB引入了不同感受野、不同复杂度的多分支结构,可以显著提升原有模型的精度。在推理阶段,通过这六种结构重参数转换方法,可以将DBB等价地再转换成一个 \(K\times K\) 卷积,这样就可以在模型结构、计算量、推理时间都不变的前提下无损涨点。六种转换方法如下:
Six transformations
TransformⅠ: a conv for conv-BN
这一转换在前两篇文章中都讲过了,就是将卷积和紧跟着的BN融合转换成一个新的卷积。对于输入 \(I\) 经过卷积 \(F\) 和BN后的输出 \(O\) 的第 \(j\) 个通道可根据下式得到
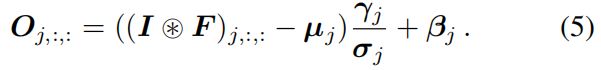
将卷积和BN融合后得到新的卷积核 \(F'\) 和偏置 \(b'\),\(F'\) 和 \(b'\) 的第 \(j\) 个通道可根据下式得到
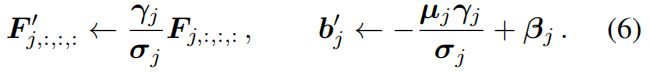
Transform Ⅱ: a conv for branch addition
这一转换在前两篇文章中也讲过了,具体就是对于同一个输入,如果要将多个并行的相同规格的卷积分支的结果相加,可以先将多个卷积核进行相加融合成一个卷积核,然后对输入进行卷积得到的结果是相同的。这里相同规格指的是kernel size、padding、stride都相同。因为通常卷积后面都会接BN层,因此需要先进行Transform Ⅰ,再进行这一步。
![]()
Transform Ⅲ: a conv for sequential convolutions
这是本文新提出的一种转换类型同时也是最复杂的一种。这一转换是将连续的1x1 conv - BN - KxK conv - BN转换成一个单个的 K x K conv。具体如下,这里不考虑组卷积,即groups=1,假设 \(1\times 1\) 卷积和 \(K\times K\) 卷积的shape分别为 \(D\times C\times 1\times 1\) 和 \(E\times D\times K\times K\),首先把两个BN分别和两个卷积合并得到 \(F^{(1)}\in \mathbb{R}^{D\times C\times 1\times 1}\),\(b^{(1)}\in \mathbb{R}^{D}\),\(F^{(2)}\in \mathbb{R}^{E\times D\times K\times K}\),\(b^{(2)}\in \mathbb{R}^{E}\),输出如下
![]()
我们希望最终得到的是一个卷积,\(F'\) 和 \(b'\) 满足下式
![]()
式(8)展开得到下式
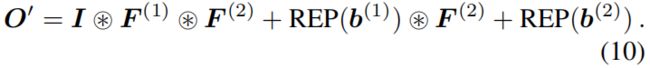
因为 \(I\circledast F^{(1)}\) 是 \(1\times 1\) 卷积,只进行通道间的线性组合操作而没有空间上的相加操作,因此可以通过线性重组 \(K\times K\) 卷积核中的参数将其合并到 \(K\times K\) 卷积核中,具体如下
![]()
其中 \(TRANS(F^{(1)})\in \mathbb{R}^{C\times D\times 1\times 1}\) 是 \(F^{(1)}\) 前两个维度的转置。
式(10)中的第二项是对常数矩阵进行卷积结果也是一个常数矩阵,假设 \(P\in \mathbb{R}^{H\times W}\) 是一个常数矩阵其中每个值都等于 \(p\),\(*\) 是二维卷积,\(W\) 是二维卷积核,则结果是一个与 \(p\) 以及卷积核中所有元素的和成比例的常数矩阵,如下
![]()
基于此,我们按下式构建 \(\hat b\)
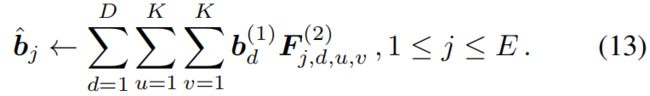
接着很容易验证
![]()
然后我们就得到
![]()
注意,假设 \(K\times K\) 卷积对输入的padding不为0,则式(8)是不成立的,解决方法是在训练阶段对BN1的结果pad一圈 \(b^{(1)}\)。
Transform Ⅳ: a conv for depth concatenation
Inception中是通过沿通道拼接的方式来融合多个分支的结果,当多个分支都只含有一个卷积层且规格相同的情况下,对多个分支的结果沿通道拼接等价于将每个分支的卷积核沿输出通道维度进行拼接,这里的输出维度就是每个卷积层的卷积核个数。例如对于 \(F^{(1)}\in \mathbb{R}^{D_{1}\times C\times K\times K}\),\(b^{(1)}\in \mathbb{R}^{D_{1}}\),\(F^{(2)}\in \mathbb{R}^{D_{2}\times C\times K\times K}\),\(b^{(2)}\in \mathbb{R}^{D_{2}}\),我们沿输出通道维度拼接得到 \(F'\in \mathbb{R}^{(D_{1}+D_{2})\times C\times K\times K}\),\(b'\in \mathbb{R}^{D_{1}+D_{2}}\),显然有
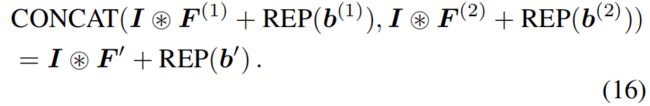
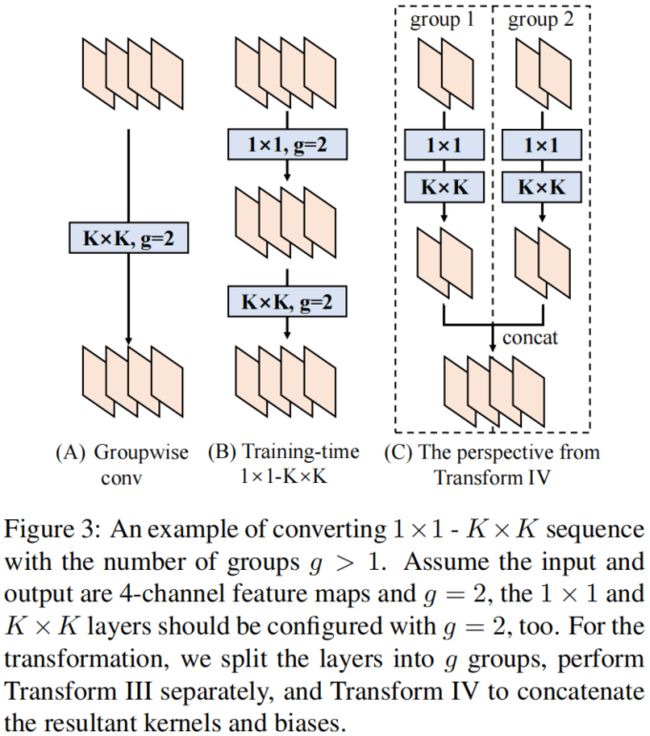
这一转换对于将Transform Ⅲ推广到组卷积时非常有用,组卷积可以看作将输入等分成 \(g\) 组,然后每组分别进行卷积,再将结果拼接起来。因此通过Transform Ⅲ将每组的 1x1 conv - BN - KxK conv - BN 转换成单个卷积,然后再通过Transform Ⅳ将所有组的卷积拼接成一个卷积。如下图所示
Transform Ⅴ: a conv for average pooling
一个kernel size为 \(K\) 步长为 \(s\) 输入通道为 \(C\) 的平均池化,可以等价为一个大小和步长相等的卷积 \(F'\in \mathbb{R}^{C\times C\times K\times K}\)
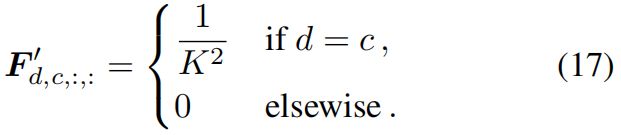
Transform Ⅵ: a conv for multi-scale convolutions
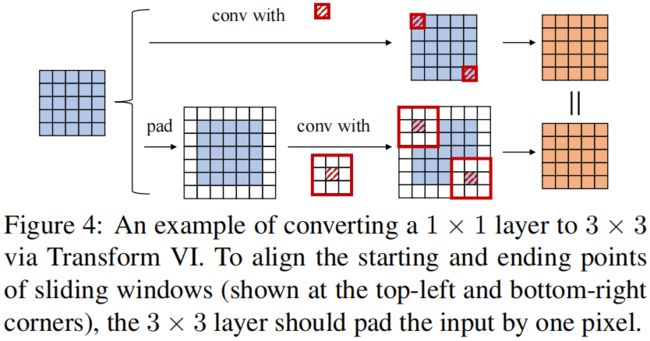
这一转换最开始在ACNet中就提出了,我们可将一个 \(k_{h}\times k_{w} (k_{h}\leq K,k_{w}\leq K)\) 的卷积通过zero-padding转换成一个 \(K\times K\) 卷积,比如在ACNet中,将 \(1\times 3\) 和 \(3\times 1\) 卷积等价转换成 \(3\times 3\) 卷积。这里要注意滑动窗口对应的位置要对齐,即要考虑 \(K\times K\) 对输入做的padding。如下所示
六种转换总结如下
A Diverse Branch Block(DBB)
一个完整的DBB block如下图所示,其中包含四个分支,通过上述六种转换,在推理阶段可以将其等价转换为一个卷积,因此对于任意现有的网络如ResNet等,在训练阶段可以将其中的 \(3\times 3\) 卷积替换成DBB block,推理阶段再转换回去,达到无损涨点的目的。
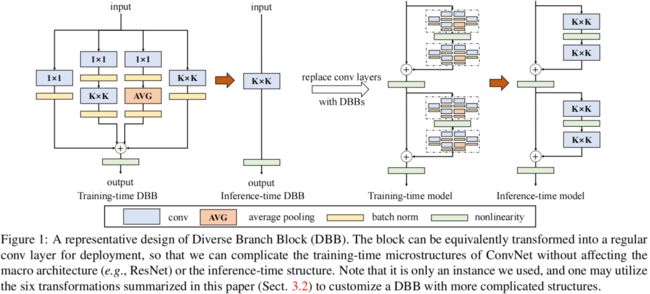
其中 \(1\times 1-K\times K\) 分支的中间输出通道与输入通道数相等,注意这个分支中的 \(1\times 1\) 卷积初始化为1,其它的卷积都采用默认初始化方法。每个卷积和池化层后就接一个BN层,后面的实验也提到训练阶段BN提供的非线性变换对结果的提升非常有帮助。对于深度可分离卷积的DBB,作者移除了 \(1\times 1\) 分支和 \(1\times 1-AVG\) 分支中的 \(1\times 1\) 卷积,因为depthwise \(1\times 1\) 卷积就是一个线性缩放。
实验结果

代码
训练阶段
其中 IdentityBasedConv1x1是 1 x 1 - K x K 分支中1 x 1 卷积,单独写成类是因为初始化为全1矩阵,和其它的卷积区分开。BNAndPadLayer是1 x 1 - K x K 和1 x 1 - AVG 分支中对1 x 1-BN的结果padding一层 \(b^{(1)}\),在Transform Ⅲ中的提到如果不进行这一步,式(8)就无法展开。if groups < out_channels:这里包括groups=1和groups>1两种情况,else:即是groups==out_channels的情况,此时的卷积就是深度可分离卷积,这种情况如上述移除 1 x 1分支以及 1 x 1 - avg 分支中的 1 x 1 卷积。
import torch
import torch.nn as nn
import torch.nn.functional as F
from dbb_transforms import *
def conv_bn(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,
padding_mode='zeros'):
conv_layer = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=groups,
bias=False, padding_mode=padding_mode)
bn_layer = nn.BatchNorm2d(num_features=out_channels, affine=True)
se = nn.Sequential()
se.add_module('conv', conv_layer)
se.add_module('bn', bn_layer)
return se
class IdentityBasedConv1x1(nn.Conv2d):
def __init__(self, channels, groups=1):
super(IdentityBasedConv1x1, self).__init__(in_channels=channels, out_channels=channels, kernel_size=1, stride=1,
padding=0, groups=groups, bias=False)
assert channels % groups == 0
input_dim = channels // groups
id_value = np.zeros((channels, input_dim, 1, 1))
for i in range(channels):
id_value[i, i % input_dim, 0, 0] = 1
self.id_tensor = torch.from_numpy(id_value).type_as(self.weight)
nn.init.zeros_(self.weight)
def forward(self, input):
kernel = self.weight + self.id_tensor.to(self.weight.device)
result = F.conv2d(input, kernel, None, stride=1, padding=0, dilation=self.dilation, groups=self.groups)
return result
def get_actual_kernel(self):
return self.weight + self.id_tensor.to(self.weight.device)
class BNAndPadLayer(nn.Module):
def __init__(self,
pad_pixels,
num_features,
eps=1e-5,
momentum=0.1,
affine=True,
track_running_stats=True):
super(BNAndPadLayer, self).__init__()
self.bn = nn.BatchNorm2d(num_features, eps, momentum, affine, track_running_stats)
self.pad_pixels = pad_pixels
def forward(self, input):
output = self.bn(input)
if self.pad_pixels > 0:
if self.bn.affine:
pad_values = self.bn.bias.detach() - self.bn.running_mean * self.bn.weight.detach() / torch.sqrt(
self.bn.running_var + self.bn.eps)
else:
pad_values = - self.bn.running_mean / torch.sqrt(self.bn.running_var + self.bn.eps)
output = F.pad(output, [self.pad_pixels] * 4)
pad_values = pad_values.view(1, -1, 1, 1)
output[:, :, 0:self.pad_pixels, :] = pad_values
output[:, :, -self.pad_pixels:, :] = pad_values
output[:, :, :, 0:self.pad_pixels] = pad_values
output[:, :, :, -self.pad_pixels:] = pad_values
return output
@property
def weight(self):
return self.bn.weight
@property
def bias(self):
return self.bn.bias
@property
def running_mean(self):
return self.bn.running_mean
@property
def running_var(self):
return self.bn.running_var
@property
def eps(self):
return self.bn.eps
class DiverseBranchBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, groups=1,
internal_channels_1x1_3x3=None,
deploy=False, nonlinear=None, single_init=False):
super(DiverseBranchBlock, self).__init__()
self.deploy = deploy
if nonlinear is None:
self.nonlinear = nn.Identity()
else:
self.nonlinear = nonlinear
self.kernel_size = kernel_size
self.out_channels = out_channels
self.groups = groups
assert padding == kernel_size // 2
self.dbb_origin = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size,
stride=stride, padding=padding, dilation=dilation, groups=groups)
self.dbb_avg = nn.Sequential()
if groups < out_channels:
self.dbb_avg.add_module('conv',
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1,
stride=1, padding=0, groups=groups, bias=False))
self.dbb_avg.add_module('bn', BNAndPadLayer(pad_pixels=padding, num_features=out_channels))
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=0))
self.dbb_1x1 = conv_bn(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=stride,
padding=0, groups=groups)
else:
self.dbb_avg.add_module('avg', nn.AvgPool2d(kernel_size=kernel_size, stride=stride, padding=padding))
self.dbb_avg.add_module('avgbn', nn.BatchNorm2d(out_channels))
if internal_channels_1x1_3x3 is None:
internal_channels_1x1_3x3 = in_channels if groups < out_channels else 2 * in_channels # For mobilenet, it is better to have 2X internal channels
self.dbb_1x1_kxk = nn.Sequential()
if internal_channels_1x1_3x3 == in_channels:
self.dbb_1x1_kxk.add_module('idconv1', IdentityBasedConv1x1(channels=in_channels, groups=groups))
else:
self.dbb_1x1_kxk.add_module('conv1',
nn.Conv2d(in_channels=in_channels, out_channels=internal_channels_1x1_3x3,
kernel_size=1, stride=1, padding=0, groups=groups, bias=False))
self.dbb_1x1_kxk.add_module('bn1', BNAndPadLayer(pad_pixels=padding, num_features=internal_channels_1x1_3x3,
affine=True))
self.dbb_1x1_kxk.add_module('conv2',
nn.Conv2d(in_channels=internal_channels_1x1_3x3, out_channels=out_channels,
kernel_size=kernel_size, stride=stride, padding=0, groups=groups,
bias=False))
self.dbb_1x1_kxk.add_module('bn2', nn.BatchNorm2d(out_channels))
def forward(self, inputs):
if hasattr(self, 'dbb_reparam'):
return self.nonlinear(self.dbb_reparam(inputs))
out = self.dbb_origin(inputs)
if hasattr(self, 'dbb_1x1'):
out += self.dbb_1x1(inputs)
out += self.dbb_avg(inputs)
out += self.dbb_1x1_kxk(inputs)
return self.nonlinear(out)
推理阶段
import torch
import numpy as np
import torch.nn.functional as F
def transI_fusebn(kernel, bn):
gamma = bn.weight
std = (bn.running_var + bn.eps).sqrt()
return kernel * ((gamma / std).reshape(-1, 1, 1, 1)), bn.bias - bn.running_mean * gamma / std
def transII_addbranch(kernels, biases):
return sum(kernels), sum(biases)
def transIII_1x1_kxk(k1, b1, k2, b2, groups):
if groups == 1:
k = F.conv2d(k2, k1.permute(1, 0, 2, 3))
b_hat = (k2 * b1.reshape(1, -1, 1, 1)).sum((1, 2, 3))
else:
k_slices = []
b_slices = []
k1_T = k1.permute(1, 0, 2, 3)
k1_group_width = k1.size(0) // groups
k2_group_width = k2.size(0) // groups
for g in range(groups):
k1_T_slice = k1_T[:, g * k1_group_width:(g + 1) * k1_group_width, :, :]
k2_slice = k2[g * k2_group_width:(g + 1) * k2_group_width, :, :, :]
k_slices.append(F.conv2d(k2_slice, k1_T_slice))
b_slices.append(
(k2_slice * b1[g * k1_group_width:(g + 1) * k1_group_width].reshape(1, -1, 1, 1)).sum((1, 2, 3)))
k, b_hat = transIV_depthconcat(k_slices, b_slices)
return k, b_hat + b2
def transIV_depthconcat(kernels, biases):
return torch.cat(kernels, dim=0), torch.cat(biases)
def transV_avg(channels, kernel_size, groups):
input_dim = channels // groups
k = torch.zeros((channels, input_dim, kernel_size, kernel_size))
k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2
return k
# This has not been tested with non-square kernels (kernel.size(2) != kernel.size(3)) nor even-size kernels
def transVI_multiscale(kernel, target_kernel_size):
H_pixels_to_pad = (target_kernel_size - kernel.size(2)) // 2
W_pixels_to_pad = (target_kernel_size - kernel.size(3)) // 2
return F.pad(kernel, [H_pixels_to_pad, H_pixels_to_pad, W_pixels_to_pad, W_pixels_to_pad])
def get_equivalent_kernel_bias(self):
k_origin, b_origin = transI_fusebn(self.dbb_origin.conv.weight, self.dbb_origin.bn)
if hasattr(self, 'dbb_1x1'):
k_1x1, b_1x1 = transI_fusebn(self.dbb_1x1.conv.weight, self.dbb_1x1.bn)
k_1x1 = transVI_multiscale(k_1x1, self.kernel_size)
else:
k_1x1, b_1x1 = 0, 0
if hasattr(self.dbb_1x1_kxk, 'idconv1'):
k_1x1_kxk_first = self.dbb_1x1_kxk.idconv1.get_actual_kernel()
else:
k_1x1_kxk_first = self.dbb_1x1_kxk.conv1.weight
k_1x1_kxk_first, b_1x1_kxk_first = transI_fusebn(k_1x1_kxk_first, self.dbb_1x1_kxk.bn1)
k_1x1_kxk_second, b_1x1_kxk_second = transI_fusebn(self.dbb_1x1_kxk.conv2.weight, self.dbb_1x1_kxk.bn2)
k_1x1_kxk_merged, b_1x1_kxk_merged = transIII_1x1_kxk(k_1x1_kxk_first, b_1x1_kxk_first, k_1x1_kxk_second,
b_1x1_kxk_second, groups=self.groups)
k_avg = transV_avg(self.out_channels, self.kernel_size, self.groups)
k_1x1_avg_second, b_1x1_avg_second = transI_fusebn(k_avg.to(self.dbb_avg.avgbn.weight.device),
self.dbb_avg.avgbn)
if hasattr(self.dbb_avg, 'conv'):
k_1x1_avg_first, b_1x1_avg_first = transI_fusebn(self.dbb_avg.conv.weight, self.dbb_avg.bn)
k_1x1_avg_merged, b_1x1_avg_merged = transIII_1x1_kxk(k_1x1_avg_first, b_1x1_avg_first, k_1x1_avg_second,
b_1x1_avg_second, groups=self.groups)
else:
k_1x1_avg_merged, b_1x1_avg_merged = k_1x1_avg_second, b_1x1_avg_second
return transII_addbranch((k_origin, k_1x1, k_1x1_kxk_merged, k_1x1_avg_merged),
(b_origin, b_1x1, b_1x1_kxk_merged, b_1x1_avg_merged))