使用DSGN++训练自己的数据集
自己采集的数据
由于图像是:RGB+灰度双目图像,所以涉及到通道个数不匹配问题等等,从头到尾凭记忆记录一下:
1.修改config\dsgn.yaml文件
把验证集换为测试集,这样就可以运行test.py时生成的是test文件夹下的结果(多此一举是因为我的数据集没有label,而test数据集不需要label)
DATA_CONFIG:
_BASE_CONFIG_: ./configs/stereo/dataset_configs/kitti_dataset_fused.yaml
later_flip: True
DATA_SPLIT: {
'train': train,
'test': test # val
}
INFO_PATH: {
'train': [kitti_infos_train.pkl],
'test': [kitti_infos_test.pkl], # kitti_infos_val.pkl
}
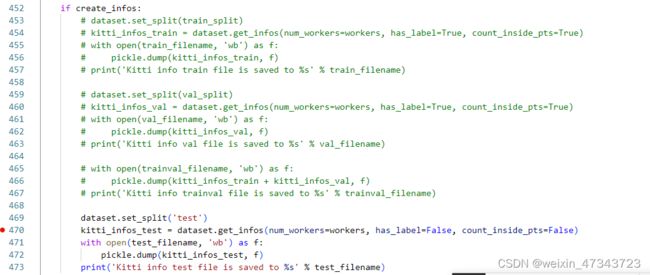
2.生成kitti_infos_test.pkl文件
这里由于数据集没有label需要注释掉一部分代码,在dataset/kitti/lidar_kitti_dataset.py文件中注释掉453~467行,只保留生成test部分
python -m pcdet.datasets.kitti.lidar_kitti_dataset create_kitti_infos
再记录两个没睡醒干的蠢事: 再次修改数据集时
(1)记得修改ImageSet里的.txt文件
(2)Vsocode记得要手动保存再运行
3.由于灰度图像通道问题,修改pcdet/datasets/stereo_dataset_template.py文件

4.运行test.py
这里提一下数据预处理: 重命名文件(python)、copy内参calib文件(python)、图像剪裁(matlab)
问题: 测试结果没有3Dbox,或者乱七八糟
主要原因: 内参对不上
这几天因为Kitti的相机内参没搞懂一直没有进展,知道今天终于明白了投影矩阵里所有参数的含义,我就不理解了为什么不能直说,弯弯绕绕又给出一堆链接简直在折磨人!
如果以双目图像作为输入,还需要知道相机内参,其余的东西统统复制kitti的不影响(指点云),只要能保证.pkl文件正常生成就行,测试过程并不会用到这些,此外,对于calib文件中的各个参数,经过试验可以得出如下结论:
P0: 0号相机投影矩阵 用不到
P1: 1号相机投影矩阵 用不到
P2: 2号相机投影矩阵 直接影响结果
P3: 3号相机投影矩阵 直接影响结果
R0_rect: 改为单位矩阵就好,会被归入计算,但是不用管
Tr_velo_to_cam: 会被归入计算,但是值不影响结果
Tr_imu_to_velo: 未测试,不用管
综上所示,P2和P3的数值非常重要,这里的直接影响结果指的是检测精度、检测框位置统统影响!
好的,那么我们详细来看一下原因,由kitti论文可知投影矩阵P的表示形式如下(左),右侧是P3的真实值,明显最后一列两个元素是对不上的,但是论文根本没提!!!当然了,你也可以这么想,最后两个元素近似为0,这样不就对上了。

翻阅各大资料终于找到了一个靠谱的表示方式:
P(i)rect = [[fu 0 cx -fu*bx],
[0 fv cy -fv*by],
[0 0 1 0 ]]
b是相机的基线,简单来说就是两个相机的实际距离(以米为单位)。这里就不得不来看看kitii的相机摆放图片:

整个坐标系均以0号相机为参考进行建立和转换,所以C1,C2,C3距离C0分别是0.54,0.06,0.48m。所以fubx的值分别是389.62,43.29,346.33,可以看到跟文件里的很接近了,应该是距离不够精确导致不完全一样。此外另一需要注意的点是正负号,在C0以下的为正数,C0以上为负数,这与y轴的朝向有关。至于其他坐标的数值为0的原因是:所有的相机都被设置在同一水平线上,所以by约等于0,到此相机的参内全部get!撒花花~~
那么接下来为了满足我的好奇心,我就来测试一下:
实验问题: 若没有0号相机为参考,这些数值怎么设置?
实验验证: 以2号相机为原点,设置3号相机的参数,通过计算可知第四行最后一列是-384.3815,(此处记得把P2对应改成0)改变参数后运行test.py预测结果,发现完全一致;若是随便改,那就完全乱七八糟甚至没有。
结论: 与预期一致。
于是乎 在自己数据集上进行验证,这里对数据集里的图像进行了剪裁,因此相应的cucv也需要变换。
预处理:
1.crop:f不变c变
2. resize:f和c都要除以相应倍率
结论: resize后的图像比crop准确率高得多
待解决
1.原图尺寸不能使用
。。。
waymo数据集
介绍
今天在看waymo数据集的时候突然发现也有灰度相机,回想了一下kitti也是灰度相机,莫非…双目相机大部分都不是全彩色?(waymo数据集需要自己去了解+下载)关于如何使用DSGN++测试waymo数据集,我大致有两个思路:
- 直接利用OpenPCDet里读取数据集的方法,生成waymo数据集下的.pkl文件,修改.yaml中数据集路径。
- 把tfrecord中的数据全部读取出来,包括label、lidar、calib、image等,像kitti一样进行组织,再生成.pkl文件。
尝试了方法一,发现DSGN++还是少了很多OpenPCDet的文件,虽然添加了之后也能成功生成.pkl,但是暂时还没办法正常test,毕竟不了解.pkl文件里的内容,不敢贸然尝试,于是采取了思路2,具体操作如下:此处发现了一个很好用的waymo转kitti代码(链接),我真是何其幸运,下面将介绍如何配置转换的安装环境:
创建3.6环境,因为代码是很早以前的,现在的waymo已经支持tensorflow2,所以跟这个代码存在不兼容的问题等,所以以下就按照我的步骤来:
conda create -n tensorflow1.14 python=3.6
source activate tensorflow1.14
pip install tensorflow==1.14.0 -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com module_name
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy==1.16.0
安装完成后可以使用Python测试一下
import tensorflow as tf
hello = tf.constant('hello, tensorf')
sess = tf.Session()
print(sess.run(hello))
接着安装其他依赖
pip install cv2
pip install opencv-python
pip install matplotlib
pip install progressbar
接着按照github链接的操作步骤复制文件:下载waymo代码,复制 protocol buffer folder到waymo open dataset folder下,复制adapter.py to waymo-od folder下,打开adapter.py并修改两个路径,即:DATA_PATH(waymo路径——waymo存储路径)和KITTI_PATH(kitt路径——你要生成的文件路径)。这时运行adapter.py还会产生一个错误:ImportError: cannot import name 'dataset_pb2'。这是因为缺少了文件,参考链接,复制两个文件到对应文件夹下。
# 以下命令行也在解决上面报错的时候运行了,似乎无效
pip3 install waymo-open-dataset==1.0.1
运行adapter.py文件,就可以在KITTI_PATH生成对应的文件,展示结果(这里不用自己建立文件夹,我傻乎乎的还建了好多文件夹):

本着资料不嫌多的原则,放一个waymo数据集详细介绍的链接(https://colab.research.google.com/github/waymo-research/waymo-open-dataset/blob/master/tutorial/tutorial.ipynb#scrollTo=18KfxT8RkMv0)
可视化:(之后补充)
测试
从生成到测试拖拖拉拉了两天,一直不敢开始,除了怕麻烦最大的原因还是怕失败吧(虽然是必然的)。
1.生成.pkl文件(方法同上)
不同之处在于要修改以下内容:
dataset/kitti/lidar_kitti_dataset.py文件中,71行替换图片格式
img_file = self.root_split_path / 'image_2' / ('%s.jpg' % idx)
接着,重命名image文件或者test.txt里的内容。
写到这里我突然意识到一个问题,那就是这是个双目深度估计方法,而waymo数据集是一个多视图数据集,这就尴尬了呀,一个思路是从多角度视图估计深度,再使用DSGN++,emmmm所以waymo暂时还不能测试。